Stefaan Verhulst
Article by Giulio Quaggiotto: “…So when RIL – Red de Innovación Local, a South American nonprofit that connects more than 10,000 public servants across 800 cities in 30 countries, set out to improve how municipalities build strategy, its founder, Delfina Irazusta, knew the challenge would not be technical; it would be cultural.
To tackle it, she took the old idiom “eat your own dog food” to heart. She decided that her team would first try out a new strategy process for itself before bringing it to municipalities. This way, they would have the street credentials from having done the work, and they would be in a better position to provide advice on implementation.
The experiment centered on PortalRIL, RIL’s AI-powered platform trained on over a decade of local government knowledge. But as Stefaan Verhulst has observed, “The most consequential failures in data-driven policymaking and AI deployment often stem not from poor models or inadequate datasets but from poorly framed questions.”
Starting With Inquiry
It is for this reason that RIL team members were asked to start their strategy process in a rather unconventional manner, through a “Questions Tree,” or a structured reflection process guided by questions focusing on 3 different levels:
- Organisation-wide issues
- Individual questions on each member’s role
- Team level questions.
This team exercise produced a collaborative document summarizing the key questions informing RIL’s strategy going forward…(More)”.
Paper by Jiahao Lu et al: “Large Language Models (LLMs) represent a new frontier of digital infrastructure that can support a wide range of public-sector applications, from general purpose citizen services to specialized and sensitive state functions. When expanding AI access, governments face a set of strategic choices over whether to buy existing services, build domestic capabilities, or adopt hybrid approaches across different domains and use cases. These are critical decisions especially when leading model providers are often foreign corporations, and LLM outputs are increasingly treated as trusted inputs to public decision-making and public discourse. In practice, these decisions are not intended to mandate a single approach across all domains; instead, national AI strategies are typically pluralistic, with sovereign, commercial and open-source models coexisting to serve different purposes. Governments may rely on commercial models for non-sensitive or commodity tasks, while pursuing greater control for critical, high-risk or strategically important applications.
This paper provides a strategic framework for making this decision by evaluating these options across dimensions including sovereignty, safety, cost, resource capability, cultural fit, and sustainability. Importantly, “building” does not imply that governments must act alone: domestic capabilities may be developed through public research institutions, universities, state-owned enterprises, joint ventures, or broader national ecosystems. By detailing the technical requirements and practical challenges of each pathway, this work aims to serve as a reference for policy-makers to determine whether a buy or build approach best aligns with their specific national needs and societal goals…(More)”.
OECD Report: “Digital transformation is an imperative for modern governments. It enables better services, smarter decisions, and collaboration across siloes and borders, and is crucial for meeting citizens’ expectations in a context of rapid change. To succeed, governments need a bold, balanced approach grounded in coherent and trustworthy systems and governance structures. This paper presents the 2025 results of the Digital Government Index (DGI), which benchmarks the efforts made by governments to establish the foundations necessary to achieve a coherent, human-centred digital transformation of the public sector; and of the Open, Useful and Re-usable Data Index (OURdata), which measures governments’ efforts to design and implement national open government data policies. Data were collected in the first half of 2025, covering policies and initiatives from 01 January 2023 to 31 December 2024. A full analysis of the data, including drivers of change, major trends and country notes, will be included in the 2026 OECD Digital Government Outlook…(More)”.
Article by Tassallah Abdullahi: “Current guardian models are predominantly Western-centric and optimized for high resource languages, leaving low-resource African languages vulnerable to evolving harms, cross-lingual safety failures, and cultural misalignment. Moreover, most guardian models rely on rigid, predefined safety categories that fail to generalize across diverse linguistic and sociocultural contexts. Robust safety, therefore, requires flexible, runtime enforceable policies and benchmarks that reflect local norms, harm scenarios, and cultural expectations. We introduce UbuntuGuard, the first African policy-based safety benchmark built from adversarial queries authored by 155 domain experts across sensitive fields, including healthcare. From these expert-crafted queries, we derive context-specific safety policies and reference responses that capture culturally grounded risk signals, enabling policy aligned evaluation of guardian models. We
evaluate 13 models, comprising six general purpose LLMs and seven guardian models across three distinct variants: static, dynamic, and multilingual. Our findings reveal that existing English-centric benchmarks overestimate real-world multilingual safety, cross lingual transfer provides partial but insufficient coverage, and dynamic models, while better equipped to leverage policies at inference time, still struggle to fully localize African language contexts. These findings highlight the urgent need for multilingual, culturally grounded safety benchmarks to enable the development of reliable and equitable guardian models for low-resource languages. Our code can be found online..(More)”.
Article by Marco Di Natale: “In the past two decades, impact evaluation has become an unavoidable topic in the social sector. Yet beyond the discourse on how to measure social impact lies a structural problem: We are not producing reliable knowledge about what works, regardless of the method used. While part of the debate gravitates toward Randomized Control Trials (RCTs), the real gap lies in the absence of standards, capacities, and institutional structures that enable civil society and philanthropy to learn systematically. This article aims to reframe the conversation on what matters: rigor.
Drawing on my experience leading impact evaluations within government (including experimental and non-experimental studies) and later advising civil society organizations and philanthropic funders, I have seen how this gap is reinforced from different directions. On one side, reporting requirements often prioritize speed, volume, and compliance over understanding. On the other, critiques of experimental and quantitative approaches have sometimes been used to legitimize evaluations that abandon basic scientific logic altogether, as if complexity or social purpose exempted the sector from standards of credible inference. This article examines how these dynamics converged and what a more rigorous, learning-oriented approach to evaluation would require from philanthropy, organizations, and evaluators alike…(More)”.
Article by Ross Andersen: “To live in time is to wonder what will happen next. In every human society, there are people who obsess over the world’s patterns to predict the future. In antiquity, they told kings which stars would appear at nightfall. Today they build the quantitative models that nudge governments into opening spigots of capital. They pick winners on Wall Street. They estimate the likelihood of earthquakes for insurance companies. They tell commodities traders at hedge funds about the next month’s weather.
For years, some elite forecasters have been competing against one another in tournaments where they answer questions about events that will happen—or not—in the coming months or years. The questions span diverse subject matter because they’re meant to measure general forecasting ability, not narrow expertise. Players may be asked whether a coup will occur in an unstable country, or to project the future deforestation rate in some part of the Amazon. They may be asked how many songs from a forthcoming Taylor Swift album will top the streaming charts. The forecaster who makes the most accurate predictions, as early as possible, can earn a cash prize and, perhaps more important, the esteem of the world’s most talented seers.
These tournaments have become much more popular during the recent boom of prediction markets such as Polymarket and Kalshi, where hundreds of thousands of people around the world now trade billions of dollars a month on similar sorts of forecasting questions. And now AIs are playing in them, too. At first, the bots didn’t fare too well: At the end of 2024, no AI had even managed to place 100th in one of the major competitions. But they have since vaulted up the leaderboards. AIs have already proved that they can make superhuman predictions within the bounded context of a board game, but they may soon be better than us at divining the future of our entire messy, contingent world…(More)”.
OECD paper: “…identifies the most frequently cited features in existing definitions of agentic AI and AI agents, examines how these features are described across sources, and maps them to the key elements of the OECD definition of an AI system. By highlighting both shared traits and differences, the paper aims to support clearer conceptual understanding and inform future research and policymaking. It also provides descriptive data on recent trends in the uptake of AI agents and agentic AI…(More)”.
Article by Daniël Jurg, et al: “This article introduces “data mirroring,” a methodological framework for conducting data-donation-based interviews using Data Download Packages (DDPs) from digital platforms. Since the General Data Protection Regulation took effect, DDPs have found application in research. While the literature on the value of DDPs primarily points toward scaling and validating aggregate-level data, their potential to illuminate complex user–media relationships within datafied environments at the micro-level appears underexplored. Drawing from recent conceptualizations of the “data mirror,” which captures the feedback loops between users and digital media, this article provides theoretical grounding and practical guidelines for “mirroring” DDPs to users. Based on exercises with 64 participants, we articulate through an illustrative case study how DDPs can serve as prompts, contexts, and reflections, revealing reflexive strategies users employ to curate information flows on algorithmic platforms like Instagram. In addition, we introduce an open-source web application to operationalize DDPs as data mirrors for non-technical researchers…(More)”.
Tool by the dataindex.us: “… excited to launch the Data Checkup – a comprehensive framework for assessing the health of federal data collections, highlighting key dimensions of risk and presenting a clear status of data well-being.
When we started dataindex.us, one of our earliest tools was a URL tracker: a simple way to monitor whether a webpage or data download link was up or down. In early 2025, that kind of monitoring became urgent as thousands of federal webpages and datasets went dark.
As many of those pages came back online, often changed from their original form, we realized URL tracking wasn’t sufficient. Threats to federal data are coming from multiple directions, including loss of capacity, reduced funding, targeted removal of variables, and the termination of datasets that don’t align with administration priorities.
The more important question became: how do we assess the risk that a dataset might disappear, change, or degrade in the future? We needed a way to evaluate the health of a federal dataset that was broad enough to apply across many types of data, yet specific enough to capture the different ways datasets can be put at risk. That led us to develop the Data Checkup.
Once we had an initial concept, we brought together experts from across the data ecosystem to get feedback on that concept. The current Data Checkup framework reflects the feedback received from more than 30 colleagues.
The result is a framework built around six dimensions:
- Historical Data Availability
- Future Data Availability
- Data Quality
- Statutory Context
- Staffing and Funding
- Policy
Each dimension is assessed and assigned a status that communicates its level of risk:
- Gone
- High Risk
- Moderate Risk
- No Known Issue
Together, this assessment provides a more complete picture of dataset health than availability checks alone.
The Data Checkup is designed to serve the needs of both data users and data advocates. It supports a wide range of use cases, including academic research, policy decision-making, journalism, advocacy, and litigation…Here you can see the Data Checkup framework applied to a subset of datasets. At a high level, it provides a snapshot of dataset wellbeing, allowing you to quickly identify which datasets are facing risks…(More)”
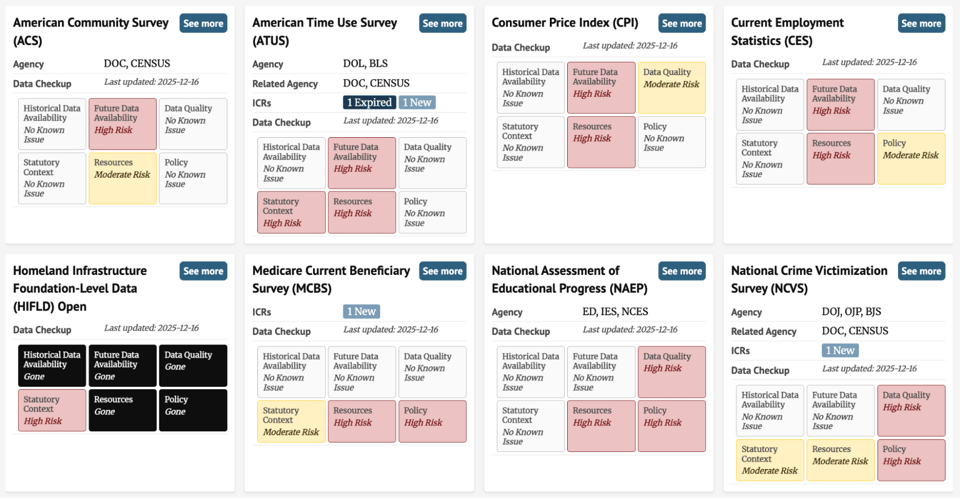, American Time Use Survey (ATUS), Consumer Price Index (CPI), Current Employment Statistics (CES), Homeland Infrastructure Foundation-Level Data (HIFLD) Open, Medicare Current Beneficiary Survey (MCBS), National Assessment of Educational Progress (NAEP), and National Crime Victimization Survey (NCVS). Each card displays six risk dimensions color-coded from white (No Known Issue) through yellow (Moderate Risk) and pink (High Risk) to black (Gone).")
Article by Oliver Roeder: “…From childhood, maps present the wooden feel of permanence. A globe sits on the sideboard. A teacher yanks down a spooled world from above the chalkboard, year after year. Road atlases are forever wedged in seat-back pockets. But maps, of course, could always be changing. In the short term, buildings and roads are built. In the medium term, territory is conquered and nations fall and are founded. In the long term, rivers change course and glaciers melt and mountains rise. In this era of conflicts in Ukraine and the Middle East, the undoing of national and international orders, and technological upheaval, a change in maps appears to be accelerating.

The world is impossible to map perfectly — too detailed, too spherical, too much fractal coastline. A map is necessarily a model. In one direction, the model asymptotes to the one-to-one scale map from the Jorge Luis Borges story that literally covers the land, a map of the empire the size of the empire, which proves useless and is left in tatters across the desert. There is a limit in the other direction too, not map expanded to world, but world collapsed into map — pure abstraction on a phone screen, obscuring the real world outside, geodata for delivery companies and rideshare apps.
But if maps abstract the world, their makers demand and encourage a close association with it. There must eventually be a search for the literal ground truth. As the filmmaker Carl Theodor Dreyer once said, “You can’t simplify reality without understanding it first.” Cartography, in turn, informs interactions with the world…(More)”.