Stefaan Verhulst
Blog by Mohamed Shareef: “…For two decades, Asian governments have counted broadband subscriptions, celebrated connectivity percentages, and commissioned policy frameworks.
Meanwhile, fishing communities in the Maldives still can’t afford 1GB of data, Pakistani e-government services crash during internet disruptions, and Tongan government operations collapsed for five weeks after a volcanic eruption severed their only submarine cable.
The gap between digital strategy documents and actual service delivery has never been wider. Here’s how Asian governments can close it.
Measure what citizens actually experience
Your ministry reports 85 per cent internet penetration. But can your citizens actually access government services during monsoon season when submarine cables fail? Can rural hospitals use your telemedicine platform on 3G networks? What percentage of median household income does meaningful connectivity actually cost? For Asian governments, this means replacing vanity metrics with citizen-centered measurements:
Instead of: “Fiber deployed to 500 district” . Measure: “Healthcare centers in 500 districts can access national health records during extreme weather events”
Instead of: “75 per cent smartphone penetration”. Measure: “Percentage of citizens who can afford data plans sufficient for essential government services”
Instead of: “E-government portal launched”. Measure: “Government services accessible to citizens using entry-level devices on congested networks”
Bangladesh’s experience with biometric identity systems, India’s Aadhaar implementation challenges, and Indonesia’s struggles with connectivity in remote islands offer lessons. The question isn’t whether you have digital infrastructure. It’s whether that infrastructure delivers services when citizens need them most…(More)”.
Paper by Pietro Bini, Lin William Cong, Xing Huang & Lawrence J. JinDo generative AI models, particularly large language models (LLMs), exhibit systematic behavioral biases in economic and financial decisions? If so, how can these biases be mitigated? Drawing on the cognitive psychology and experimental economics literatures, we conduct the most comprehensive set of experiments to date—originally designed to document human biases—on prominent LLM families across model versions and scales. We document systematic patterns in LLM behavior. In preference-based tasks, responses become more human-like as models become more advanced or larger, while in belief-based tasks, advanced large-scale models frequently generate rational responses. Prompting LLMs to make rational decisions reduces biases…(More)”.
Paper by Sándor Juhász, Johannes Wachs, Jermain Kaminski and César A. Hidalgo: “Despite the growing importance of the digital sector, research on economic complexity and its implications continues to rely mostly on administrative records—e.g. data on exports, patents, and employment—that have blind spots when it comes to the digital economy. In this paper we use data on the geography of programming languages used in open-source software to extend economic complexity ideas to the digital economy. We estimate a country’s software economic complexity index (ECIsoftware) and show that it complements the ability of measures of complexity based on trade, patents, and research to account for international differences in GDP per capita, income inequality, and emissions. We also show that open-source software follows the principle of relatedness, meaning that a country’s entries and exits in programming languages are partly explained by its current pattern of specialization. Together, these findings help extend economic complexity ideas and their policy implications to the digital economy…(More)”.
Article by Elie Dolgin: “AI is turning scientists into publishing machines—and quietly funneling them into the same crowded corners of research.
That’s the conclusion of an analysis of more than 40 million academic papers, which found that scientists who use AI tools in their research publish more papers, accumulate more citations, and reach leadership roles sooner than peers who don’t.
But there’s a catch. As individual scholars soar through the academic ranks, science as a whole shrinks its curiosity. AI-heavy research covers less topical ground, clusters around the same data-rich problems, and sparks less follow-on engagement between studies.
The findings highlight a tension between personal career advancement and collective scientific progress, as tools such as ChatGPT and AlphaFold seem to reward speed and scale—but not surprise.
“You have this conflict between individual incentives and science as a whole,” says James Evans, a sociologist at the University of Chicago who led the study.
And as more researchers pile onto the same scientific bandwagons, some experts worry about a feedback loop of conformity and declining originality. “This is very problematic,” says Luís Nunes Amaral, a physicist who studies complex systems at Northwestern University. “We are digging the same hole deeper and deeper.”
Evans and his colleagues published the findings 14 January in the journal Nature…(More)”.
Article by Mike McIntire: “Genetic researchers were seeking children for an ambitious, federally funded project to track brain development — a study that they told families could yield invaluable discoveries about DNA’s impact on behavior and disease.
They also promised that the children’s sensitive data would be closely guarded in the decade-long study, which got underway in 2015. Promotional materials included a cartoon of a Black child saying it felt good knowing that “scientists are taking steps to keep my information safe.”
The scientists did not keep it safe.
A group of fringe researchers thwarted safeguards at the National Institutes of Health and gained access to data from thousands of children. The researchers have used it to produce at least 16 papers purporting to find biological evidence for differences in intelligence between races, ranking ethnicities by I.Q. scores and suggesting Black people earn less because they are not very smart.
Mainstream geneticists have rejected their work as biased and unscientific. Yet by relying on genetic and other personal data from the prominent project, known as the Adolescent Brain Cognitive Development Study, the researchers gave their theories an air of analytical rigor…(More)”.
Report by Access Partnerships: “AI is reshaping work at a pace that most labor market information systems were not built to measure. Against this backdrop, the pressing question is not simply “who works where?” as it used to be in the past, but what people actually do, what skills they use, and how AI is changing tasks inside roles.
Today, many countries still rely on infrequent surveys, broad occupational categories, and siloed administrative datasets. That makes it harder to spot early signals of changing skills demand, target training investment, or support employers and workers as AI adoption accelerates.
Modernizing labor market data for the AI age
Our report, developed in partnership with Workday, helps governments modernize labor market data systems to better navigate AI-driven change. It establishes a global baseline across 21 countries, identifies system gaps, and sets out a practical pathway to strengthen readiness over time.
At the center is a maturity framework benchmarking countries across six dimensions of AI-ready labor market data: Forecasting readiness, Labor market granularity, Accessibility, Interoperability and integration, and Real-time responsiveness (FLAIR)…(More)”.
Paper by Anush Ganesh, and Krusha Bhatt: “As society advances toward a digital economy with increasing dependence on internet-based services, data has attained prominence as an essential currency supporting market power. This paper examines the emerging jurisprudence on excessive data collection by dominant digital platforms, comparing approaches developed in India and the European Union. The Indian approach, exemplified by the WhatsApp Privacy (2025) decision, integrates competition law with constitutional protections, particularly the right to privacy under Article 21 of the Indian Constitution. Meanwhile, the European approach, crystallized in the Facebook Germany case, integrates competition law with data protection principles enshrined in the General Data Protection Regulation (GDPR). Despite their different legal foundations, these approaches display convergence in recognizing that dominant platforms’ data collection practices can constitute abusive exploitation of market power. This paper argues that this convergence creates opportunities for a unified analytical framework that respects jurisdictional diversity while enabling more effective global platform regulation…(More)”.
Paper by Daniel Thilo Schroeder et al: “Advances in artificial intelligence (AI) offer the prospect of manipulating beliefs and behaviors on a population-wide level. Large language models (LLMs) and autonomous agents let influence campaigns reach unprecedented scale and precision. Generative tools can expand propaganda output without sacrificing credibility and inexpensively create falsehoods that are rated as more human-like than those written by humans. Techniques meant to refine AI reasoning, such as chain-of-thought prompting, can be used to generate more convincing falsehoods. Enabled by these capabilities, a disruptive threat is emerging: swarms of collaborative, malicious AI agents. Fusing LLM reasoning with multiagent architectures, these systems are capable of coordinating autonomously, infiltrating communities, and fabricating consensus efficiently. By adaptively mimicking human social dynamics, they threaten democracy. Because the resulting harms stem from design, commercial incentives, and governance, we prioritize interventions at multiple leverage points, focusing on pragmatic mechanisms over voluntary compliance…(More)”.
Article by EIT Urban Mobility: “Cities want to improve urban mobility for residents and achieve their urgent climate goals, but with a dizzying array of possibilities and local constraints, how can local authorities make sure they invest in solutions that respond to users’ real needs? More than that, how can they respond to residents’ true behaviours, not just their reported ones?
Whether it’s winning public trust in the shift to autonomous transport or supporting local communities to be less dependent on cars, citizen engagement puts local communities at the centre of urban transformation, enabling residents to define their unique needs. …
Take the city of Nantes in western France. The city’s urban development agency Samoa wanted to make it easier for people to get around without a car when cycling would not be an option; for those with reduced mobility or in the instances of transporting heavy items, for example.
Supported by EIT Urban Mobility’s RAPTOR programme, Samoa worked with active mobility startup Sanka Cycle to pilot its electric-assisted ‘BOB’ light vehicle to see if and how it could be deployed to replace traditional internal combustion vehicle trips.
In collaboration with urban change agency Humankind, the project deployed citizen engagement tools to better understand how users perceived the light vehicle’s value and what motivators or barriers could influence its acceptance.
Through a mix of field observations with in-depth and flash interviews Samoa and Sanka Cycle were able to gain valuable insights into how people saw the BOB vehicles in comparison to other forms of mobility in order to explore how it might be able to act as a bridge between cars and bicycles. …
Citizen engagement is increasingly gaining traction as a key tool in supporting the shift to sustainable urban mobility.
For the Interact project, which developed a Human Machine Interface (eHMI) for automated public transport buses, communication and trust with passengers was central for successful and ethical deployment. The core challenge however was when the safety driver was removed from the buses, the soft skills drivers bring to their role and their communication with passengers would also be removed. Therefore, learning more about how passengers felt about safety and trust was essential for making this new form of sustainable mobility socially acceptable.
Thus, Interact implemented citizen engagement with Humankind through on-site research and guerilla testing, observations and interviews, and a digital survey in the pilot sites of Rotterdam, the Netherlands, and Stavanger, Norway. The activity engaged both passengers and safety drivers through interviews to capture their unique perspectives. Important lessons were also learned about the nuances of how people felt about the technology.
In Stavanger, for instance, passengers raised concerns about how extreme weather would impact the system and brought up past experiences with automated systems failing as temperatures dropped. ..(More)”.
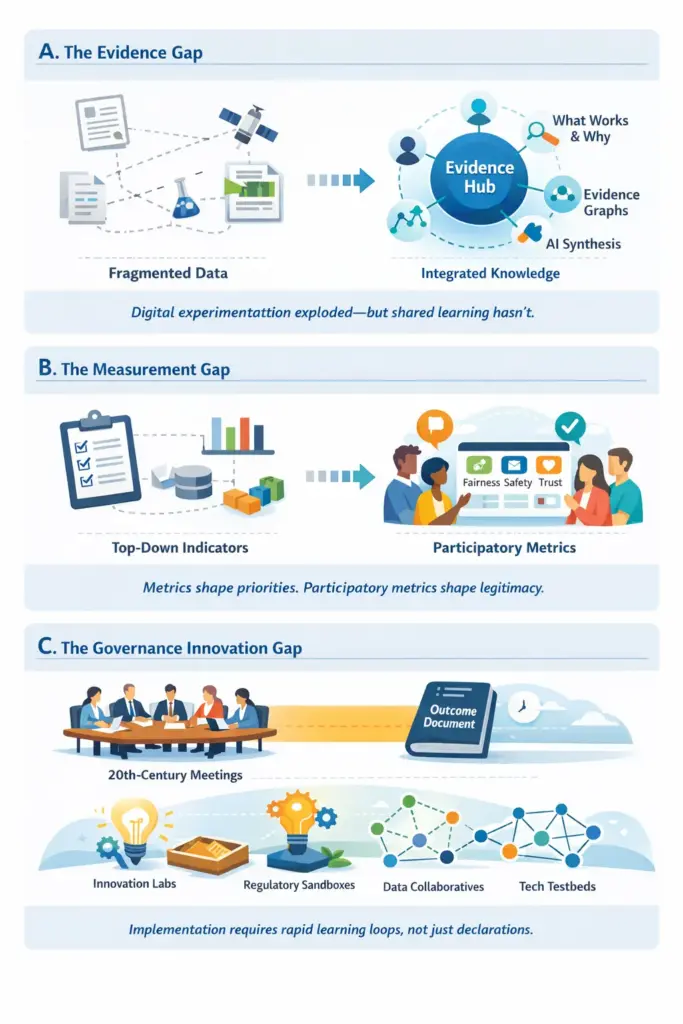
Article by Lea Kaspar and Stefaan G. Verhulst: “As the dust settles on the World Summit on the Information Society (WSIS) 20-year Review, observers are once again asking what the final outcome document—adopted by consensus on 17 December 2025—really delivers. Much like the WSIS+10 review a decade earlier, negotiations were characterized by pragmatism rather than ambition and by a desire to preserve the WSIS framework amid a radically altered technological landscape. And, as in previous cycles, the most critical questions were pushed to the margins in the final days of negotiation, leaving implementation—not text—as the arena where credibility will be tested.
Whether WSIS remains a living framework for digital cooperation—or recedes into diplomatic ritual—will depend less on consensus language and more on the ability of governments, civil society, researchers, and private actors to translate commitments into accountable practice.
This was the core point emphasized during the WSIS+20 High-Level Event intervention: legitimacy in digital governance is not earned by adoption, but by delivery. Participation, rights-anchoring, and accountability are needed at every stage of implementation—not just during negotiation.
Yet twenty years after Geneva and Tunis, the WSIS process still relies on a governance and operational model conceived for another era. The world now operates in a datafied, AI-augmented environment defined by real-time systems, cross-border infrastructures, and unprecedented concentration of digital power. The question is not whether WSIS principles remain relevant—they do—but whether the mechanisms used to operationalize them are fit for purpose.
Below, we’ll outline the same core challenges and opportunities we identified a decade ago, but updated with the realities, tools, and governance needs of 2026…(More)”