Stefaan Verhulst
Book edited by Frans L. Leeuw and Michael Bamberger: “…explores how Artificial Intelligence (AI) and Big Data contribute to the evaluation of the rule of law (covering legal arrangements, empirical legal research, law and technology, and international law), and social and economic development programs in both industrialized and developing countries. Issues of ethics and bias in the use of AI are also addressed and indicators of the growth of knowledge in the field are discussed.
Interdisciplinary and international in scope, and bringing together leading academics and practitioners from across the globe, the book explores the applications of AI and big data in Rule of Law and development evaluation, identifies differences in the approaches used in the two fields, and how each could learn from the approaches used in the other, as well as differences in the AI-related issues addressed in industrialized nations compared to those addressed in Africa and Asia.
Artificial Intelligence and Big Data is an essential read for researchers, academics and students working in the fields of Rule of Law and Development, and researchers in institutions working on new applications in AI will all benefit from the book’s practical insights…(More)”.
Paper by Robert J. Lempert: “Seventy-five years into the Great Acceleration—a period marked by unprecedented growth in human activity and its effects on the planet—some type of societal transformation is inevitable. Successfully navigating these tumultuous times requires scientific, evidence-based information as an input into society’s value-laden decisions at all levels and scales. The methods and tools most commonly used to bring such expert knowledge to policy discussions employ predictions of the future, which under the existing conditions of complexity and deep uncertainty can often undermine trust and hinder good decisions. How, then, should experts best inform society’s attempts to navigate when both experts and decisionmakers are sure to be surprised? Decision Making under Deep Uncertainty (DMDU) offers an answer to this question. With its focus on model pluralism, learning, and robust solutions coproduced in a participatory process of deliberation with analysis, DMDU can repair the fractured conversations among policy experts, decisionmakers, and the public. In this paper, the author explores how DMDU can reshape policy analysis to better align with the demands of a rapidly evolving world and offers insights into the roles and opportunities for experts to inform societal debates and actions toward more-desirable futures…(More)”.
Article by Lisa Margonelli: “Only a few months into 2025, the scientific enterprise is reeling from a series of shocks—mass firings of the scientific workforce across federal agencies, cuts to federal research budgets, threats to indirect costs for university research, proposals to tax endowments, termination of federal science advisory committees, and research funds to prominent universities held hostage over political conditions. Amid all this, the public has not shown much outrage at—or even interest in—the dismantling of the national research project that they’ve been bankrolling for the past 75 years.
Some evidence of a disconnect from the scientific establishment was visible in confirmation hearings of administration appointees. During his Senate nomination hearing to head the department of Health and Human Services, Robert F. Kennedy Jr. promised a reorientation of research from infectious disease toward chronic conditions, along with “radical transparency” to rebuild trust in science. While his fans applauded, he insisted that he was not anti-vaccine, declaring, “I am pro-safety.”
But lack of public reaction to funding cuts need not be pinned on distrust of science; it could simply be that few citizens see the $200-billion-per-year, envy-of-the-world scientific enterprise as their own. On March 15, Alabama meteorologist James Spann took to Facebook to narrate the approach of 16 tornadoes in the state, taking note that people didn’t seem to care about the president’s threat to close the National Weather Service. “People say, ‘Well, if they shut it down, I’ll just use my app,’” Spann told Inside Climate News. “Well, where do you think the information on your app comes from? It comes from computer model output that’s run by the National Weather Service.” The public has paid for those models for generations, but only a die-hard weather nerd can find the acronyms for the weather models that signal that investment on these apps…(More)”.
Article by Chloe Cornish: “The United Arab Emirates aims to use AI to help write new legislation and review and amend existing laws, in the Gulf state’s most radical attempt to harness a technology into which it has poured billions.
The plan for what state media called “AI-driven regulation” goes further than anything seen elsewhere, AI researchers said, while noting that details were scant. Other governments are trying to use AI to become more efficient, from summarising bills to improving public service delivery, but not to actively suggest changes to current laws by crunching government and legal data.
“This new legislative system, powered by artificial intelligence, will change how we create laws, making the process faster and more precise,” said Sheikh Mohammad bin Rashid Al Maktoum, the Dubai ruler and UAE vice-president, quoted by state media.
Ministers last week approved the creation of a new cabinet unit, the Regulatory Intelligence Office, to oversee the legislative AI push.
Rony Medaglia, a professor at Copenhagen Business School, said the UAE appeared to have an “underlying ambition to basically turn AI into some sort of co-legislator”, and described the plan as “very bold”.
Abu Dhabi has bet heavily on AI and last year opened a dedicated investment vehicle, MGX, which has backed a $30bn BlackRock AI-infrastructure fund among other investments. MGX has also added an AI observer to its own board.
The UAE plans to use AI to track how laws affect the country’s population and economy by creating a massive database of federal and local laws, together with public sector data such as court judgments and government services.
The AI will “regularly suggest updates to our legislation,” Sheikh Mohammad said, according to state media. The government expects AI to speed up lawmaking by 70 per cent, according to the cabinet meeting readout…(More)”
Article by Alfred Ng: “Active-duty members of the U.S. military are vulnerable to having their personal information collected, packaged and sold to overseas companies without any vetting, according to a new report funded by the U.S. Military Academy at West Point.
The report highlights a significant American security risk, according to military officials, lawmakers and the experts who conducted the research, and who say the data available on servicemembers exposes them to blackmail based on their jobs and habits.
It also casts a spotlight on the practices of data brokers, a set of firms that specialize in scraping and packaging people’s digital records such as health conditions and credit ratings.
“It’s really a case of being able to target people based on specific vulnerabilities,” said Maj. Jessica Dawson, a research scientist at the Army Cyber Institute at West Point who initiated the study.
Data brokers gather government files, publicly available information and financial records into packages they can sell to marketers and other interested companies. As the practice has grown into a $214 billion industry, it has raised privacy concerns and come under scrutiny from lawmakers in Congress and state capitals.
Worried it could also present a risk to national security, the U.S. Military Academy at West Point funded the study from Duke University to see how servicemembers’ information might be packaged and sold.
Posing as buyers in the U.S. and Singapore, Duke researchers contacted multiple data-broker firms who listed datasets about active-duty servicemembers for sale. Three agreed and sold datasets to the researchers while two declined, saying the requests came from companies that didn’t meet their verification standards.
In total, the datasets contained information on nearly 30,000 active-duty military personnel. They also purchased a dataset on an additional 5,000 friends and family members of military personnel…(More)”
Report by Gustav Kjær Vad Nielsen & James MacDonald-Nelson: “As citizens’ assemblies and other forms of citizen deliberation are increasingly implemented in many parts of the world, it is becoming more relevant to explore and question the role of the physical spaces in which these processes take place.
This paper builds on existing literature that considers the relationships between space and democracy. In the literature, this relationship has been studied with a focus on the architecture of parliament buildings, and on the role of urban public spaces and architecture for political culture, both largely within the context of representative democracy and with little or no attention given to spaces for facilitated citizen deliberation. With very limited considerations of the spaces for deliberative assemblies in the literature, in this paper, we argue that the spatial qualities for citizen deliberation demand more critical attention.
Through a series of interviews with leading practitioners of citizens’ assemblies from six different countries, we explore what spatial qualities are typically considered in the planning and implementation of these assemblies, what are the recurring challenges related to the physical spaces where they take place, and the opportunities and limitations for a more intentional spatial design. In this paper, we synthesise our findings and formulate a series of considerations for the spatial qualities of citizens’ assemblies aimed at informing future practice and further research…(More)”.
The Economist: “In a messy age of grinding wars and multiplying tariffs, negotiators are as busy as the stakes are high. Alliances are shifting and political leaders are adjusting—if not reversing—positions. The resulting tumult is giving even seasoned negotiators trouble keeping up with their superiors back home. Artificial-intelligence (AI) models may be able to lend a hand.
Some such models are already under development. One of the most advanced projects, dubbed Strategic Headwinds, aims to help Western diplomats in talks on Ukraine. Work began during the Biden administration in America, with officials on the White House’s National Security Council (NSC) offering guidance to the Centre for Strategic and International Studies (CSIS), a think-tank in Washington that runs the project. With peace talks under way, CSIS has speeded up its effort. Other outfits are doing similar work.
The CSIS programme is led by a unit called the Futures Lab. This team developed an AI language model using software from Scale AI, a firm based in San Francisco, and unique training data. The lab designed a tabletop strategy game called “Hetman’s Shadow” in which Russia, Ukraine and their allies hammer out deals. Data from 45 experts who played the game were fed into the model. So were media analyses of issues at stake in the Russia-Ukraine war, as well as answers provided by specialists to a questionnaire about the relative values of potential negotiation trade-offs. A database of 374 peace agreements and ceasefires was also poured in.
Thus was born, in late February, the first iteration of the Ukraine-Russia Peace Agreement Simulator. Users enter preferences for outcomes grouped under four rubrics: territory and sovereignty; security arrangements; justice and accountability; and economic conditions. The AI model then cranks out a draft agreement. The software also scores, on a scale of one to ten, the likelihood that each of its components would be satisfactory, negotiable or unacceptable to Russia, Ukraine, America and Europe. The model was provided to government negotiators from those last three territories, but a limited “dashboard” version of the software can be run online by interested members of the public…(More)”.
Press Release: “The Open Data Policy Lab, a collaboration between The GovLab at New York University and Microsoft, has launched the New Commons Challenge, an initiative to advance the responsible reuse of data for AI-driven solutions that enhance local decision-making and humanitarian response.
The Challenge will award two winning institutions $100,000 each to develop data commons that fuel responsible AI innovation in these critical areas.
With the increasing use of generative AI in crisis management, disaster preparedness, and local decision-making, access to diverse and high-quality data has never been more essential.
The New Commons Challenge seeks to support organizations—including start-ups, non-profits, NGOs, universities, libraries, and AI developers—to build shared data ecosystems that improve real-world outcomes, from public health to emergency response.
Bridging Research and Real-World Impact
“The New Commons Challenge is about putting data into action,” said Stefaan Verhulst, Co-Founder and Chief Research and Development Officer at The GovLab. “By enabling new models of data stewardship, we aim to support AI applications that save lives, strengthen communities, and enhance local decision-making where it matters most.”
The Challenge builds on the Open Data Policy Lab’s recent report, “Blueprint to Unlock New Data Commons for AI,” which advocates for creating collaboratively governed data ecosystems that support responsible AI development.

How the Challenge Works
The challenge unfolds in two phases: Phase One: Open Call for Concept Notes (April 14 – June 2, 2025)
Innovators world-wide are invited to submit concept notes outlining their ideas. Phase Two: Full Proposal Submissions & Expert Review (June 2025)
- Selected applicants will be invited to submit a full proposal
- An interdisciplinary panel will evaluate proposals based on their impact potential, feasibility, and ethical governance.
Winners Announced in Late Summer 2025
Two selected projects will each receive $100,000 in funding, alongside technical support, mentorship, and global recognition…(More)”.
Data visualization by The New York Times: “In the maps below, Times Opinion can provide the clearest picture to date of how people move across the globe: a record of permanent migration to and from 181 countries based on a single, consistent source of information, for every month from the beginning of 2019 through the end of 2022. These estimates are drawn not from government records but from the location data of three billion anonymized Facebook users all over the world.
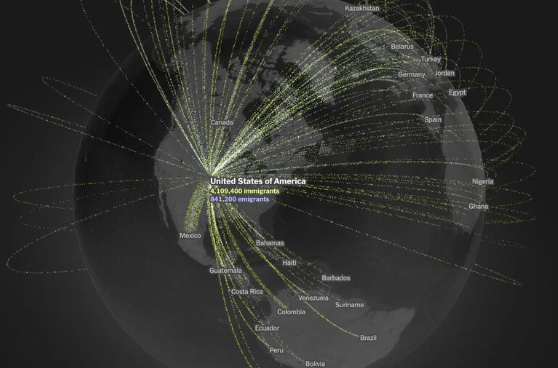
The analysis — the result of new research published on Wednesday from Meta, the University of Hong Kong and Harvard University — reveals migration’s true global sweep. And yes, it excludes business travelers and tourists: Only people who remain in their destination country for more than a year are counted as migrants here.
The data comes with some limitations. Migration to and from certain countries that have banned or restricted the use of Facebook, including China, Iran and Cuba, is not included in this data set, and it’s impossible to know each migrant’s legal status. Nevertheless, this is the first time that estimates of global migration flows have been made publicly available at this scale. The researchers found that from 2019 to 2022, an annual average of 30 million people — approximately one-third of a percent of the world’s population — migrated each year.
If you would like to see the data behind this analysis for yourself, we made an interactive tool that you can use to explore the full data set…(More)”
Article by Sheon Han: “Nearly 35 years ago, Ginsparg created arXiv, a digital repository where researchers could share their latest findings—before those findings had been systematically reviewed or verified. Visit arXiv.org today (it’s pronounced like “archive”) and you’ll still see its old-school Web 1.0 design, featuring a red banner and the seal of Cornell University, the platform’s institutional home. But arXiv’s unassuming facade belies the tectonic reconfiguration it set off in the scientific community. If arXiv were to stop functioning, scientists from every corner of the planet would suffer an immediate and profound disruption. “Everybody in math and physics uses it,” Scott Aaronson, a computer scientist at the University of Texas at Austin, told me. “I scan it every night.”
Every industry has certain problems universally acknowledged as broken: insurance in health care, licensing in music, standardized testing in education, tipping in the restaurant business. In academia, it’s publishing. Academic publishing is dominated by for-profit giants like Elsevier and Springer. Calling their practice a form of thuggery isn’t so much an insult as an economic observation. Imagine if a book publisher demanded that authors write books for free and, instead of employing in-house editors, relied on other authors to edit those books, also for free. And not only that: The final product was then sold at prohibitively expensive prices to ordinary readers, and institutions were forced to pay exorbitant fees for access…(More)”.