Stefaan Verhulst
Paper by Ricardo Zapata Lopera: “Since its beginnings, digital technologies have increased the enthusiasm for the realisation of political utopias about a society capable of achieving self-organisation and decentralised governance. The vision was initially brought to concrete technological developments in mid-century with the surge of cybernetics and the attempt to automatise public processes for a more efficient State, taking its most practical form with the Cybersyn Project between 1971-73. Contemporary developments of governance technologies have learned and leveraged particularly from the internet, the free software movement and the increasing micro-processing capacity to come up with more efficient solutions for collective decision-making, preserving, in most cases, the same ethos of “algorithmic regulation”. This essay examines how rational choice institutionalism has framed the scope of digital democracy, and how recent supporting technologies like blockchain have made more evident the objective of creating new institutional arrangements to overcome market failures and increasing inequality, without questioning the utility-maximisation logic. This rational logic of governance could explain the paradoxical movements towards centralisation and power concentration experienced by some of these technologies.
Digital democracy will be understood as a heterogeneous field that explores how digital tools and technologies are used in the practice of democracy (Simon, Bass & Mulgan, 2017). Its understanding needs to go in hand however with the use of supporting technologies and practices that amplify the role of the people in the public decision-making process, either by decentralisation (of public goods) or aggregation (of opinions), including blockchain, data processing (open data and big data), open government, and recent developments in civic tech (Knight Foundation, 2013). It must be noted that the use of digital democracy as a category to describe the use of these technologies to support democratic processes remains contended and requires further debate.
Dahlberg (2011) makes a useful characterisation of four common positions in digital democracy, where the ‘liberal-consumer’ and the ‘deliberative’ positions dominate mainstream thinking and practice, while other alternative positions (‘counter publics’ and ‘autonomous Marxist’) exist, but mostly in experimental or specific contexts. The liberal-consumer position conceives a self-sufficient, rational-strategic individual who acts in a competitive-aggregative democracy by “aggregating, calculating, choosing, competing, expressing, fundraising, informing, petitioning, registering, transacting, transmitting and voting” (p. 865). The deliberative subject is an inter-subjectively rational individual acting in a deliberative consensual democracy “agreeing, arguing, deliberating, disagreeing, informing, meeting, opinion forming, publicising, and reflecting” (p. 865).
Practice has been more homogeneous adopting the ‘liberal-consumer’ and ‘deliberative’ positions. Examples of the former include local and national government e-democracy initiatives; media politics sites, especially the ones providing ‘public opinion’ polling and ‘have your say’ comment systems; ‘independent’ e-democracy projects like mysociety.org; and civil society practices like Amnesty International’s digital campaigns, and online petitioning through sites like Change.org or Avaaz.org (Dahlberg, 2011, p. 858). On the other side, examples of the deliberative position include online government consultation projects (e.g. Your Priorities app and DemocracyOS.eu platform), writing and commentary of online citizen journalism in media sites; “online discussion forums of political interest groups; and the vast array of informal online debate on e-mail lists, web discussion boards, chat channels, blogs, social networking sites, and wikis” (p. 859). Recent developments not only include a mixture of both positions, but a more dynamic online-offline experience….
To shed a light on the understanding of this situation, it might be important to consider how rational choice institutionalism (RCI) explains the inherent logic of digital democracy. Rational choice institutionalism is a theoretical approach of ‘bounded rationality’, that is, it supposes rational utility-maximising actors playing in contexts constrained by institutions. According to Hall and Taylor (1996), this approach assumes rational actors to be incapable of reaching social optimal situations due to insufficient institutional configurations. The actors play strategic interactions in a configured scenario that affects “the range and sequence of alternatives on the choice-agenda or [provides] information and enforcement mechanisms that reduce uncertainty about the corresponding behaviour of others and allows ‘gains from exchange’, thereby leading actors toward particular calculations and potentially better social outcomes” (p. 945). RCI focuses on the reduction of transaction costs and the solution of the ‘principal-agent problem’, where “principals can monitor and enforce compliance on their agents” (p. 943)….(More)”.
MIT News: “India is on a path with dual — and potentially conflicting — goals related to the use of citizen data.
To improve the efficiency their municipal services, many Indian cities have started enabling government-service requests, which involves collecting and sharing citizen data with government officials and, potentially, the public. But there’s also a national push to protect citizen privacy, potentially restricting data usage. Cities are now beginning to question how much citizen data, if any, they can use to track government operations.
In a new study, MIT researchers find that there is, in fact, a way for Indian cities to preserve citizen privacy while using their data to improve efficiency.
The researchers obtained and analyzed data from more than 380,000 government service requests by citizens across 112 cities in one Indian state for an entire year. They used the dataset to measure each city government’s efficiency based on how quickly they completed each service request. Based on field research in three of these cities, they also identified the citizen data that’s necessary, useful (but not critical), or unnecessary for improving efficiency when delivering the requested service.
In doing so, they identified “model” cities that performed very well in both categories, meaning they maximized privacy and efficiency. Cities worldwide could use similar methodologies to evaluate their own government services, the researchers say. …(More)”.
Report by Philip Howard and Samantha Bradshaw: “…The report explores the tools, capacities, strategies and resources employed by global ‘cyber troops’, typically government agencies and political parties, to influence public opinion in 70 countries.
Key findings include:
- Organized social media manipulation has more than doubled since 2017, with 70 countries using computational propaganda to manipulate public opinion.
- In 45 democracies, politicians and political parties have used computational propaganda tools by amassing fake followers or spreading manipulated media to garner voter support.
- In 26 authoritarian states, government entities have used computational propaganda as a tool of information control to suppress public opinion and press freedom, discredit criticism and oppositional voices, and drown out political dissent.
- Foreign influence operations, primarily over Facebook and Twitter, have been attributed to cyber troop activities in seven countries: China, India, Iran, Pakistan, Russia, Saudi Arabia and Venezuela.
- China has now emerged as a major player in the global disinformation order, using social media platforms to target international audiences with disinformation.
- 25 countries are working with private companies or strategic communications firms offering a computational propaganda as a service.
- Facebook remains the platform of choice for social media manipulation, with evidence of formally organised campaigns taking place in 56 countries….
The report explores the tools and techniques of computational propaganda, including the use of fake accounts – bots, humans, cyborgs and hacked accounts – to spread disinformation. The report finds:
- 87% of countries used human accounts
- 80% of countries used bot accounts
- 11% of countries used cyborg accounts
- 7% of countries used hacked or stolen accounts…(More)”.
Sunlight foundation: “Community Data Dialogues are in-person events designed to share open data with community members in the most digestible way possible to start a conversation about a specific issue. The main goal of the event is to give residents who may not have technical expertise but have local experience a chance to participate in data-informed decision-making. Doing this work in-person can open doors and let facilitators ask a broader range of questions. To achieve this, the event must be designed to be inclusive of people without a background in data analysis and/or using statistics to understand local issues. Carrying out this event will let decision-makers in government use open data to talk with residents who can add to data’s value with their stories of lived experience relevant to local issues.
These events can take several forms, and groups both in and outside of government have designed creative and innovative events tailored to engage community members who are actively interested in helping solve local issues but are unfamiliar with using open data. This guide will help clarify how exactly to make Community Data Dialogues non-technical, interactive events that are inclusive to all participants….
A number of groups both in and outside of government have facilitated accessible open data events to great success. Here are just a few examples from the field of what data-focused events tailored for a nontechnical audience can look like:
Data Days Cleveland
Data Days Cleveland is an annual one-day event designed to make data accessible to all. Programs are designed with inclusivity and learning in mind, making it a more welcoming space for people new to data work. Data experts and practitioners direct novices on the fundamentals of using data: making maps, reading spreadsheets, creating data visualizations, etc….
The Urban Institute’s Data Walks
The Urban Institute’s Data Walks are an innovative example of presenting data in an interactive and accessible way to communities. Data Walks are events gathering community residents, policymakers, and others to jointly review and analyze data presentations on specific programs or issues and collaborate to offer feedback based on their individual experiences and expertise. This feedback can be used to improve current projects and inform future policies….(More)“.
Book by Vaclav Smil: “Growth has been both an unspoken and an explicit aim of our individual and collective striving. It governs the lives of microorganisms and galaxies; it shapes the capabilities of our extraordinarily large brains and the fortunes of our economies. Growth is manifested in annual increments of continental crust, a rising gross domestic product, a child’s growth chart, the spread of cancerous cells. In this magisterial book, Vaclav Smil offers systematic investigation of growth in nature and society, from tiny organisms to the trajectories of empires and civilizations.
Smil takes readers from bacterial invasions through animal metabolisms to megacities and the global economy. He begins with organisms whose mature sizes range from microscopic to enormous, looking at disease-causing microbes, the cultivation of staple crops, and human growth from infancy to adulthood. He examines the growth of energy conversions and man-made objects that enable economic activities—developments that have been essential to civilization. Finally, he looks at growth in complex systems, beginning with the growth of human populations and proceeding to the growth of cities. He considers the challenges of tracing the growth of empires and civilizations, explaining that we can chart the growth of organisms across individual and evolutionary time, but that the progress of societies and economies, not so linear, encompasses both decline and renewal. The trajectory of modern civilization, driven by competing imperatives of material growth and biospheric limits, Smil tells us, remains uncertain….(More)”.
Book by Mallory Compton and Edited by Paul ‘t Hart: “With so much media and political criticism of their shortcomings and failures, it is easy to overlook the fact that many governments work pretty well much of the time. Great Policy Successes turns the spotlight on instances of public policy that are remarkably successful. It develops a framework for identifying and assessing policy successes, paying attention not just to their programmatic outcomes but also to the quality of the processes by which policies are designed and delivered, the level of support and legitimacy they attain, and the extent to which successful performance endures over time. The bulk of the book is then devoted to 15 detailed case studies of striking policy successes from around the world, including Singapore’s public health system, Copenhagen and Melbourne’s rise from stilted backwaters to the highly liveable and dynamic urban centres they are today, Brazil’s Bolsa Familia poverty relief scheme, the US’s GI Bill, and Germany’s breakthrough labour market reforms of the 2000s. Each case is set in context, its main actors are introduced, key events and decisions are described, the assessment framework is applied to gauge the nature and level of its success, key contributing factors to success are identified, and potential lessons and future challenges are identified. Purposefully avoiding the kind of heavy theorizing that characterizes many accounts of public policy processes, each case is written in an accessible and narrative style ideally suited for classroom use in conjunction with mainstream textbooks on public policy design, implementation, and evaluation….(More)”.
About: “Demographic changes. Climate crisis. Cybercrime. Budget deficits. Diminishing political legitimacy. From a global perspective there is no shortage of complex problems facing the public sector. The need for innovative solutions is evident, but a systematic knowledge base for necessary public sector innovations is hard to come by.
Private sector companies have been the subject of internationally comparable statistics on innovation for nearly three decades, giving private companies, scholars and public sector decision-makers essential guidance for business development, research and policymaking.
For the public sector, however, anecdotes and opinions have been substitutes for statistical data on innovation. That is why, in 2015, the Danish National Centre for Public Sector Innovation, in association with Statistics Denmark, began separating myth from reality. The result was the Innovation Barometer, the world’s first official statistics on public sector innovation. The statistic is based on a nationwide web-based survey addressed to managers of public sector workplaces of all kinds – kindergartens, schools, hospitals, police stations ect.
While the findings were both surprising and useful, additional insight from national comparisons was missing. But not for long. By 2018 Norway, Sweden, Iceland and Finland had all conducted one or more national surveys, utilising similar methodologies and definitions, though adapted somewhat to better serve national agendas. Their ongoing efforts have also contributed to methodological adjustments, improving the original survey design.
Currently a large variety of people and organisations use Nordic Innovation Barometer data, applying them for their own purposes, e.g. inspiration, policymaking, strategizing, HR development, teaching, research and consultancy services. Or for legitimising certain decisions and criticising others. In short, the Nordic Innovation Barometers are being put to use as the public good they were intended to be, also in ways the developers and adaptors did not foresee.
On behalf of the remarkably innovative Nordic public sectors we are pleased to present the first website containing cross-Nordic comparisons. Although this website does not tell us everything that we would like to know about public sector innovation, it does provide a sorely needed systematic foundation for developing new solutions….(More)”.
Essay by Michael Fire: “…We attained the following five key insights from our study:
First, these results support Goodhart’s Law as it relates to academic publishing; that is, traditional measures (e.g., number of papers, number of citations, h-index, and impact factor) have become targets, and are no longer true measures importance/impact. By making papers shorter and collaborating with more authors, researchers are able to produce more papers in the same amount of time. Moreover, the majority of changes in papers’ structure are correlated with papers that receive higher numbers of citations. Authors can use longer titles and abstracts, or use question or exclamation marks in titles, to make their papers more appealing for readers and increase citations, i.e. academic clickbait. These results support our hypothesis that academic papers have evolved in order to score a bullseye on target metrics.
Second, it is clear that citation number has become a target for some researchers. We observe a general increasing trend for researchers to cite their previous work in their new studies, with some authors self citing dozens, or even hundreds, of times. Moreover, a huge quantity of papers – over 72% of all papers and 25% of all papers with at least 5 references – have no citations at all after 5 years. Clearly, a signficant amount of resources is spent on papers with limited impact, which may indicate that researchers are publishing more papers of poorer quality to boost their total number of publications. Additionally, we noted that different decades have very different paper citation distributions. Consequently, comparing citation records of researchers who published papers in different time periods can be challenging.
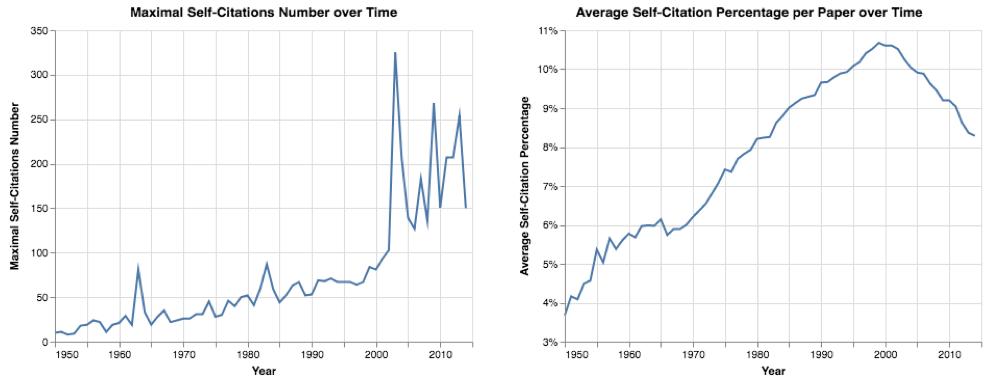
Third, we observed an exponential growth in the number of new researchers who publish papers, likely due to career pressures. …(More)”.
Introduction to Report by Tom Rodden: “This report addresses the most discussed digital technologies of the last few years. There has been considerable debate about the potential benefits and threats that arise from the use of Distributed Ledger Technologies. What is clear from these debates is that blockchain is an important technology that has the potential to transform a range of sectors. The importance of Distributed Ledger Technology was identified and discussed in a 2016 report produced by Sir Mark Walport, the UK Government’s Chief Scientific Adviser at the time.
The report provided recommendations for the use of blockchain to meet national needs, and to ensure the UK’s competitiveness in the global arena. The report outlined the need for a broad response that spanned the public and private sector, whilst also recognising the need for leadership in the development and deployment of blockchain technologies.
This report provides an update and reflection on the use of blockchain technologies by Governments and Public Sector bodies around the world. Much has happened since 2016 and this report provides a reminder of the importance of Distributed Ledger Technologies for the public sector, and the various orientations of blockchains adopted across the globe. The team have mapped the various regulatory and policy responses to blockchain, and cryptocurrencies more broadly. This mapping not only reveals a varying degree of friendliness towards blockchain, it also highlights the challenges involved in implementing Distributed Ledger Technology systems in the public sector.
Distributed Ledger Technologies are an important technology for the public sector, albeit there exists a number of policy implications. If we are to show leadership in the use of blockchain and its application it is imperative that we are aware of both its benefits and limitations; and the issues that need to be addressed to ensure we gain value from the use of Distributed Ledger Technologies. This report captures the public sector experiences of blockchain technologies across the globe, and also documents the issues raised and the various responses. This is a hugely informative and useful document for those who seek to make use of blockchains in the public sector….(More)”.

Report by Trends: “Eradicating poverty and hunger, ensuring quality education, instituting affordable and clean energy, and more – the Sustainable Development Goals (SDGs) lay out a broad, ambitious vision for our world. But there is one common denominator that cuts across this agenda: data. Without timely, relevant, and disaggregated data, policymakers and their development partners will be unprepared to turn their promises into reality for communities worldwide. With only eleven years left to meet the goals, it is imperative that we focus on building robust, inclusive, and relevant national data systems to support the curation and promotion of better data for sustainable development. In Counting on the World to Act, TReNDS details an action plan for governments and their development partners that will enable them to help deliver the SDGs globally by 2030. Our recommendations specifically aim to empower government actors – whether they be national statisticians, chief data scientists, chief data officers, ministers of planning, or others concerned with evidence in support of sustainable development – to advocate for, build, and lead a new data ecosystem….(More)”.