Stefaan Verhulst
Open Corporates: “…there are three other aspects which are relevant when talking about access to EU company data.
Cargo-culting GDPR
The first, is a tendency to take this complex and subtle legislation that is GDPR and use a poorly understood version in other legislation and regulation, even if that regulation is already covered by GDPR. This actually undermines the GDPR regime, and prevents it from working effectively, and should strongly be resisted. In the tech world, such approaches are called ‘cargo-culting’.
Similarly GDPR is often used as an excuse for not releasing company information as open data, even when the same data is being sold to third parties apparently without concerns — if one is covered by GDPR, the other certainly should be.
Widened power asymmetries
The second issue is the unintended consequences of GDPR, specifically the way it increases asymmetries of power and agency. For example, something like the so-called Right To Be Forgotten takes very significant resources to implement, and so actually strengthens the position of the giant tech companies — for such companies, investing millions in large teams to decide who should and should not be given the Right To Be Forgotten is just a relatively small cost of doing business.
Another issue is the growth of a whole new industry dedicated to removing traces of people’s past from the internet (2), which is also increasing the asymmetries of power. The vast majority of people are not directors of companies, or beneficial owners, and it is only the relatively rich and powerful (including politicians and criminals) who can afford lawyers to stifle free speech, or remove parts of their past they would rather not be there, from business failures to associations with criminals.
OpenCorporates, for example, was threatened with a lawsuit from a member of one of the wealthiest families in Europe for reproducing a gazette notice from the Luxembourg official gazette (a publication that contains public notices). We refused to back down, believing we had a good case in law and in the public interest, and the other side gave up. But such so-called SLAPP suits are becoming increasingly common, although unlike many US states there are currently no defences in place to resist these in the EU, despite pressure from civil society to address this….
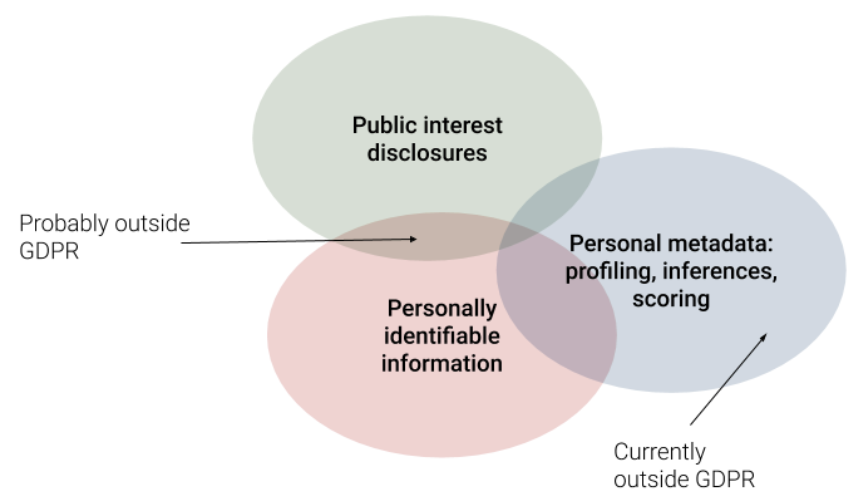
At the same time, the automatic assumption that all Personally Identifiable Information (PII), someone’s name for example, is private is highly problematic, confusing both citizens and policy makers, and further undermining democracies and fair societies. As an obvious case, it’s critical that we know the names of our elected representatives, and those in positions of power, otherwise we would have an opaque society where decisions are made by nameless individuals with opaque agendas and personal interests — such as a leader awarding a contract to their brother’s company, for example.
As the diagram below illustrates, there is some personally identifiable information that it’s strongly in the public interest to know. Take the director or beneficial owner of a company, for example, of course their details are PII — clearly you need to know their name (and other information too), otherwise what actually do you know about them, or the company (only that some unnamed individual has been given special protection under law to be shielded from the company’s debts and actions, and yet can benefit from its profits)?
On the other hand, much of the data which is truly about our privacy — the profiles, inferences and scores that companies store on us — is explicitly outside GDPR, if it doesn’t contain PII.
Hopefully, as awareness of the issues increases, we will develop a more nuanced, deeper, understanding of privacy, such that case law around GDPR, and successors to this legislation begin to rebalance and case law starts to bring clarity to the ambiguities of the GDPR….(More)”.
European Society of Cardiology: “Sending a “selfie” to the doctor could be a cheap and simple way of detecting heart disease, according to the authors of a new study published today (Friday) in the European Heart Journal [1].
The study is the first to show that it’s possible to use a deep learning computer algorithm to detect coronary artery disease (CAD) by analysing four photographs of a person’s face.
Although the algorithm needs to be developed further and tested in larger groups of people from different ethnic backgrounds, the researchers say it has the potential to be used as a screening tool that could identify possible heart disease in people in the general population or in high-risk groups, who could be referred for further clinical investigations.
“To our knowledge, this is the first work demonstrating that artificial intelligence can be used to analyse faces to detect heart disease. It is a step towards the development of a deep learning-based tool that could be used to assess the risk of heart disease, either in outpatient clinics or by means of patients taking ‘selfies’ to perform their own screening. This could guide further diagnostic testing or a clinical visit,” said Professor Zhe Zheng, who led the research and is vice director of the National Center for Cardiovascular Diseases and vice president of Fuwai Hospital, Chinese Academy of Medical Sciences and Peking Union Medical College, Beijing, People’s Republic of China.
He continued: “Our ultimate goal is to develop a self-reported application for high risk communities to assess heart disease risk in advance of visiting a clinic. This could be a cheap, simple and effective of identifying patients who need further investigation. However, the algorithm requires further refinement and external validation in other populations and ethnicities.”
It is known already that certain facial features are associated with an increased risk of heart disease. These include thinning or grey hair, wrinkles, ear lobe crease, xanthelasmata (small, yellow deposits of cholesterol underneath the skin, usually around the eyelids) and arcus corneae (fat and cholesterol deposits that appear as a hazy white, grey or blue opaque ring in the outer edges of the cornea). However, they are difficult for humans to use successfully to predict and quantify heart disease risk.
Prof. Zheng, Professor Xiang-Yang Ji, who is director of the Brain and Cognition Institute in the Department of Automation at Tsinghua University, Beijing, and other colleagues enrolled 5,796 patients from eight hospitals in China to the study between July 2017 and March 2019. The patients were undergoing imaging procedures to investigate their blood vessels, such as coronary angiography or coronary computed tomography angiography (CCTA). They were divided randomly into training (5,216 patients, 90%) or validation (580, 10%) groups.
Trained research nurses took four facial photos with digital cameras: one frontal, two profiles and one view of the top of the head. They also interviewed the patients to collect data on socioeconomic status, lifestyle and medical history. Radiologists reviewed the patients’ angiograms and assessed the degree of heart disease depending on how many blood vessels were narrowed by 50% or more (≥ 50% stenosis), and their location. This information was used to create, train and validate the deep learning algorithm….(More)”.
Hye Jung Han at Politico: “…Education systems across Europe struggled this year with how to determine students’ all-important final grades. But one system, the International Baccalaureate (“IB”) — a high school program that is highly regarded by European universities, and offered by both public and private schools in 152 countries — did something unusual.
Having canceled final exams, which make up the majority of an IB student’s grade, the Geneva-based foundation of the same name hastily built an algorithm that used a student’s coursework scores, predicted grades by teachers and their school’s historical IB results to guess what students might have scored if they had taken their exams in a hypothetical, pandemic-free year. The result of the algorithm became the student’s final grade.
The results were catastrophic. Soon after the grades were released, serious mismatches emerged between expected grades based on a student’s prior performance, and those awarded by the algorithm. Because IB students’ university admissions are contingent upon their final grades, the unexpectedly poor grades generated for some resulted in scholarships and admissions offers being revoked…
The IB had alternatives. Instead, it could have used students’ actual academic performance and graded on a generous curve. It could have incorporated practice test grades, third-party moderation to minimize grading bias and teachers’ broad evaluations of student progress.
It could have engaged with universities on flexibly factoring in final grades into this year’s admissions decisions, as universities contemplate opening their now-virtual classes to more students to replace lost revenue.
It increasingly seems like the greatest potential of the power promised by predictive data lies in the realm of misuse.
For this year’s graduating class, who have already responded with grace and resilience in their final year of school, the automating away of their capacity and potential is an unfair and unwanted preview of the world they are graduating into….(More)”.
Daria Litvinova at AP News: “Every day, like clockwork, to-do lists for those protesting against Belarus’ authoritarian leader appear in the popular Telegram messaging app. They lay out goals, give times and locations of rallies with business-like precision, and offer spirited encouragement.
“Today will be one more important day in the fight for our freedom. Tectonic shifts are happening on all fronts, so it’s important not to slow down,” a message in one of Telegram’s so-called channels read Tuesday. “Morning. Expanding the strike … 11:00. Supporting the Kupala (theater) … 19:00. Gathering at the Independence Square.”
The app has become an indispensable tool in coordinating the unprecedented mass protests that have rocked Belarus since Aug. 9, when election officials announced President Alexander Lukashenko had won a landslide victory to extend his 26-year rule in a vote widely seen as rigged.
Peaceful protesters who poured into the streets of the capital, Minsk, and other cities were met with stun grenades, rubber bullets and beatings from police. The opposition candidate left for Lithuania — under duress, her campaign said — and authorities shut off the internet, leaving Belarusians with almost no access to independent online news outlets or social media and protesters seemingly without a leader.
That’s where Telegram — which often remains available despite internet outages, touts the security of messages shared in the app and has been used in other protest movements — came in. Some of its channels helped scattered rallies to mature into well-coordinated action.
The people who run the channels, which used to offer political news, now post updates, videos and photos of the unfolding turmoil sent in from users, locations of heavy police presence, contacts of human rights activists, and outright calls for new demonstrations — something Belarusian opposition leaders have refrained from doing publicly themselves. Tens of thousands of people all across the country have responded to those calls.
In a matter of days, the channels — NEXTA, NEXTA Live and Belarus of the Brain are the most popular — have become the main method for facilitating the protests, said Franak Viacorka, a Belarusian analyst and non-resident fellow at the Atlantic Council….(More)”.
Paper by Ajay Chawla and Sandra Ro: “The COVID-19 pandemic has impacted virtually all businesses, but the effect has not been stable yet. While the current disruption may present challenges to the blockchain industry in the short term, it will also unlock new opportunities in the mid and longer-term. By providing help in the COVID-19 crisis and recovery, blockchain can play a pivotal role in accelerating post-crisis digital transformation initiatives and solving those problems highlighted in the current system.
Of course, no one could have foreseen the unprecedented upheaval caused by the novel coronavirus (COVID-19) pandemic which has almost disrupted and dislocated economies and ecosystems across the planet but COVID-19 has brought supply chains to their knees.
Nevertheless, there are some bright spots where blockchain is used to combat the effects of COVID-19 and aid in the recovery process. These innovative use cases can demonstrate the benefits of blockchain to a wider audience.
Organizations including the World Health Organisation (WHO), Oracle, Microsoft, IBM, among other tech companies, government agencies, and international bodies are all working together to develop the blockchain-based platforms and solutions.
Blockchain technology is anchored by its ability to enable decentralized sharing of verified, trusted, and secure information among individuals or organizations. Furthermore, it can be paired with critical security and cryptography to protect the privacy of the users and individuals contributing data while still providing provenance and trust in the shared data.
By providing help in the COVID-19 crisis and recovery, blockchain can play a pivotal role in accelerating post-crisis digital transformation initiatives and solving those problems highlighted in the current system.
However, at the present moment, blockchain is not the panacea of all the problems. While the promise and potential of blockchain are undoubtedly transformative, it is still in the nascence of its evolution.
Keeping a tab on this technology and our capacities is the right direction we can head towards….(More)”.
White Paper by Phoebe Higgins & Timothy Male: “Late in 2017, the United Kingdom’s energy regulator, Ofgem, gave fast approval for a new project allowing residents to buy and sell renewable energy from solar panels and batteries within their own apartment buildings. Normally, this would not be legal since UK energy rules dictate that locally generated energy can only be used by the owner or sold back to the grid at a relatively low price. However, the earlier establishment of a regulatory sandbox for such energy delivery modernizations created a path to try something new and get it approved quickly. In April 2018, only a few months after project initiation, the first peer-to-peer energy trades within apartment complexes started.
Energy policy is not the only space where rules need fast modification to make allowances for all the novelty arising in the world today. The protection and restoration of our water, healthy soil and wildlife resources are static processes, starved for creativity. A United Nations’ panel recently reported on the extinction risks that face more than one million species around the globe. In a 2009 National Rivers and Streams Assessment, the EPA reported that 46 percent of U.S. waterways were in ‘poor’ biological condition, and more than 40 percent were polluted with high levels of nitrogen or phosphorus.
Innovators have big ideas that could help with these problems, but ponderous regulatory systems and older generations of bureaucrats aren’t used to the fast pace of new technologies, tools and products. Often, it is a simple thing—one word or phrase in a policy or regulation—that is a barrier to a new technology or technique being widely used. However, one sentence can be just as hard and slow to change as a whole law. Rather than simply accept this regulatory status quo, we believe in the need to find, nurture and learn from new concepts even when it means deliberately
breaking old rules.
Regulatory sandboxes like the one in the United Kingdom open the door to testing new approaches within a controlled environment. While they don’t ensure success, they make it possible for new technologies and tools to be explored in real-world settings. Not just so that innovators can learn, but also to allow government bureaucracies to catch up to the present and adapt to the future. Our planet and country need more opportunities to do this….(More)“
Book edited by Maria Tzanou: “The growth of data collecting goods and services, such as ehealth and mhealth apps, smart watches, mobile fitness and dieting apps, electronic skin and ingestible tech, combined with recent technological developments such as increased capacity of data storage, artificial intelligence and smart algorithms have spawned a big data revolution that has reshaped how we understand and approach health data. Recently the COVID-19 pandemic has foregrounded a variety of data privacy issues. The collection, storage, sharing and analysis of health- related data raises major legal and ethical questions relating to privacy, data protection, profiling, discrimination, surveillance, personal autonomy and dignity.
This book examines health privacy questions in light of the GDPR and the EU’s general data privacy legal framework. The GDPR is a complex and evolving body of law that aims to deal with several technological and societal health data privacy problems, while safeguarding public health interests and addressing its internal gaps and uncertainties. The book answers a diverse range of questions including: What role can the GDPR play in regulating health surveillance and big (health) data analytics? Can it catch up with the Internet age developments? Are the solutions to the challenges posed by big health data to be found in the law? Does the GDPR provide adequate tools and mechanisms to ensure public health objectives and the effective protection of privacy? How does the GDPR deal with data that concern children’s health and academic research?
By analysing a number of diverse questions concerning big health data under the GDPR from various different perspectives, this book will appeal to those interested in privacy, data protection, big data, health sciences, information technology, the GDPR, EU and human rights law….(More)”.
Andrew Young and Stefaan Verhulst at The Palgrave Encyclopedia of Interest Groups, Lobbying and Public Affairs: “The rise of the open data movement means that a growing amount of data is today being broken out of information silos and released or shared with third parties. Yet despite the growing accessibility of data, there continues to exist a mismatch between the supply of, and demand for, data (Verhulst & Young, 2018). This is because supply and demand are often widely dispersed – spread across government, the private sector, and civil society – meaning that those who need data do not know where to find it, and those who release data do not know how to effectively target it at those who can most effectively use it (Susha, Janssen, & Verhulst, 2017). While much commentary on the data era’s shortcomings focuses on issues such as data glut (Buchanan & Kock, 2001), misuse of data (Solove & Citron, 2017), or algorithmic bias (Hajian, Bonchi, & Castillo, 2016), this mismatch between supply and demand is at least equally problematic, resulting in tremendous inefficiencies and lost potential.
Data collaboratives, when designed responsibly (Alemanno, 2018), can help to address such shortcomings. They draw together otherwise siloed data – such as, for example, telecom data, satellite imagery, social media data, financial data – and a dispersed range of expertise. In the process, they help match supply and demand, and ensure that the appropriate institutions and individuals are using and analyzing data in ways that maximize the possibility of new, innovative social solutions (de Montjoye, Gambs, Blondel, et al., 2018)….(More)”.
The Editorial Board at the Financial Times: “The soundtrack of school students marching through Britain’s streets shouting “f*** the algorithm” captured the sense of outrage surrounding the botched awarding of A-level exam grades this year. But the students’ anger towards a disembodied computer algorithm is misplaced. This was a human failure. The algorithm used to “moderate” teacher-assessed grades had no agency and delivered exactly what it was designed to do.
It is politicians and educational officials who are responsible for the government’s latest fiasco and should be the target of students’ criticism….
Sensibly designed, computer algorithms could have been used to moderate teacher assessments in a constructive way. Using past school performance data, they could have highlighted anomalies in the distribution of predicted grades between and within schools. That could have led to a dialogue between Ofqual, the exam regulator, and anomalous schools to come up with more realistic assessments….
There are broader lessons to be drawn from the government’s algo fiasco about the dangers of automated decision-making systems. The inappropriate use of such systems to assess immigration status, policing policies and prison sentencing decisions is a live danger. In the private sector, incomplete and partial data sets can also significantly disadvantage under-represented groups when it comes to hiring decisions and performance measures.
Given the severe erosion of public trust in the government’s use of technology, it might now be advisable to subject all automated decision-making systems to critical scrutiny by independent experts. The Royal Statistical Society and The Alan Turing Institute certainly have the expertise to give a Kitemark of approval or flag concerns.
As ever, technology in itself is neither good nor bad. But it is certainly not neutral. The more we deploy automated decision-making systems, the smarter we must become in considering how best to use them and in scrutinising their outcomes. We often talk about a deficit of trust in our societies. But we should also be aware of the dangers of over-trusting technology. That may be a good essay subject for next year’s philosophy A-level….(More)”.
About: “Landlord Tech—what the real estate industry describes as residential property technology, is leading to new forms of housing injustice. Property technology, or “proptech,” has grown dramatically since 2008, and applies to residential, commercial, and industrial buildings, effectively merging the real estate, technology, and finance industries. By employing digital surveillance, data collection, data accumulation, artificial intelligence, dashboards, and platform real estate in tenant housing and neighborhoods, Landlord Tech increases the power of landlords while disempowering tenants and those seeking shelter.
There are few laws and regulations governing the collection and use of data in the context of Landlord Tech. Because it is generally sold to landlords and property managers, not tenants, Landlord Tech is often installed without notifying or discussing potential harms with tenants and community members. These harms include the possibility that sensitive and personal data can be handed over to the police, ICE, or other law enforcement and government agencies. Landlord Tech can also be used to automate evictions, racial profiling, and tenant harassment. In addition, Landlord Tech is used to abet real estate speculation and gentrification, making buildings more desirable to whiter and wealthier tenants, while feeding real estate and tech companies with property – be that data or real estate. Landlord Tech tracking platforms have increasingly been marketed to landlords as solutions to Covid-19, leading to new forms of residential surveillance….(More)”.