Stefaan Verhulst
NBER Paper by Daron Acemoglu and Pascual Restrepo: “Artificial Intelligence is set to influence every aspect of our lives, not least the way production is organized. AI, as a technology platform, can automate tasks previously performed by labor or create new tasks and activities in which humans can be productively employed. Recent technological change has been biased towards automation, with insufficient focus on creating new tasks where labor can be productively employed. The consequences of this choice have been stagnating labor demand, declining labor share in national income, rising inequality and lower productivity growth. The current tendency is to develop AI in the direction of further automation, but this might mean missing out on the promise of the “right” kind of AI with better economic and social outcomes….(More)”.
Paper by Danielle Citron and Ryan Calo: “The administrative state has undergone
Automated systems built in the early 2000s eroded procedural safeguards at the heart of the administrative state. When government makes important decisions that affect our lives, liberty, and property, it owes us “due process”— understood as notice of, and a chance to object to, those decisions. Automated systems, however, frustrate these guarantees. Some systems like the “no-fly” list were designed and deployed in secret; others lacked record-keeping audit trails, making review of the law and facts supporting a system’s decisions impossible. Because programmers working at private contractors lacked training in the law, they distorted policy when translating it into code [2].
Some of us in the academy sounded the alarm as early as the 1990s, offering an array of mechanisms to ensure the accountability and transparency of automated administrative state [3]. Yet the same pathologies continue to plague government decision-making systems today. In some cases, these pathologies have deepened and extended. Agencies lean upon algorithms that turn our personal data into predictions, professing to reflect who we are and what we will do. The algorithms themselves increasingly rely upon techniques, such as deep learning, that are even less amenable to scrutiny than purely statistical models. Ideals of what the administrative law theorist Jerry Mashaw has called “bureaucratic justice” in the form of efficiency with a “human face” feel impossibly distant [4].
The trend toward more prevalent and less transparent automation in agency decision-making is deeply concerning. For a start, we have yet to address in any meaningful way the widening gap between the commitments of due process and the actual practices of contemporary agencies [5]. Nonetheless, agencies rush to automate (surely due to the influence and illusive promises of companies seeking lucrative contracts), trusting algorithms to tell us if criminals should receive probation, if public school teachers should be fired, or if severely disabled individuals should receive less than the maximum of state-funded nursing care [6]. Child welfare agencies conduct intrusive home inspections because some system, which no party to the interaction understands, has rated a poor mother as having a propensity for violence. The challenges of preserving due process in light of algorithmic decision-making is an area of renewed and active attention within academia, civil society, and even the courts [7].
Second, and routinely overlooked, we are applying the new affordances of artificial intelligence in precisely the wrong contexts…(More)”.
Paper by Abigail Devereaux: “Augmented and virtual reality, whose ubiquitous convergence is known as extended reality (XR), are technologies that imbue a user’s apparent surroundings with some degree of virtuality. In this article, we are interested in how social entrepreneurs might utilize innovative technological methods in XR to solve social problems presented by XR. Social entrepreneurship in XR presents novel challenges and opportunities not present in traditional regulatory spaces, as XR changes the environment in which choices are made.
Furthermore, the challenges presented by rapidly advancing XR may require much more agile forms of governance than are available from public institutions, even under widespread algorithmic governance. Social entrepreneurship in blockchain solutions may very well be able to meet some of these challenges, as we show. Thus, we expect a new infrastructure to arise to address challenges presented by XR, built by social entrepreneurs in XR, and that may eventually be used as an alternative to public instantiations of governance. Our central thesis is that the dynamic, immersive, and agile nature of XR both provides an unusually fertile ground for the development of alternative forms of governance and essentially necessitates this development by contrast with relatively inagile institutions of public governance….(More)”.
Paper by Tarun Ramadorai, Antoine Uettwiller
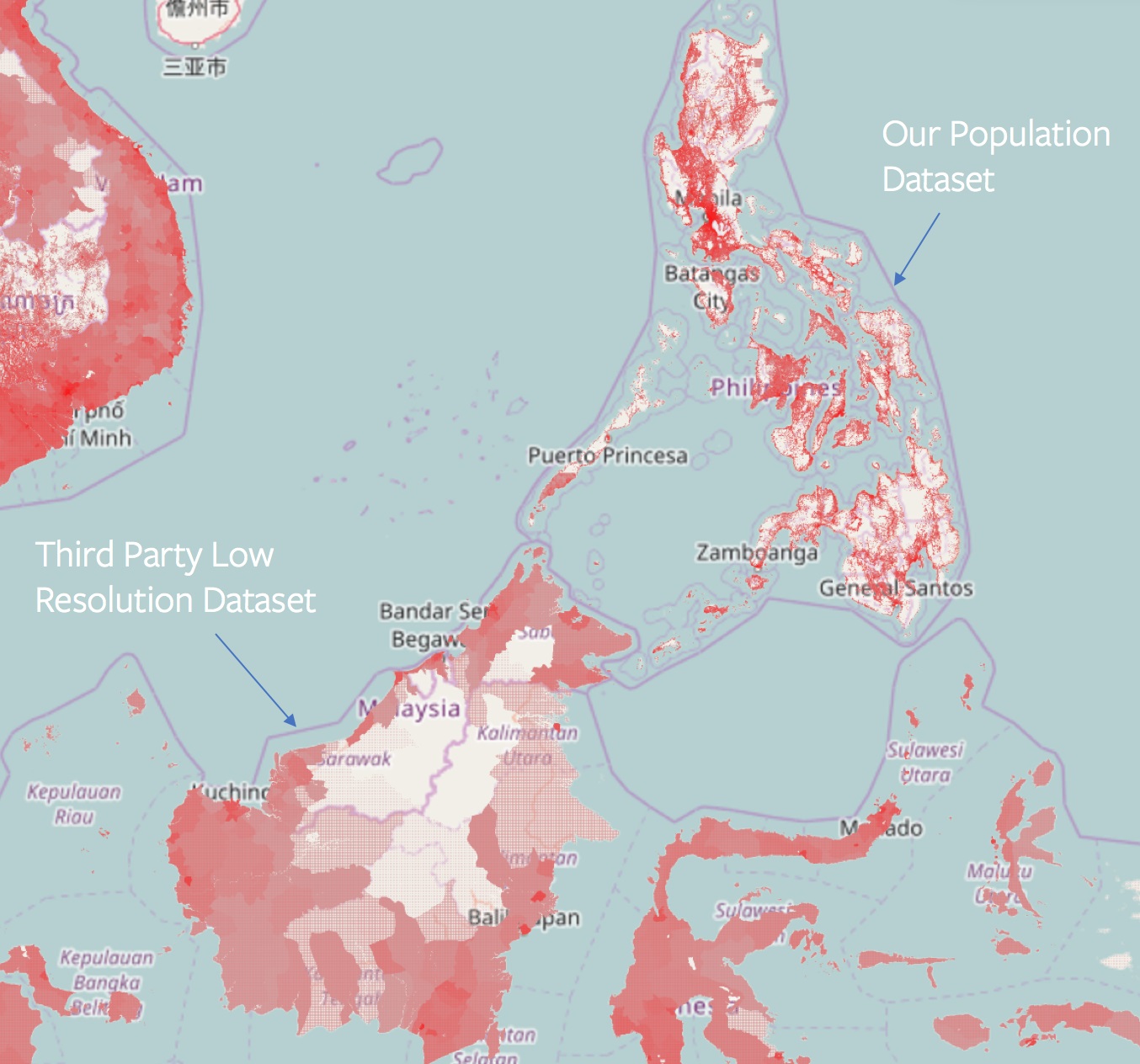
Devin Coldewey at TechCrunch: “A new map of nearly all of Africa shows exactly where the continent’s 1.3 billion people live, down to the meter, which could help everyone from local governments to aid organizations. The map joins others like it from
It’s not exactly that there was some mystery about where people live, but the degree of precision matters. You may know that a million people live in a given region, and that about half are in the bigger city and another quarter in assorted towns. But that leaves hundreds of thousands only accounted for in the vaguest way.
Fortunately, you can always inspect satellite imagery and pick out the spots where small villages and isolated houses and communities are located. The only problem is that Africa is big. Really big. Manually labeling the satellite imagery even from a single mid-sized country like Gabon or Malawi would take a huge amount of time and effort. And for many applications of the data, such as coordinating the response to a natural disaster or distributing vaccinations, time lost is lives lost.
Better to get it all done at once then, right? That’s the idea behind Facebook’s Population Density Maps project, which had already mapped several countries over the last couple of years before the decision was made to take on the entire African continent….
“The maps from Facebook ensure we focus our volunteers’ time and resources on the places they’re most needed, improving the efficacy of our programs,” said Tyler Radford, executive director of the Humanitarian OpenStreetMap Team, one of the project’s partners.
The core idea is straightforward: Match census data (how many people live in a region) with structure data derived from satellite imagery to get a much better idea of where those people are located.
“With just the census data, the best you can do is assume that people live everywhere in the district – buildings, fields, and forests alike,” said Facebook engineer James Gill. “But once you know the building locations, you can skip the fields and forests and only allocate the population to the buildings. This gives you very detailed 30 meter by 30 meter population maps.”
That’s several times more accurate than any extant population map of this size. The analysis is done by a machine learning agent trained on OpenStreetMap data from all over the world, where people have labeled and outlined buildings and other features.
Helen Margetts and Cosmina Dorobantu at Nature: “People produce more than 2.5 quintillion bytes of data each day. Businesses are harnessing these riches using artificial intelligence (AI) to add trillions of dollars in value to goods and services each year. Amazon dispatches items it anticipates customers will buy to regional hubs before they are purchased. Thanks to the vast extractive might of Google and Facebook, every bakery and bicycle shop is the beneficiary of personalized targeted advertising.
But governments have been slow to apply AI to hone their policies and services. The reams of data that governments collect about citizens could, in theory, be used to tailor education to the needs of each child or to fit health care to the genetics and lifestyle of each patient. They could help to predict and prevent traffic deaths, street crime or the necessity of taking children into care. Huge costs of floods, disease outbreaks and financial crises could be alleviated using state-of-the-art modelling. All of these services could become cheaper and more effective.
This dream seems rather distant. Governments have long struggled with much simpler technologies. Flagship policies that rely on information technology (IT) regularly flounder. The Affordable Care Act of former US president Barack Obama nearly crumbled in 2013 when HealthCare.gov, the website enabling Americans to enrol in health insurance plans, kept crashing. Universal Credit, the biggest reform to the UK welfare state since the 1940s, is widely regarded as a disaster because of its failure to pay claimants properly. It has also wasted £837 million (US$1.1 billion) on developing one component of its digital system that was swiftly decommissioned. Canada’s Phoenix pay system, introduced in 2016 to overhaul the federal government’s payroll process, has remunerated 62% of employees incorrectly in each fiscal year since its launch. And My Health Record, Australia’s digital health-records system, saw more than 2.5 million people opt out by the end of January this year over privacy, security and efficacy concerns — roughly 1 in 10 of those who were eligible.
Such failures matter. Technological innovation is essential for the state to maintain its position of authority in a data-intensive world. The digital realm is where citizens live and work, shop and play, meet and fight. Prices for goods are increasingly set by software. Work is mediated through online platforms such as Uber and Deliveroo. Voters receive targeted information — and disinformation — through social media.
Thus the core tasks of governments, such as enforcing regulation, setting employment rights and ensuring fair elections require an understanding of data and algorithms. Here we highlight the main priorities, drawn from our experience of working with policymakers at The Alan Turing Institute in London….(More)”.
Caroline Nickerson at SciStarter: “Citizen science has been around as long as science, but innovative approaches are opening doors to more and deeper forms of public participation.
Below, our editors spotlight a few projects that feature new approaches, novel research, or low-cost instruments. …
Colony B: Unravel the secrets of microscopic life! Colony B is a mobile gaming app developed at McGill University that enables you to contribute to research on microbes. Collect microbes and grow your colony in a fast-paced puzzle game that advances important scientific research.
AirCasting: AirCasting is an open-source, end-to-end solution for collecting, displaying, and sharing health and environmental data using your smartphone. The platform consists of wearable sensors, including a palm-sized air quality monitor called the AirBeam, that detect and report changes in your environment. (Android only.)
LingoBoingo: Getting computers to understand language requires large amounts of linguistic data and “correct” answers to language tasks (what researchers call “gold standard annotations”). Simply by playing language games online, you can help archive languages and create the linguistic data used by researchers to improve language technologies. These games are in English, French, and a new “multi-lingual” category.
TreeSnap: Help our nation’s trees and protect human health in the process. Invasive diseases and pests threaten the health of America’s forests. With the TreeSnap app, you can record the location and health of particular tree species–those unharmed by diseases that have wiped out other species. Scientists then use the collected information to locate candidates for genetic sequencing and breeding programs. Tag trees you find in your community, on your property, or out in the wild to help scientists understand forest health….(More)”.
Ben Paynter at FastCompany: “Several years ago, one of the eventual founders of One Concern nearly died in a tragic flood. Today, the company specializes in using artificial intelligence to predict how natural disasters are unfolding in real time on a city-block-level basis, in order to help disaster responders save as many lives as possible….
To fix that, One Concern debuted Flood Concern in late 2018. It creates map-based visualizations of where water surges may hit hardest, up to five days ahead of an impending storm. For cities, that includes not just time-lapse breakdowns of how the water will rise, how fast it could move, and what direction it will be flowing, but also what structures will get swamped or washed away, and how differing mitigation efforts–from levy building to dam releases–will impact each scenario. It’s the winner of Fast Company’s 2019 World Changing Ideas Awards in the AI and Data category.
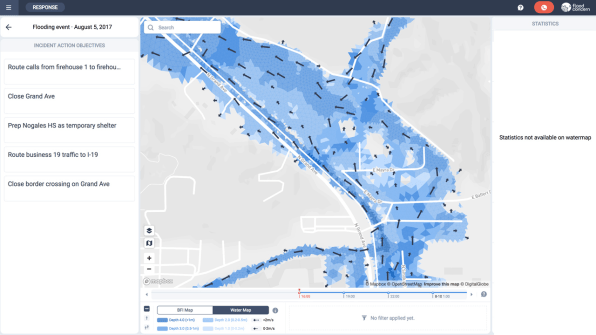
So far, Flood Concern has been retroactively tested against events like Hurricane Harvey to show that it could have predicted what areas would be most impacted well ahead of the storm. The company, which was founded in Silicon Valley in 2015, started with one of that region’s pressing threats: earthquakes. It’s since earned contracts with cities like San Francisco, Los Angeles, and Cupertino, as well as private insurance companies….
One Concern’s first offering, dubbed Seismic Concern, takes existing information from satellite images and building permits to figure out what kind of ground structures are built on, and what might happen if they started shaking. If a big one hits, the program can extrapolate from the epicenter to suggest the likeliest places for destruction, and then adjust as more data from things like 911 calls and social media gets factored in….(More)”.

Open Access Book by Ben Green: “Smart cities, where technology is used to solve every problem, are hailed as futuristic urban utopias. We are promised that apps, algorithms, and artificial intelligence will relieve congestion, restore democracy, prevent crime, and improve public services. In The Smart Enough City, Ben Green warns against seeing the city only through the lens of technology; taking an exclusively technical view of urban life will lead to cities that appear smart but under the surface are rife with injustice and inequality. He proposes instead that cities strive to be “smart enough”: to embrace technology as a powerful tool when used in conjunction with other forms of social change—but not to value technology as an end in itself….(More)”.
European Commission: “Following the publication of the draft ethics guidelines in December 2018 to which more than 500 comments were received, the independent expert group presents today their ethics guidelines for trustworthy artificial intelligence.
Trustworthy AI should respect all applicable laws and regulations, as well as a series of requirements; specific assessment lists aim to help verify the application of each of the key requirements:
- Human agency and oversight: AI systems should enable equitable societies by supporting human agency and fundamental rights, and not decrease, limit or misguide human autonomy.
- Robustness and safety: Trustworthy AI requires algorithms to be secure, reliable and robust enough to deal with errors or inconsistencies during all life cycle phases of AI systems.
- Privacy and data governance: Citizens should have full control over their own data, while data concerning them will not be used to harm or discriminate against them.
- Transparency: The traceability of AI systems should be ensured.
- Diversity, non-discrimination and fairness: AI systems should consider the whole range of human abilities, skills and requirements, and ensure accessibility.
- Societal and environmental well-being: AI systems should be used to enhance positive social change and enhance sustainability and ecological responsibility.
- Accountability: Mechanisms should be put in place to ensure responsibility and accountability for AI systems and their outcomes.
In summer 2019, the Commission will launch a pilot phase involving a wide range of stakeholders. Already today, companies, public administrations and organisations can sign up to the European AI Alliance and receive a notification when the pilot starts.
Following the pilot phase, in early 2020, the AI expert group will review the assessment lists for the key requirements, building on the feedback received. Building on this review, the Commission will evaluate the outcome and propose any next steps….(More)”.