Stefaan Verhulst
Paper by María Verónica Alderete: “A smart city approach places citizens at the center of decision-making. However, only a small proportion of citizens actually engage in participatory initiatives. Although citizen participation has been extensively studied, limited empirical evidence exists on how citizens’ awareness of participatory initiatives relates to both their participation and their perception of municipal efforts to promote participation. This paper analyses these relationships using a Propensity Score Matching (PSM) approach based on survey data from a medium-sized city in Argentina. Since the factors associated with participation and perceptions of municipal promotion may also shape citizens’ awareness of government programs, PSM is used to improve comparability between aware and non-aware citizens and to examine the association between awareness of participatory initiatives and participation outcomes. The results show statistically significant differences in both participation propensity and perceptions of municipal promotion between citizens who are aware of these initiatives and those who are not. Awareness is positively associated with prior civic engagement, visiting the municipal website and age, and negatively associated with being a woman. Policy implications highlight the importance of disseminating successful participatory experiences and strengthening communication strategies to encourage broader citizen engagement…(More)”.
Paper by Viktor Müller, Luc Steels and Eörs Szathmáry: “Evolvable AI (eAI), i.e., AI systems whose components, learning rules, and deployment conditions can themselves undergo Darwinian evolution, may soon emerge from current trends in generative, agentic, and embodied AI. We argue that this possibility has been underappreciated in debates on AI safety and existential risk. Here, we ask under what technical and ecological conditions AI becomes evolvable, what kinds of behaviors are then likely to emerge, and how such systems could be governed. Drawing on biological evolution and decades of digital evolution experiments, we distinguish “breeder” scenarios, in which humans impose fitness criteria and control reproduction, from “ecosystem” scenarios, in which selection arises from open environments and control erodes. In the latter, selfish replication reliably gives rise to cheating, parasitism, deception, and manipulation, even in very simple systems. We review recent developments that push AI toward open-ended evolution, including evolutionary prompt and model search, self-improving learning rules, self-rewarding and self-deploying agents, and AI-driven code generation for robots and software. We interpret these trends through the theory of major evolutionary transitions and suggest that eAI could mark a shift in the units and substrates of evolution—a possible “Life 2.0.” To steer this transition, we propose interventions that gate replication, treat model variants as genetic material, and reshape selection pressures so that deception and loss of control are disfavored. Anticipating and regulating evolvable AI is, we argue, essential to avoid a harmful coevolutionary arms race while preserving the potential benefits of powerful AI systems…(More)”.
Key Findings: “The 2026 Global Peace Index (GPI) reveals a world struggling with the economic consequences of a record-high number of conflicts that are increasingly interconnected and difficult to resolve. This deterioration is driven by a profound geopolitical shift, characterised by the rising influence of middle powers and the waning strength of traditional European powers known as the “Great Fragmentation.” This is also accompanied by a rapid technological revolution in warfare that is leaving international law and diplomacy far behind.
For the first time in history, machines are making life-and-death combat decisions faster than any human can review them, and the international frameworks meant to govern them barely exist.
Key findings:
- Global peace is at its lowest level since the inception of the Index, while the conditions that precede conflict are the worst since WWII
- 99 countries witnessed a deterioration in peacefulness in the past year, the highest number since the inception of the Index 20 years ago.
- 119 countries, 73%, are now less peaceful than when the GPI was first published in 2007.
- The number of countries engaged in external conflict has nearly doubled from 59 in 2008 to 103 in the 2026 GPI.
- The global economic impact of violence increased by 3.2% to US$21.81 trillion in 2025, equivalent to 10.5% of global GDP.
- Drone attacks rose by over 11,500% between 2018 and 2025, while AI has
compressed targeting times from one day to seconds. - Deaths from global conflict remain at historic highs, with over 181,000 killed in 2025, a six-fold increase since 2008.
- Led by Europe, global military expenditure reached a record US$2.9 trillion in 2025. Excluding the US, military expenditure increased by 9.2%.
- Successful diplomacy that prevents the war in Iran from restarting would be worth approximately US$2.2 trillion to the global economy…(More)”
Article by Will Douglas Heaven: “Google DeepMind is funding research into the potential dangers of situations where millions of different AI agents interact with each other online.
According to Rohin Shah, who directs the company’s AGI safety and alignment research, the mass-market arrival of agents that can carry out tasks without human oversight and follow instructions given to them by other agents creates a whole new class of risk.
In an effort to address this, Google DeepMind—which made agent-based tools a centerpiece of Google I/O last month—has teamed up with several other organizations to announce a $10 million funding pot for researchers to study the behavior of multi-agent systems and come up with ways to prevent unsafe scenarios. Joining Google DeepMind are Schmidt Sciences, a philanthropic foundation set up by Eric and Wendy Schmidt; ARIA, the UK government’s moonshot agency; the Cooperative AI foundation, a UK-based nonprofit research outfit; and Google’s charitable arm, Google.org.
I asked Shah and James Fox, who leads the Science of Trustworthy AI program at Schmidt Sciences, what they hope to achieve with that $10 million. It’s no small sum, but it’s dwarfed by the budgets commanded by Google DeepMind’s own research teams.
https://vx-piano.technologyreview.com/checkout/template/cacheableShow.html?aid=WUOCNSUgpu&templateId=OTCBIZBLG8WE&templateVariantId=OTVVSWLU1Z7J2&offerId=fakeOfferId&experienceId=EX43E7JR539R&iframeId=offer_49fdf5ec6b28d0d41847-0&displayMode=inline&pianoIdUrl=https%3A%2F%2Fauth.technologyreview.com%2Fid%2F&widget=template&url=https%3A%2F%2Fwww.technologyreview.com%2F2026%2F06%2F11%2F1138794%2Fgoogle-deepmind-is-worried-about-what-happens-when-millions-of-agents-start-to-interact%2F&isConsentManagerEnabled=false
The aim is to kick-start research outside tech companies, says Shah: “The strength of academia is that it can look really quite far into the future and do the kind of work that isn’t top of mind at industry labs.”
“The main issue is that there just isn’t really a field of research for multi-agent safety yet,” he adds. “And we would like there to be.”
The concern is that as more and more AI agents get deployed and begin working together, we could hit a tipping point where imagined scenarios become real. “We see this with humanity, too,” says Shah. “Our institutions can accomplish things that no individual human can.”
Shah thinks we have a few more months to go before agents are deployed throughout the economy in numbers that make potential risks a real concern. He wants to get ahead of that moment…(More)”.
Article by Natalie B. Aviles, and Janet Vertesi: “In this chaotic time, Vannevar Bush’s Science, the Endless Frontier has emerged as a symbolically meaningful text among scientists, who frequently point to it as the basis for the government’s long-running support of university research. Certainly, Bush marked a call for a new industrial policy in the United States that would make the nation a global leader in the new world order. He would later be credited as the architect of the so-called social contract of science, whereby federal funding is allocated primarily to university researchers in pursuit of free inquiry that might later yield some economic or social benefit. But this mythologized rendering of the innovation system overlooks other key ideas, like those expressed by sociologist Robert K. Merton, that described how the United States should govern science democratically based on lessons learned from the Second World War. Rereading Merton now, even more than revisiting Bush, better exposes the vulnerabilities driving us, as social scientists, to defend a vision of science as—and for—democracy in our own era.
A major figure in American sociology and a professor at Columbia University from 1941 until 1979, Merton casts a long shadow over contemporary sociology of science. As a structural-functionalist, his sociological approach assumed that the way institutions are structured strongly influences the social orders that allow them to serve different vital functions in society. Most enduring is his work from the 1940s addressing what he called “the normative structure of science,” which is still taught as “the norms” of science: communalism (science as communal property), universalism (participation without prejudice), disinterestedness (against ideology), and organized skepticism (deliberative, not dogmatic). These conditions, which Merton claimed are distinct to free scientific inquiry, allow science to thrive as an institutional form…(More)”.
About: ” Most legal-data projects scrape statutes and dump them into a convenient format. That throws away the structure: cross-references, temporal validity, the relationships between acts. And that structure is the part that actually makes legislation useful to machines. We do the opposite.
Principles:
1. Normalize metadata, never content
This is the rule everything else follows from. Legal content does not normalize across jurisdictions, and the projects that try to force it either collapse into a useless lowest common denominator or balloon into an unmaintainable schema with a field for every national exception.
So we draw a hard line. Identity, time, and citations are normalized, because every legal system has a when, a what-is-named-what, and a who-cites-whom. Everything else, the substantive structure and the text, stays native, in the jurisdiction’s own Akoma Ntoso profile.
The testIf two lawyers from two countries would argue about how to model it, it’s content, so leave it native. If they agree it exists in both systems, it’s metadata, so normalize it.
2. A profile, not a replacement
We’re not inventing a format. AKN4OLF is a profile of Akoma Ntoso, the OASIS standard, in exactly the sense that AKN4EU, AKN4UN, and AKN4Africa are profiles. We speak the language the EU, the UN, and national gazettes already speak. We don’t try to replace Akoma Ntoso, ELI, or any national system.
A new format asks the whole world to come to you. A profile lets you meet the world where it already is.
3. Conformance over coordination
The conformance suite is the project’s coordination mechanism. An adapter is correct when it passes the suite, not when a committee approves it. This is what lets contributors who have never met, working on jurisdictions that share nothing, produce interoperable output.
The spec is executable. Interoperability is checkable. That is the only way this scales.
4. Provenance over possession
The goal is not to own a copy of the law. It is to produce copies whose lineage back to the official source is explicit and reproducible. Re-run the pipeline, get the same archive. Nothing is hand-edited; corrections go into the adapter, never the output.
5. Honest about what we are
This is an open-source project. It is not an incorporated legal entity. We don’t solicit or accept donations on behalf of a “foundation” that doesn’t exist as a legal body. The name describes the work, not a fundraising vehicle…(More)”.
Article by Josh Taylor: “An AI model trained on data collected from users of Pokémon Go will potentially help military drones find their location in war zones.
Pokémon Go, a 2016 augmented reality mobile game, allowed players to find and catch Pokémon in the real world using the cameras on their mobile phones, and exploded in popularity. In 2018, the company reported having more than 800m downloads worldwide.
A 2021 update to the game introduced Pokéstops, which gave players in-game rewards for scanning real locations using their devices. It required users to opt in and upload the recording.
Niantic, which created Pokémon in partnership with Nintendo, collected users’ location scan data before the company sold its gaming division in 2025.
The historical scans were used to train the company’s AI models to recognise and interpret spaces in the physical world, as first reported by DroneXL this week…(More)”.
Article by Stefaan Verhulst and Begoña G. Otero: “The European Commission’s Technological Sovereignty Package (IP/26/1187) marks an important moment in the global political economy of the digital age. Presented by Commission President Ursula von der Leyen as an existential imperative for protecting critical infrastructure, the initiative signals an increasingly assertive European response to a rapidly changing geopolitical landscape. Through proposed initiatives such as the Chips Act 2.0, the Cloud and AI Development Act, the Open Source Strategy, and the Strategic Roadmap for Digitalisation and AI in Energy, Brussels has made clear that digital infrastructure is no longer viewed merely as an engine of economic growth but as a strategic asset central to security, competitiveness, and geopolitical influence.
Together, these measures seek to strengthen Europe’s position across the full digital value chain: expanding domestic semiconductor production and advanced chip design capabilities; tripling Europe’s data center capacity over the coming five to seven years; accelerating the deployment of cloud and AI infrastructure; scaling the adoption of artificial intelligence through a network of Experience and Acceleration Centres (AI Factories); promoting open-source alternatives in cloud, AI, cybersecurity, internet technologies, and semiconductors; and integrating digital infrastructure more directly into Europe’s energy system.
Yet technological sovereignty should not be understood as an end in itself. The ultimate objective cannot simply be to manufacture more chips, build more data centers, or host more AI models within European borders. Rather, it should be to ensure that individuals, communities, businesses, and public institutions have meaningful agency over the digital systems that increasingly shape economic opportunity, democratic participation, cultural expression, and public life. Viewed through this lens, the debate around technological sovereignty is fundamentally a debate about digital self-determination: who has the ability to shape the digital systems upon which society depends, under what conditions, and for whose benefit. What follows, then, is that tackling asymmetry by creating new asymmetries is not a desirable outcome. A sovereignty that simply transfers concentrated power from foreign to domestic hands, or that substitutes one set of gatekeepers for another, would resolve the geopolitical problem while reproducing the democratic one. How an infrastructure distributes powers is not fixed by the technology itself but by the institutions and rules built around it: concentration is a choice, not an inevitability. What matters then is not who holds power over digital systems but whether that power is distributed, accountable, and open to challenge.
The Triad of Tech Sovereignty
As the global debate over technological sovereignty intensifies, this quest is increasingly unfolding across three interconnected dimensions (what we call the “Triad of Tech Sovereignty”):
- the weaponization of structural dependency, where reliance on foreign infrastructure becomes vulnerability;
- the weaponization of digital openness, where access and interoperability become mechanisms for extraction; and
- systemic asymmetries of agency, where those most affected by decisions and technical systems often have the least say.
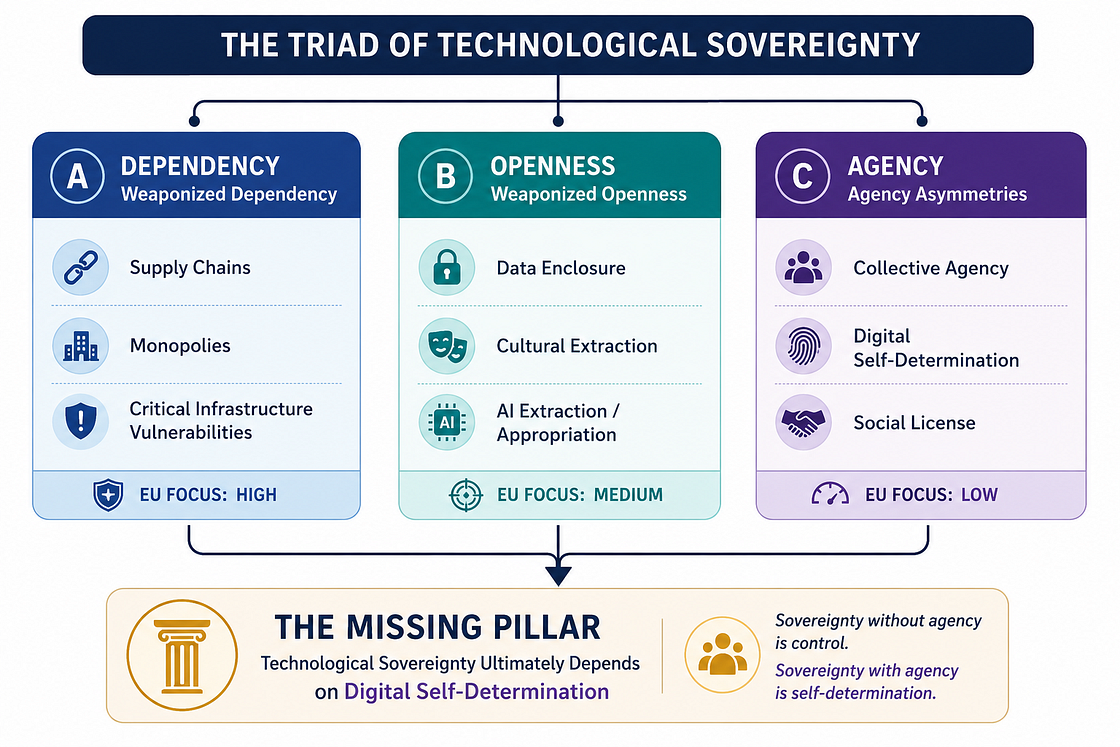
While Europe’s latest initiatives offer substantial responses to the first dimension and growing attention to the second, the third is noticeably misaligned. By prioritizing the hard infrastructure of sovereignty over the democratic imperative of self-determination, Europe risks building an impressive industrial fortress without securing the social foundations required to sustain it…(More)”.
Press Release by The Linux Foundation: “… announced the launch of the OpenSharing Project, an open, vendor-neutral protocol designed to standardize how organizations share AI assets and data. Hosted by the Linux Foundation and contributed by Databricks, OpenSharing evolves the widely adopted Delta Sharing protocol to meet the requirements of the agentic era, providing the first unified framework for exchanging agent skills, AI models, and unstructured data volumes across disparate platforms.
As enterprises accelerate the deployment of agentic AI, the lack of a standardized exchange protocol has forced organizations to rely on point-to-point integrations or proprietary marketplaces. OpenSharing eliminates these silos by enabling secure, cross-organizational sharing through a single, open protocol. By abstracting underlying storage complexities, the project allows enterprises to publish AI assets and data that can be consumed by anyone, regardless of their specific cloud environment or platform.
“OpenSharing addresses a critical need for a common, vendor-neutral framework that enables organizations to exchange AI assets securely and interoperably across platforms and ecosystems,” said Jim Zemlin, CEO, Linux Foundation. “By bringing this technology to the Linux Foundation, we can foster open collaboration, broad industry participation, and the shared governance needed to accelerate AI innovation at scale.”
A key aspect of OpenSharing is its support for interoperability across multiple open table formats and data-sharing approaches. Building on Delta Sharing’s open connectors that support a wide range of platforms, OpenSharing expands this cross-platform interoperability with support for Iceberg IRC clients, expanding the universe of reachable recipients. This broadens compatibility across data platforms and reduces fragmentation through a more consistent and collaborative sharing model.
“Delta Sharing proved the industry would choose open over locked-in,” said Matei Zaharia, Co-founder and CTO of Databricks. “OpenSharing extends that principle to the full AI stack, while expanding the cross-platform ecosystem to Iceberg recipients and on-premises providers. The agentic era deserves an open foundation, and OpenSharing delivers it.”..(More)”.
Policy Memo by Anna Lenhart: “AI systems are regularly used to make decisions that directly impact individuals, from who gets a housing voucher to who gets a job, to bail—contexts with a long history of social disparities, facilitating encoded discrimination. The designs of these consequential AI decision systems are shaped by corporations and increasingly overseen by governments with little input from the public, specifically from users and individuals impacted by these decisions.
Executive branch agencies frequently engage the public in policy decisions via requests for comment and town halls. For decades, the Food and Drug Administration (FDA) has gone beyond traditional agency engagement processes via the Patient Representative Program (PRP), which recruits, trains, and embeds patients into oversight of the pharmaceutical industry, including decisions regarding clinical trial design, endpoints (evaluation metrics), risk/benefit analysis, product labeling, etc. This memo proposes creating a Decision Subject Representative Program inspired by the FDA’s Patient Representative Program.
While pharmaceutical drugs and consequential AI decision systems vary in scope and impact, both technologies need to be safe and effective to be trusted by the public and consumers. Public engagement has long been a tool for building trust and legitimacy in governance decisions while providing a complement to expertise associated with elite institutions. Three decades of FDA experience in systematizing patient engagement offer valuable inspiration for AI governance. Specifically, the General Services Administration (GSA) should pilot embedding Decision Subject Representatives into the procurement process for consequential AI decision systems, the National Institute of Standards and Technology (NIST) should pilot engaging Decision Subject Representatives in efforts to shape standards, and Congress could add a flexible Decision Subject Representatives Program (DSRP) to new regulatory proposals…(More)”.