Stefaan Verhulst
Christopher Moraff at Next City: “…despite the fact that policing is arguably one of the most important and powerful service professions a civilized society can produce, it’s far easier to find out if the plumber you just hired broke someone’s pipe while fixing their toilet than it is to find out if the cop patrolling your neighborhood broke someone’s head while arresting them.
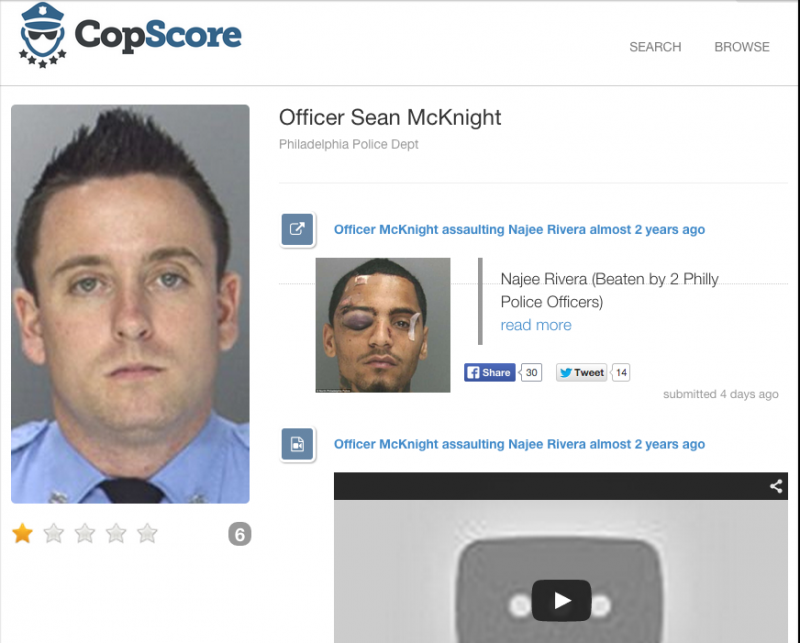
A 31-year-old computer programmer has set out to fix that glitch with a new web-based (and soon to be mobile) crowdsourced rating tool called CopScore that is designed to help communities distinguish police officers who are worthy of praise from those who are not fit to wear the uniform….
CopScore is a work in progress, and, for the time being at least, a one-man show. Hardison does all the coding himself, often working through the night to bring new features online.
Currently in the very early beta stage, the platform works by consolidating information on the service records of individual police officers together with details of their interactions with constituents. The searchable platform includes data gleaned from public sources — such as social media and news articles — cross-referenced with Yelp-style ratings from citizens.
For Hardison, CopScore is as much a personal endeavor as it is a professional one. He says his youthful interest in computer programming — which he took up as a misbehaving fifth-grader under the guiding hand of a concerned teacher — made him the butt of the occassional joke in the predominantly African-American community of North Nashville where he grew up….”(More)
Katie Collins at WIRED: “Microsoft researcher Kati London’s aim is “to try to get people to think of data in terms of personalities, relationships and emotions”, she tells the audience at the Story Festival in London. Through Project Sentient Data, she uses her background in games development to create fun but meaningful experiences that bridge online interactions and things that are happening in the real world.
One such experience invited children to play against the real-time flow of London traffic through an online game called the Code of Everand. The aim was to test the road safety knowledge of 9-11 year olds and “make alertness something that kids valued”.
The core mechanic of the game was that of a normal world populated by little people, containing spirit channels that only kids could see and go through. Within these spirit channels, everything from lorries and cars from the streets became monsters. The children had to assess what kind of dangers the monsters posed and use their tools to dispel them.
“Games are great ways to blur and observe the ways people interact with real-world data,” says London.
In one of her earlier projects back in 2005, London used her knowledge of horticulture to bring artificial intelligence to plants. “Almost every workspace I go into has a half dead plant in it, so we gave plants the ability to tell us what they need.” It was, she says, an exercise in “humanising data” that led to further projects that saw her create self aware street signs and a dynamic city map that expressed shame neighbourhood by neighbourhood depending on the open dataset of public complaints in New York.
A further project turned complaint data into cartoons on Instagram every week. London praised the open data initiative in New York, but added that for people to access it, they had to know it existed and know where to find it. The cartoons were a “lightweight” form of “civic engagement” that helped to integrate hyperlocal issues into everyday conversation.
London also gamified community engagement through a project commissioned by the Knight Foundation called Macon Money….(More)”.
Hildy Gottlieb on “How “opening up” can help organizations achieve their missions” in Stanford Social Innovation Review : “…For the past two years, Creating the Future, a social change research and development laboratory, has been experimenting to find the answer to that question. In the process, we have learned that when organizations are more open in their work, it can improve both the work itself and the results in the communities they serve.
In December 2012, Creating the Future’s board voted to open all its board and strategy meetings (including meetings for branding, resource development, and programming) to anyone who wished to attend and participate.
Since our organization is global, we hold our meetings via Google Hangout, and community members participate via a dedicated Twitter hashtag. Everyone is encouraged to participate—through asking questions and sharing observations—as if they are board members, whether or not they are.
This online openness mirrors the kind of inclusive, participatory culture that many grassroots neighborhood groups have fostered in the “real world” for decades. As we’ve studied those groups and experienced open engagement for ourselves, here are some of the things we’ve learned that can apply to any organization, whether they are working at a distance or in person.
What Being Open Makes Possible
1. Being open adds new thinking to the mix. We can’t overstate this obvious practical benefit for every strategic issue an organization considers. During a recent discussion of employee “paid time off” policies, a participant with no formal relationship to the organization powerfully shifted the board’s conversation and perspectives away from the rigidity of a policy, focusing instead on the values of relationships, outcomes, buy-in, and adaptability. That input helped the board clarify its intent. It ultimately chose to scrap the idea of a certain amount of “paid time off,” in favor of an outcomes-based approach that provides flexibility for both employees and their supervisors.
2. Being open flattens internal communications. Opening all our meetings has led to cross-pollination across every aspect of our organization, providing an ongoing opportunity for sharing information and resources, and for developing everyone’s potential as leaders….
3. Being open walks the talk of the engaged communities we want to see. From the moment we opened the doors to our meetings, people have walked in and found meaningful ways to become part of our work. …
It seems so simple: If we want to engage the community, we just need to open the doors and invite people in!
4. Being open creates meaningful inclusion. Board diversity initiatives are intended to ensure that an organization’s decision-making reflects the experience of the community it serves. In reality, though, there can never be enough seats on a board to accomplish inclusion beyond what often feels like tokenism. Creating the Future’s board doesn’t have to worry about representing the community, because our community members represent themselves. And while this is powerful in an online setting, it is even more powerful when on-the-ground community members are part of a community-based organization’s decision-making fabric.
5. Being open creates more inclusive accountability. During a discussion of cash flow for our young organization, one concerned board member wondered aloud whether adhering to our values might be at cross-purposes with our survival. Our community members went wild via Twitter, expressing that it was that very code of values that drew them to the work in the first place. That reminder helped board members remove scarcity and fear from the conversation so that they could base their decision on what would align with our values and help accomplish the mission.
The needs of our community directly impacted that decision—not because of a bylaws requirement for “voting members” but simply because we encouraged community members to actively take part in the conversation….(More)”
Key Findings
- Citizens Advice (CAB) and Data Kind partnered to develop the Civic Dashboard. A tool which mines data from CAB consultations to understand emerging social issues in the UK.
- Shooting Star Chase volunteers streamlined the referral paths of how children come to be at the hospices saving up to £90,000 for children’s hospices around the country by refining the referral system.
- In a study of open grant funding data, NCVO identified 33,000 ‘below the radar organisations’ not currently registered in registers and databases on the third sector
- In their social media analysis of tweets related to the Somerset Floods, Demos found that 39,000 tweets were related to social action
New ways of capturing, sharing and analysing data have the potential to transform how community and voluntary sector organisations work and how social action happens. However, while analysing and using data is core to how some of the world’s fastest growing businesses understand their customers and develop new products and services, civil society organisations are still some way off from making the most of this potential.
Over the last 12 months Nesta has grant funded a number of research projects that explore two dimensions of how big and open data can be used for the common good. Firstly, how it can be used by charities to develop better products and services and secondly, how it can help those interested in civil society better understand social action and civil society activity.
- Citizens Advice Bureau (CAB) and Datakind, a global community of data scientists interested in how data can be used for a social purpose, were grant funded to explore how a datadriven approach to mining the rich data that CAB holds on social issues in the UK could be used to develop a real–time dashboard to identify emerging social issues. The project also explored how data–driven methods could better help other charities such as St Mungo’s and Buttle UK, and how data could be shared more effectively between charities as part of this process, to create collaborative data–driven projects.
- Five organisations (The RSA, Cardiff University, The Demos Centre for Analysis of Social Media, NCVO and European Alternatives) were grant funded to explore how data–driven methods, such as open data analysis and social media analysis, can help us understand informal social action, often referred to as ‘below the radar activity’ in new ways.
This paper is not the definitive story of the opportunities in using big and open data for the common good, but it can hopefully provide insight on what can be done and lessons for others interested in exploring the opportunities in these methods….(More).”
“Memorandum: Unleashing the Power of Data to Serve the American People
To: The American People
From: Dr. DJ Patil, Deputy U.S. CTO for Data Policy and Chief Data Scientist
….While there is a rich history of companies using data to their competitive advantage, the disproportionate beneficiaries of big data and data science have been Internet technologies like social media, search, and e-commerce. Yet transformative uses of data in other spheres are just around the corner. Precision medicine and other forms of smarter health care delivery, individualized education, and the “Internet of Things” (which refers to devices like cars or thermostats communicating with each other using embedded sensors linked through wired and wireless networks) are just a few of the ways in which innovative data science applications will transform our future.
The Obama administration has embraced the use of data to improve the operation of the U.S. government and the interactions that people have with it. On May 9, 2013, President Obama signed Executive Order 13642, which made open and machine-readable data the new default for government information. Over the past few years, the Administration has launched a number of Open Data Initiatives aimed at scaling up open data efforts across the government, helping make troves of valuable data — data that taxpayers have already paid for — easily accessible to anyone. In fact, I used data made available by the National Oceanic and Atmospheric Administration to improve numerical methods of weather forecasting as part of my doctoral work. So I know firsthand just how valuable this data can be — it helped get me through school!
Given the substantial benefits that responsibly and creatively deployed data can provide to us and our nation, it is essential that we work together to push the frontiers of data science. Given the importance this Administration has placed on data, along with the momentum that has been created, now is a unique time to establish a legacy of data supporting the public good. That is why, after a long time in the private sector, I am returning to the federal government as the Deputy Chief Technology Officer for Data Policy and Chief Data Scientist.
Organizations are increasingly realizing that in order to maximize their benefit from data, they require dedicated leadership with the relevant skills. Many corporations, local governments, federal agencies, and others have already created such a role, which is usually called the Chief Data Officer (CDO) or the Chief Data Scientist (CDS). The role of an organization’s CDO or CDS is to help their organization acquire, process, and leverage data in a timely fashion to create efficiencies, iterate on and develop new products, and navigate the competitive landscape.
The Role of the First-Ever U.S. Chief Data Scientist
Similarly, my role as the U.S. CDS will be to responsibly source, process, and leverage data in a timely fashion to enable transparency, provide security, and foster innovation for the benefit of the American public, in order to maximize the nation’s return on its investment in data.
So what specifically am I here to do? As I start, I plan to focus on these four activities:
…(More)”
New book by Cass Sunstein: “Our ability to make choices is fundamental to our sense of ourselves as human beings, and essential to the political values of freedom-protecting nations. Whom we love; where we work; how we spend our time; what we buy; such choices define us in the eyes of ourselves and others, and much blood and ink has been spilt to establish and protect our rights to make them freely.
Choice can also be a burden. Our cognitive capacity to research and make the best decisions is limited, so every active choice comes at a cost. In modern life the requirement to make active choices can often be overwhelming. So, across broad areas of our lives, from health plans to energy suppliers, many of us choose not to choose. By following our default options, we save ourselves the costs of making active choices. By setting those options, governments and corporations dictate the outcomes for when we decide by default. This is among the most significant ways in which they effect social change, yet we are just beginning to understand the power and impact of default rules. Many central questions remain unanswered: When should governments set such defaults, and when should they insist on active choices? How should such defaults be made? What makes some defaults successful while others fail?….
The onset of big data gives corporations and governments the power to make ever more sophisticated decisions on our behalf, defaulting us to buy the goods we predictably want, or vote for the parties and policies we predictably support. As consumers we are starting to embrace the benefits this can bring. But should we? What will be the long-term effects of limiting our active choices on our agency? And can such personalized defaults be imported from the marketplace to politics and the law? Confronting the challenging future of data-driven decision-making, Sunstein presents a manifesto for how personalized defaults should be used to enhance, rather than restrict, our freedom and well-being. (More)”
Aida Akl at VOA TECHtonics: “The crisis that plunged east Ukraine into war in November 2013 has damaged or destroyed critical infrastructure and limited access to areas caught up in fighting between Ukraine’s government forces and pro-Russian rebels. In order to assess damage, the United Nations Development Program (UNDP) turned to crowdsourcing to help restore social infrastructure as part of a United Nations, European Union and World Bank Recovery and Peacebuilding Assessment for Eastern Ukraine….
Using an interactive map, ReDonbass, and a mobile app (Android and iOS), people of Donetsk and Lugansk regions can report damaged homes, hospitals, schools, kindergartens or libraries.
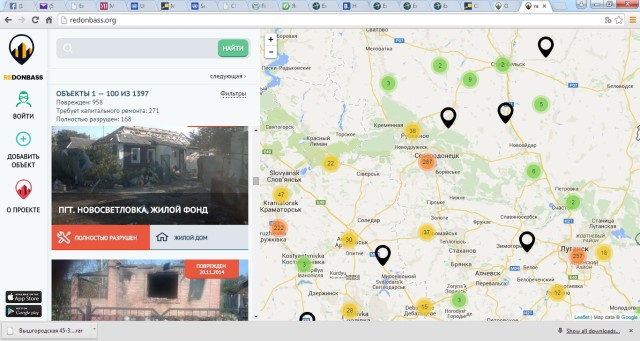
The easy-to-use interactive tool allows any person with a mobile phone and access to the Internet to download the most accurate data about the building in its location, photographs of the damage, and the status of the recovery phase. After that, the Ukrainian government and international donors will use the data to better plan reconstruction.
Information from the map will contribute to an ongoing Recovery and Peacebuilding Assessment for Eastern Ukraine. UNDP is part of the assessment that brings the United Nations, the European Union and the World Bank Group together to analyze the impact of the conflict and offer recommendations for short-term recovery and peacebuilding over the next two years….The map has also proven to be very useful for the experts from the Ukrainian Government and a recently launched UNDP-Government of Japan project aiming to restore critical infrastructure for social care and services. They [are] using it to identify schools, orphanages, elderly homes, and social services centers that need to be restored and rebuilt first….(More)”.
Addy Dugdale at FastCompany: “A new concept app from the London office of design and innovation consultancy Smart Design aims to improve the health of a large portion of the world’s population, a segment for whom weight loss can be a matter of life and death: diabetics.
Nudge is a concept app aimed at pre-diabetics—people with a high risk of developing type 2 diabetes—to change their eating habits. Described as a “personal nutritionist disguised as a shopping assistant,” the app keeps track of a user’s weekly grocery shopping using a phone’s camera to scan products on store shelves. The app looks for purchasing patterns that can be improved, and suggests healthy alternatives—like substituting red rice for white rice, or maybe even quinoa—to nudge the individual toward making better decisions. The idea is to help pre-diabetics make small, incremental changes.
…(More)”
at NextGov: “Federal agencies, thanks to their unique missions, have long been collectors of valuable, vital and, no doubt, arcane data. Under a nearly two-year-old executive order from President Barack Obama, agencies are releasing more of this data in machine-readable formats to the public and entrepreneurs than ever before.
But agencies still need a little help parsing through this data for their own purposes. They are turning to industry, academia and outside researchers for cutting-edge analytics tools to parse through their data to derive insights and to use those insights to drive decision-making.
Take the U.S. Agency for International Development, for example. The agency administers U.S. foreign aid programs aimed at ending extreme poverty and helping support democratic societies around the globe.
Under the agency’s own recent open data policy, it’s started collecting reams of data from its overseas missions. Starting Oct. 1, organizations doing development work on the ground – including through grants and contracts – have been directed to also collect data generated by their work and submit it to back to agency headquarters. Teams go through the data, scrub it to remove sensitive material and then publish it.
The data spans the gamut from information on land ownership in South Sudan to livestock demographics in Senegal and HIV prevention activities in Zambia….The agency took the first step in solving that problem with a Jan. 20 request for information from outside groups for cutting-edge data analytics tools.
“Operating units within USAID are sometimes constrained by existing capacity to transform data into insights that could inform development programming,” the RFI stated.
The RFI queries industry on their capabilities in data mining and social media analytics and forecasting and systems modeling.
USAID is far from alone in its quest for data-driven decision-making.
A Jan. 26 RFI from the Transportation Department’s Federal Highway Administration also seeks innovative ideas from industry for “advanced analytical capabilities.”…(More)”
Tarun Wadhwa at Singularity Hub: “There’s now a technology to replace almost everything in your wallet. Your cash, credit cards, and loyalty programs are all on their way to becoming obsolete. Money can now be sent via app, text, e-mail — it can even be sent via Snapchat. But you can’t leave your wallet home just yet. That’s because there is one item that remains largely unchanged: your driver’s license.
If the Iowa Department of Motor Vehicles has its way, that may no longer be the case. According to an article in the Des Moines Register, the agency is in the early stages of developing mobile software for just this purpose. The app would store a resident’s personal information, whatever is already on the physical licenses, and also include a scannable bar code. The plans are for the app to include a two-step verification process including some type of biometric or pin code. At this time, it appears that specific implementation details are still being worked out.
The governments of the United Kingdom and United Arab Emirates had both previously announced their own attempts to experiment with the concept. It’s becoming increasingly common to see mobile versions of other documents. Over 30 states now allow motorists to show electronic proof of insurance. It only follows that the driver’s license would be next. But the considerations around that document are different — it is perhaps the most regulated and important document that a person carries….(More)”