Stefaan Verhulst
Jory Heckman at Federal News Network: “The Foundations for Evidence-Based Policymaking Act has ordered agencies to share their datasets internally and with other government partners — unless, of course, doing so would break the law.
Nearly a year after President Donald Trump signed the bill into law, agencies still have only a murky idea of what data they can share, and with whom. But soon, they’ll have more nuanced options of ranking the sensitivity of their datasets before sharing them out to others.
Chief Statistician Nancy Potok said the Office of Management and Budget will soon release proposed guidelines for agencies to provide “tiered” access to their data, based on the sensitivity of that information….
OMB, as part of its Evidence Act rollout, will also rethink how agencies ensure protected access to data for research. Potok said agency officials expect to pilot a single application governmentwide for people seeking access to sensitive data not available to the public.
The pilot resembles plans for a National Secure Data Service envisioned by the Commission on Evidence-Based Policymaking, an advisory group whose recommendations laid the groundwork for the Evidence Act.
“As a state-of-the-art resource for improving government’s capacity to use the data it already collects, the National Secure Data Service will be able to temporarily link existing data and provide secure access to those data for exclusively statistical purposes in connection with approved projects,” the commission wrote in its 2017 final report.
In an effort to strike a balance between access and privacy, Potok said OMB has also asked agencies to provide a list of the statutes that prohibit them from sharing data amongst themselves….(More)”.
Report by Marianna Mazucatto: “This report, Governing Missions, looks at the ‘how’: how to implement and govern a mission-oriented process so that it unleashes the full creativity and ambition potential of R&I policy-making; and how it crowds-in investments from across Europe in the process. The focus is on 3 key questions:
- How to engage citizens in codesigning, co-creating, co-implementing
and co-assessing missions? - What are the public sector capabilities and instruments needed to foster a dynamic innovation ecosystem, including the ability of civil servants to welcome experimentation and help governments work outside silos?
- How can mission-oriented finance and funding leverage and crowd-in other forms of finance, galvanising innovation across actors (public, private and third sector), different manufacturing and service sectors, and across national and transnational levels?…(More)”.
Report by Eduardo Laguna-Muggenburg, Shreyan Sen and Eric Lewandowski: “Urbanization processes in the developing world are often associated with the creation of informal settlements. These areas frequently have few or no public services exacerbating inequality even in the context of substantial economic growth.
In the past, the high costs of gathering data through traditional surveying methods made it challenging to study how these under-served areas evolve through time and in relation to the metropolitan area to which they belong. However, the advent of mobile phones and smartphones in particular presents an opportunity to generate new insights on these old questions.
In June 2019, Orbital Insight and the United Nations Development Programme (UNDP) Arab States Human Development Report team launched a collaborative pilot program assessing the feasibility of using geolocation data to understand patterns of life among the urban poor in Cairo, Egypt.
The objectives of this collaboration were to assess feasibility (and conditionally pursue preliminary analysis) of geolocation data to create near-real time population density maps, understand where residents of informal settlements tend to work during the day, and to classify universities by percentage of students living in informal settlements.
The report is organized as follows. In Section 2 we describe the data and its limitations. In Section 3 we briefly explain the methodological background. Section 4 summarizes the insights derived from the data for the Egyptian context. Section 5 concludes….(More)”.
Paper by Chad G. Marzen: “In the wake of the 2013 United States Supreme Court decision of McBurney v. Young (569 U.S. 221), this Article calls for policymakers at the federal and state levels to ensure governmental records remain open and accessible to the public. It urges policymakers to call not only for strengthening of the Freedom of Information Act and the various state public records law, but to pursue an amendment to the United States Constitution providing a right to public information.
This Article proposes a draft of such an amendment:
The right to public information, being a necessary and vital part of democracy, shall be a fundamental right of the people. The right of the people to inspect and/or copy records of government, and to be provided notice of and attend public meetings of government, shall not unreasonably be restricted.
This Article analyzes the benefits of the amendment and concludes the enshrining of the right to public information in both the United States Constitution as well as various state constitutions will ensure greater access of public records and documents to the general public, consistent with the democratic value of open, transparent government….(More)”.
UK Policy Lab: “Open justice is the principle that ‘justice should not only be done, but should manifestly and undoubtedly be seen to be done’(1). It is a very well established principle within our justice system, however new digital tools and approaches are creating new opportunities and potential challenges which necessitate significant rethinking on how open justice is delivered.
In this context, HM Courts & Tribunal Service (HMCTS) wanted to consider how the principle of open justice should be delivered in the future. As well as seeking input from those who most commonly work with courtrooms, like judges, court staff and legal professionals, they also wanted to explore a range of public views. HMCTS asked us to create a methodology which could spark a wide-ranging conversation about open justice, collecting diverse and divergent perspectives….
We approached this challenge by using speculative design to explore possible and desirable futures with citizens. In this blog we will share what we did (including how you can re-use our materials and approach), what we’ve learned, and what we’ll be experimenting with from here.
What we did
We ran 4 groups of 10 to 12 participants each. We spent the first 30 minutes discussing what participants understood and thought about Open Justice in the present. We spent the next 90 minutes using provocations to immerse them in a range of fictional futures, in which the justice system is accessed through a range of digital platforms.
The provocations were designed to:
- engage even those with no prior interest, experience or knowledge of Open Justice
- be reusable
- not look like ‘finished’ government policy – we wanted to find out more about desirable outcomes
- as far as possible, provoke discussion without leading
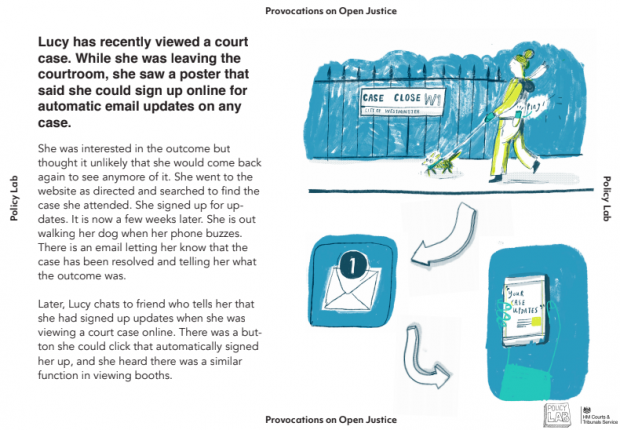
Using provocations to help participants think about the future allowed us to distill common principles which HMCTS can use when designing specific delivery mechanisms.
We hope the conversation can continue. HMCTS have published the provocations on their website. We encourage people to reuse them, or to use them to create their own….(More)”.
Paper by Maria Savona: “This note attempts a systematisation of different pieces of literature that underpin the recent policy and academic debate on the value of data. It mainly poses foundational questions around the definition, economic nature and measurement of data value, and discusses the opportunity to redistribute it. It then articulates a framework to compare ways of implementing redistribution, distinguishing between data as capital, data as labour or data as an intellectual property. Each of these raises challenges, revolving around the notions of data property and data rights, that are also briefly discussed. The note concludes by indicating areas for policy considerations and a research agenda to shape the future structure of data governance more at large….(More)”.
Vincent Duclos in Medicine Anthropology Theory: “In the last few years, tracking systems that harvest web data to identify trends, calculate predictions, and warn about potential epidemic outbreaks have proliferated. These systems integrate crowdsourced data and digital traces, collecting information from a variety of online sources, and they promise to change the way governments, institutions, and individuals understand and respond to health concerns. This article examines some of the conceptual and practical challenges raised by the online algorithmic tracking of disease by focusing on the case of Google Flu Trends (GFT). Launched in 2008, GFT was Google’s flagship syndromic surveillance system, specializing in ‘real-time’ tracking of outbreaks of influenza. GFT mined massive amounts of data about online search behavior to extract patterns and anticipate the future of viral activity. But it did a poor job, and Google shut the system down in 2015. This paper focuses on GFT’s shortcomings, which were particularly severe during flu epidemics, when GFT struggled to make sense of the unexpected surges in the number of search queries. I suggest two reasons for GFT’s difficulties. First, it failed to keep track of the dynamics of contagion, at once biological and digital, as it affected what I call here the ‘googling crowds’. Search behavior during epidemics in part stems from a sort of viral anxiety not easily amenable to algorithmic anticipation, to the extent that the algorithm’s predictive capacity remains dependent on past data and patterns. Second, I suggest that GFT’s troubles were the result of how it collected data and performed what I call ‘epidemic reality’. GFT’s data became severed from the processes Google aimed to track, and the data took on a life of their own: a trackable life, in which there was little flu left. The story of GFT, I suggest, offers insight into contemporary tensions between the indomitable intensity of collective life and stubborn attempts at its algorithmic formalization.Vincent DuclosIn the last few years, tracking systems that harvest web data to identify trends, calculate predictions, and warn about potential epidemic outbreaks have proliferated. These systems integrate crowdsourced data and digital traces, collecting information from a variety of online sources, and they promise to change the way governments, institutions, and individuals understand and respond to health concerns. This article examines some of the conceptual and practical challenges raised by the online algorithmic tracking of disease by focusing on the case of Google Flu Trends (GFT). Launched in 2008, GFT was Google’s flagship syndromic surveillance system, specializing in ‘real-time’ tracking of outbreaks of influenza. GFT mined massive amounts of data about online search behavior to extract patterns and anticipate the future of viral activity. But it did a poor job, and Google shut the system down in 2015. This paper focuses on GFT’s shortcomings, which were particularly severe during flu epidemics, when GFT struggled to make sense of the unexpected surges in the number of search queries. I suggest two reasons for GFT’s difficulties. First, it failed to keep track of the dynamics of contagion, at once biological and digital, as it affected what I call here the ‘googling crowds’. Search behavior during epidemics in part stems from a sort of viral anxiety not easily amenable to algorithmic anticipation, to the extent that the algorithm’s predictive capacity remains dependent on past data and patterns. Second, I suggest that GFT’s troubles were the result of how it collected data and performed what I call ‘epidemic reality’. GFT’s data became severed from the processes Google aimed to track, and the data took on a life of their own: a trackable life, in which there was little flu left. The story of GFT, I suggest, offers insight into contemporary tensions between the indomitable intensity of collective life and stubborn attempts at its algorithmic formalization….(More)”.
Claire Gamage at Challenging Procurement: “…in an era where demand for public sector services increases as budgets decrease, the public sector should start to consider alternative routes to procurement. …
What is the Innovation Partnership procedure?
In a nutshell, it is essentially a procurement process combined with an R&D contract. Authorities are then able to purchase the ‘end result’ of the R&D exercise, without having to undergo a new procurement procedure. Authorities may choose to appoint a number of partners to participate in the R&D phase, but may subsequently only purchase one/some of those solutions.
Why does this procedure result in more innovative solutions?
The procedure was designed to drive innovation. Indeed, it may only be used in circumstances where a solution is not already available on the open market. Therefore, participants in the Innovation Partnership will be asked to create something which does not already exist and should be tailored towards solving a particular problem or ‘challenge’ set by the authority.
This procedure may also be particularly attractive to SMEs/start-ups, who often find it easier to innovate in comparison with their larger competitors and therefore the purchasing authority is perhaps likely to obtain a more innovative product or service.
One of the key advantages of an Innovation Partnership is that the R&D phase is separate to the subsequent purchase of the solution. In other words, the authority is not (usually) under any obligation to purchase the ‘end result’ of the R&D exercise, but has the option to do so if it wishes. Therefore, it may be easier to discourage internal stakeholders from imposing selection criteria which inadvertently exclude SMEs/start-ups (e.g. minimum turnover requirements, parent company guarantees etc.), as the authority is not committed to actually purchasing at the end of the procurement process which will select the innovation partner(s)….(More)”.
About: “The Urban Computing Foundation is a neutral forum for accelerating open source and community development that improves mobility, safety, road infrastructure, traffic congestion and energy consumption in connected cities.
As cities and transportation networks evolve into ever-more complicated systems, urban computing is emerging as an important field to bridge the divide between engineering, visualization, and traditional transportation systems analysis. These advancements are dependent on compatibility among many technologies across different public and private organizations. The Foundation provides the forum to collaborate on a common set of open source tools for developers building autonomous vehicles and smart infrastructure.
The Urban Computing Foundation’s mission is to enable developers, data scientists, visualization specialists and engineers to improve urban environments, human life quality, and city operation systems.build connected urban infrastructure. We do this through an open governance model that encourages participation and technical contribution, and by providing a framework for long term stewardship by companies and individuals invested in open urban computing’s success….(More)”.
Paper by Nicholas Economides and Ioannis Lianos: “The recent controversy on the intersection of competition law with the protection of privacy, following the emergence of big data and social media is a major challenge for competition authorities worldwide. Recent technological progress in data analytics may greatly facilitate the prediction of personality traits and attributes from even a few digital records of human behaviour.
There are different perspectives globally as to the level of personal data protection and the role competition law may play in this context, hence the discussion of integrating such concerns in competition law enforcement may be premature for some jurisdictions. However, a market failure approach may provide common intellectual foundations for the assessment of harms associated to the exploitation of personal data, even when the specific legal system does not formally recognize a fundamental right to privacy.
The paper presents a model of market failure based on a requirement provision in the acquisition of personal information from users of other products/services. We establish the economic harm from the market failure and the requirement using the traditional competition law toolbox and focusing more on situations in which the restriction on privacy may be analysed as a form of exploitation. Eliminating the requirement and the market failure by creating a functioning market for the sale of personal information is imperative. This emphasis on exploitation does not mean that restrictions on privacy may not result from exclusionary practices. However, we analyse this issue in a separate study.
Besides the traditional analysis of the requirement and market failure, we note that there are typically informational asymmetries between the data controller and the data subject. The latter may not be aware that his data was harvested, in the first place, or that the data will be processed by the data controller for a different purpose or shared and sold to third parties. The exploitation of personal data may also result from economic coercion, on the basis of resource-dependence or lock-in of the user, the latter having no other choice, in order to enjoy the consumption of a specific service provided by the data controller or its ecosystem, in particular in the presence of dominance, than to consent to the harvesting and use of his data. A behavioural approach would also emphasise the possible internalities (demand-side market failures) coming out of the bounded rationality, or the fact that people do not internalise all consequences of their actions and face limits in their cognitive capacities.
The paper also addresses the way competition law could engage with exploitative conduct leading to privacy harm, both for ex ante and ex post enforcement.
With regard to ex ante enforcement, the paper explores how privacy concerns may be integrated in merger control as part of the definition of product quality, the harm in question being merely exploitative (the possibility the data aggregation provides to the merged entity to exploit (personal) data in ways that harm directly consumers), rather than exclusionary (harming consumers by enabling the merged entity to marginalise a rival with better privacy policies), which is examined in a separate paper.
With regard to ex post enforcement, the paper explores different theories of harm that may give rise to competition law concerns and suggest specific tests for their assessment. In particular, we analyse old and new exploitative theories of harm relating to excessive data extraction, personalised pricing, unfair commercial practices and trading conditions, exploitative requirement contracts, behavioural manipulation.
We are in favour of collective action to restore the conditions of a well-functioning data market and the paper makes several policy recommendations….(More)”.