Stefaan Verhulst
Press Release: “The 2019 Edelman Trust Barometer reveals that trust has changed profoundly in the past year—people have shifted their trust to the relationships within their control, most notably their employers. Globally, 75 percent of people trust “my employer” to do what is right, significantly more than NGOs (57 percent), business (56 percent) and media (47 percent).
Divided by Trust
There is a 16-point gap between the more trusting informed public and the far-more-skeptical mass population, marking a return to record highs of trust inequality. The phenomenon fueling this divide was a pronounced rise in trust among the informed public. Markets such as the U.S., UK, Canada, South Korea and Hong Kong saw trust gains of 12 points or more among the informed public. In 18 markets, there is now a double-digit trust gap between the informed public and the mass population.
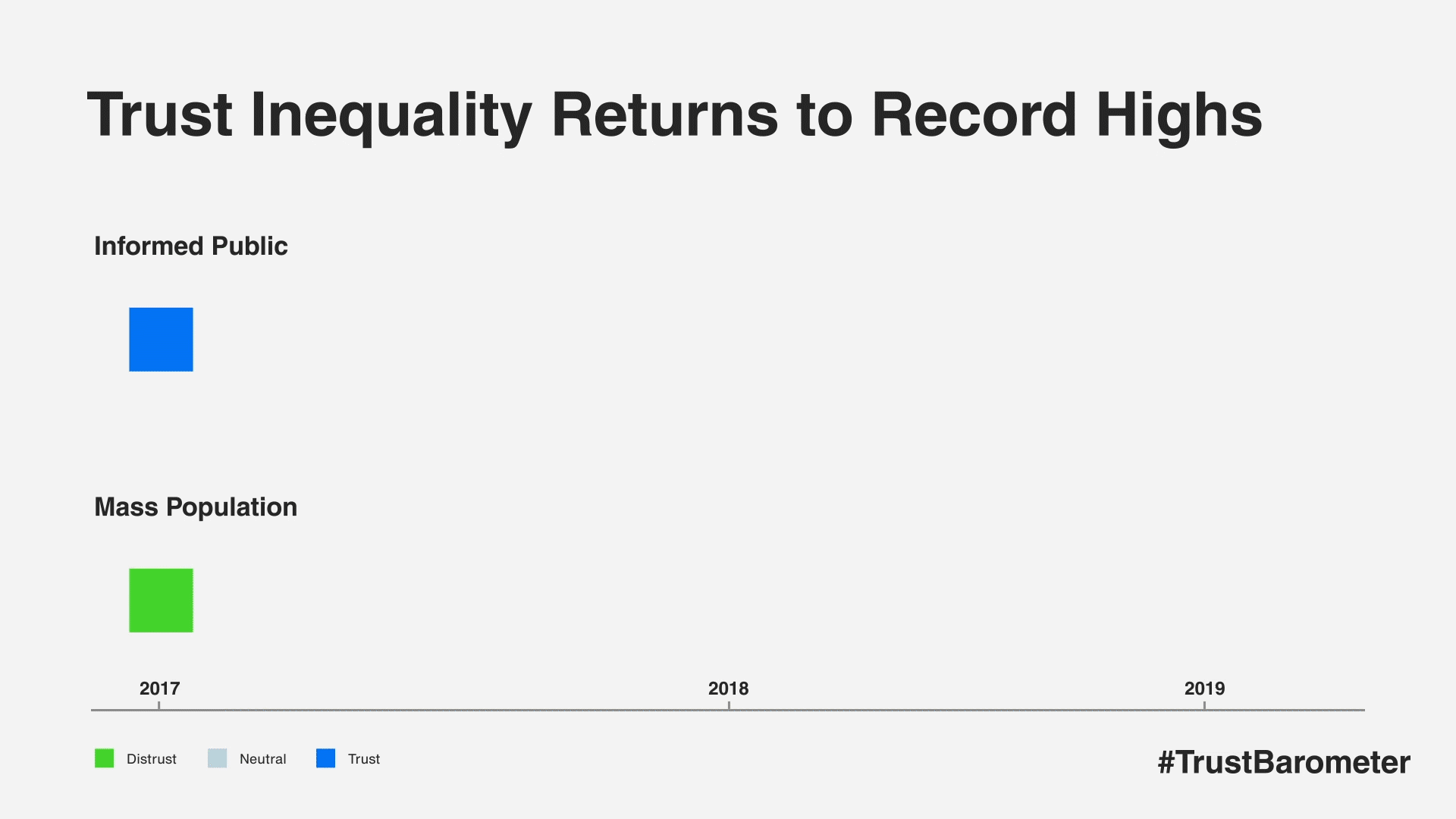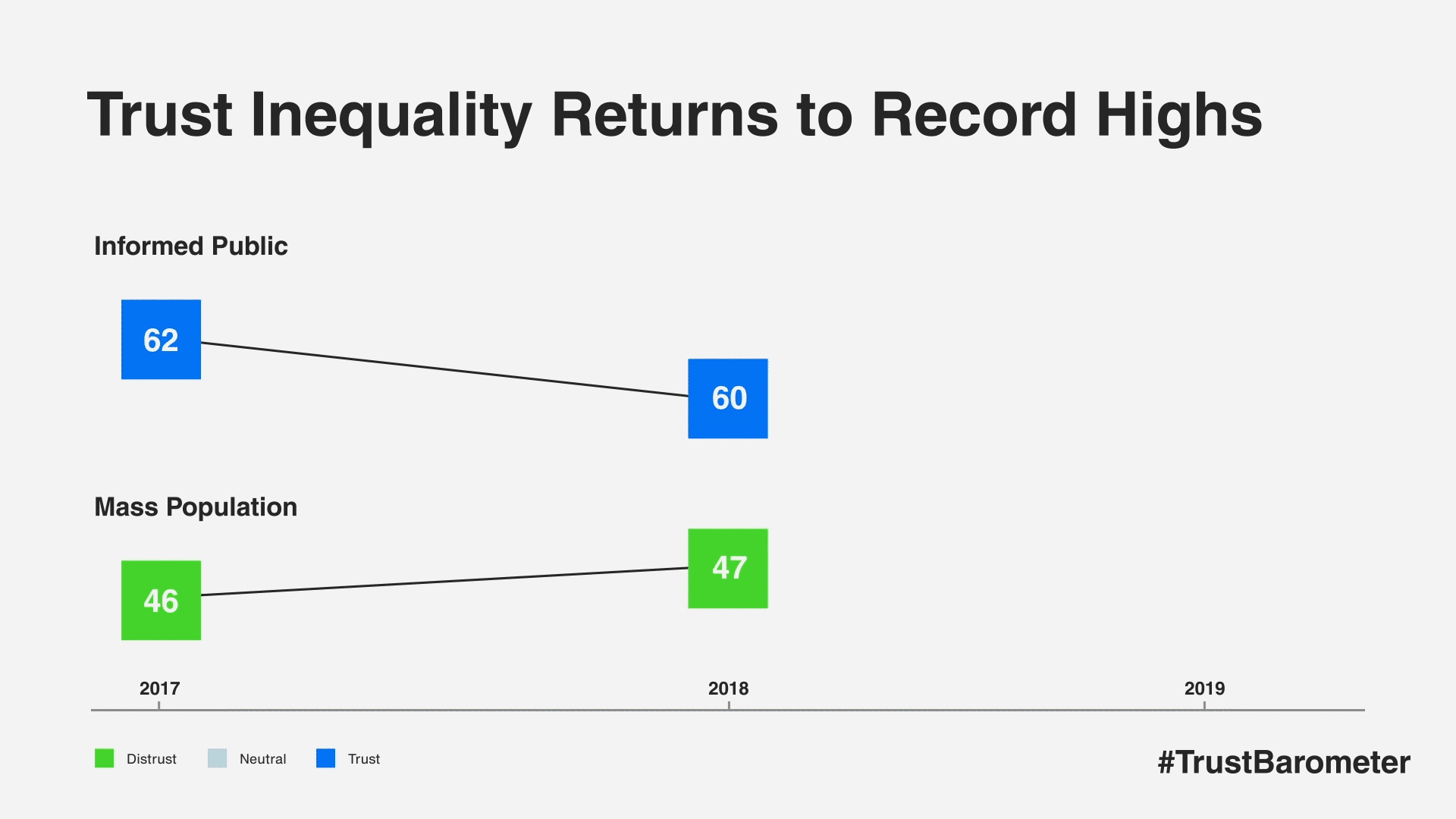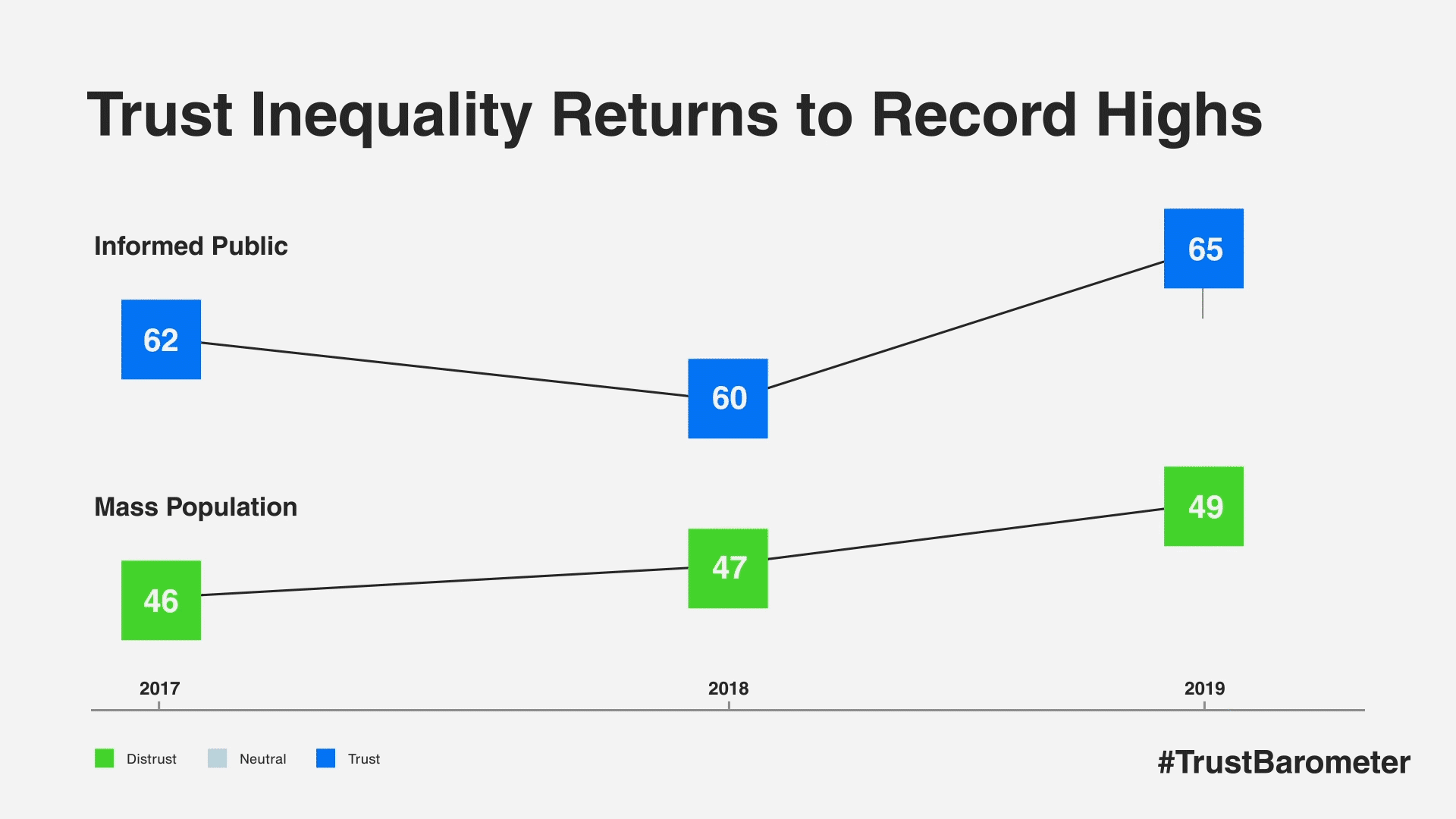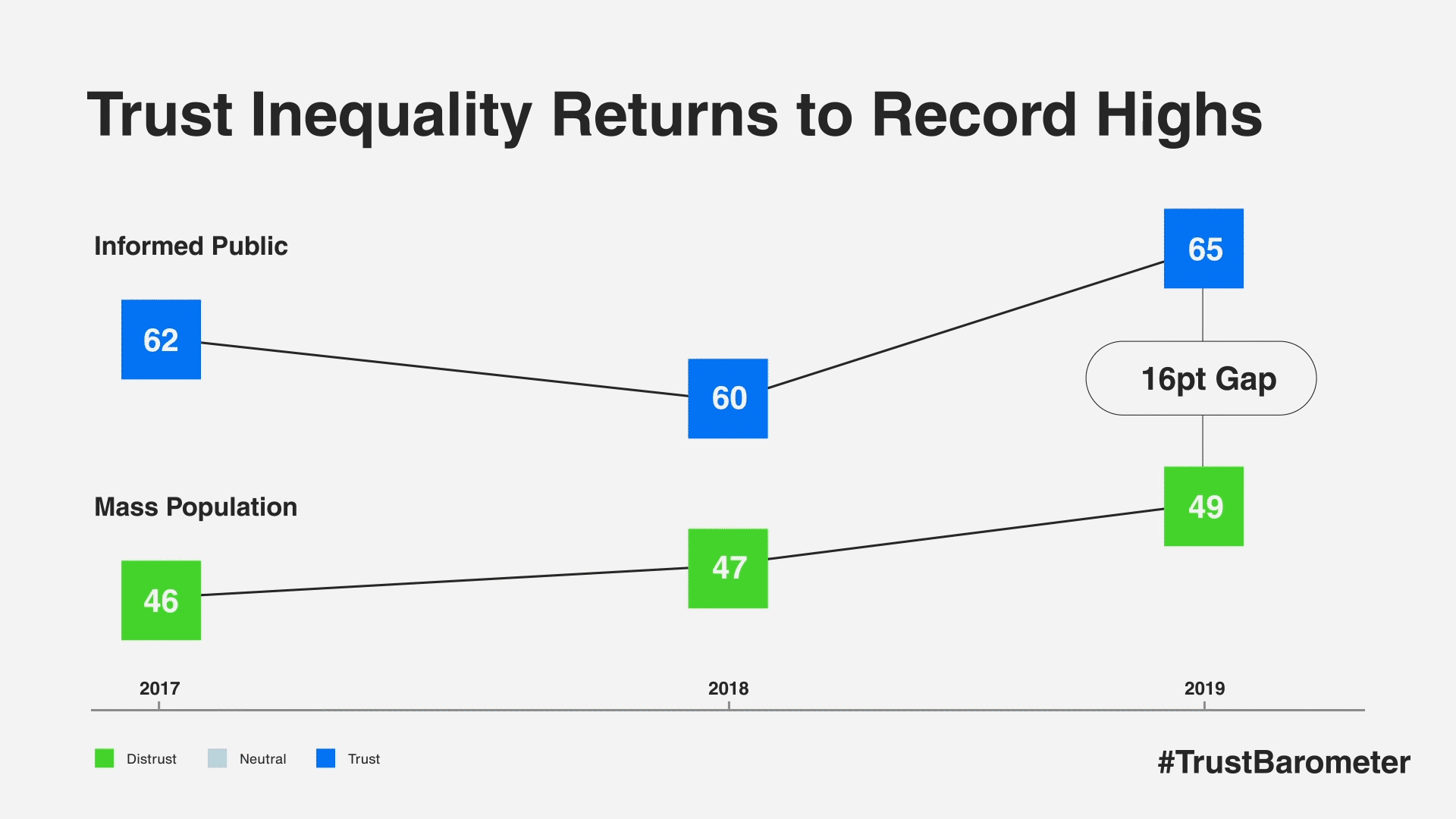
An Urgent Desire for Change
Despite the divergence in trust between the informed public and mass population the world is united on one front—all share an urgent desire for change. Only one in five feels that the system is working for them, with nearly half of the mass population believing that the system is failing them.
In conjunction with pessimism and worry, there is a growing move toward engagement and action. In 2019, engagement with the news surged by 22 points; 40 percent not only consume news once a week or more, but they also routinely amplify it. But people are encountering roadblocks in their quest for facts, with 73 percent worried about fake news being used as a weapon.

The New Employer-Employee Contract
Despite a high lack of faith in the system, there is one relationship that remains strong: “my employer.” Fifty-eight percent of general population employees say they look to their employer to be a trustworthy source of information about contentious societal issues.
Employees are ready and willing to trust their employers, but the trust must be earned through more than “business as usual.” Employees’ expectation that prospective employers will join them in taking action on societal issues (67 percent) is nearly as high as their expectations of personal empowerment (74 percent) and job opportunity (80 percent)….(More)”.
Heather Savory at the Office for National Statistics (UK): “Official Statistics are for the benefit of society and the economy and help Britain to make better decisions. They allow the formulation of better public policy and the effective measurement of those policies. They inform the direction of economic and commercial activities. They provide valuable information for analysts, researchers, public and voluntary bodies. They enable the public to hold
The ability to harness the power of data is critical in enabling official statistics to support the most important decisions facing the country.
Under the new powers in the Digital Economy Act , ONS can now gain access to new and different sources of data including ‘administrative’ data from government departments and commercial data. Alongside the availability of these new data sources ONS is experiencing a strong demand for ad hoc insights alongside our traditional statistics.
We need to deliver more, faster, finer-grained insights into the economy and society. We need to deliver high quality, trustworthy information, on a faster timescale, to help decision-making. We will increasingly develop innovative data analysis methods, for example using images to gain insight from the work we’ve recently announced on Urban Forests
I should explain here that our data is not held in one big linked database; we’re architecting our Data Access Platform so that data can be linked in different ways for different purposes. This is designed to preserve data confidentiality, so only the necessary subset of data is accessible by authorised people, for a certain purpose. To avoid compromising their effectiveness, we do not make public the specific details of the security measures we have in place, but our recently tightened security regime, which is independently assured by trusted external bodies, includes:
- physical measures to restrict who can access places where data is stored;
- protective measures for all data-related IT services;
- measures to restrict who can access systems and data held by ONS;
- controls to guard against staff or contractors misusing their legitimate access to data; including vetting to an appropriate level for the sensitivity of data to which they might have access.
One of the things I love about working in the public sector is that our work can be shared openly.
We live in a rapidly changing and developing digital world and we will continue to monitor and assess the data standards and security measures in place to ensure they remain strong and effective. So, as well as sharing this work openly to reassure all our data suppliers that we’re taking good care of their data, we’re also seeking feedback on our revised data policies.
The same data can provide different insights when viewed through different lenses or in different combinations. The more data is shared – with the appropriate safeguards of course – the more it has to give.
If you work with data, you’ll know that collaborating with others in this space is key and that we need to be able to share data more easily when it makes sense to do so. So, the second reason for sharing this work openly is that, if you’re in the technical space, we’d value your feedback on our approach and if you’re in the data space and would like to adopt the same approach, we’d love to support you with that – so that we can all share data more easily in the future….(More)
ONS’s revised policies on the use, management
Book edited by Bill Johnston, Sheila MacNeill and Keith Smyth: “Despite the increasing ubiquity of the term, the concept of the digital university remains diffuse and indeterminate. This book examines what the term ‘digital university’ should encapsulate and the resulting challenges, possibilities
Jen Gold at What Works Blog: “There’s a small but growing band of government teams around the world dedicated to making experiments happen. The Cabinet Office’s What Works Team, set up in 2013, was the first of its kind. But you’ll now find them in Canada, the US, Finland, Australia, Colombia, and the UAE.
All of these teams work across government to champion the testing and evaluation of new approaches to public service delivery. This blog takes a look at the many ways in which we’re striving to make experimentation the norm in our governments.
Unsurprisingly we’re all operating in very different contexts. Some teams were set up in response to central requirements for greater experimentation. Take Canada, for instance. In 2016 the Treasury Board directed departments and agencies to devote a fixed proportion of programme funds to “experimenting with new approaches” (building on Prime Minister Trudeau’s earlier instruction to Ministers). An Innovation and Experimentation Team was then set up in the Treasury Board to provide some central support.
Finland’s Experimentation Office, based in the Prime Minister’s Office, is in a similar position. The team supports the delivery of Prime Minister Juha Sipilä’s 2016 national action plan that calls for “a culture of experimentation” in public services and a series of flagship policy experiments.
Others, like the US Office of Evaluation Sciences (OES) and the Behavioural Economics Team of the Australian Government (BETA), grew out of political interest in using behavioural science experiments in public policy. But these teams now run experiments in a much broader set of areas.
What unites us is a focus on helping public servants generate and use new evidence in policy decisions and service delivery
Larry Kramer at the Hewlett Foundation: “Among the most corrosive developments of recent years—one that predates the election of Donald Trump—has been a breakdown in our ability to debate and reason with others with whom we disagree. The term du jour, “tribalism,” replaced the earlier “polarization” precisely to capture the added ingredient of animosity that has made even conversation across partisan divides difficult. Mistrust and hostility have been grafted onto disagreement about ideas.
Political scientists differ about how widespread the phenomenon is—some seeing it shared broadly across American society, while others believe it confined to activist elites. I lean toward the latter view, though the disease seems to be spreading awfully fast. The difference hardly
Learning to listen with empathy matters for a number of reasons. An advocate needs to see an opponent’s argument in its strongest light, not only to counter the position effectively, but also to fully understand his or her own position—its weaknesses as well as its strengths—and so be properly prepared to defend it. Nor is this the only reason, because adversarial advocacy is only part of what lawyers do. Most legal work involves bargaining among conflicting interests and finding ways to settle disputes. Good lawyers know how to negotiate and cooperate; they know (in the phrase made famous by Roger Fisher and William Ury) how to “get to yes”—something made vastly easier if one fully and fairly comprehends both sides of an issue. There is a reason lawyers have historically constituted such a disproportionate share of our legislators and executives, and it’s not because they know how to argue. It is because they know how to find common ground.
Not that
Three techniques in particular pervade the practice of paying heed to an opposing argument without condescending to meet it:
- First, there is the “straw man” method—a tried and true practice that involves taking the weakest or most extreme or least plausible argument in favor of a position and acting as if it were the only argument for that position; a variation of this method takes the most extreme and unattractive advocates for a position and treats them as typical.
- Second is the practice of attributing bad motives to one’s opponents. Those employing this approach assume that people who take a contrary position know in their hearts that they are wrong and make the arguments they do for some inappropriate reason, such as racism or self-interest, that makes it easy to ignore what they have to say.
- Third, a relatively new
entrant, is what might be called the identity excuse: “We don’t need to listen to them because they are [blank].” Then fill in the blank with whatever identity you think warrants dismissal: a white male, a Black Lives Matter supporter, a Trump voter, a Democrat, the oil industry, a union, someone who received money for their work, and so on….(More)”.
Paper by Samuli Reijula, Jaakko Kuorikoski et al: “Nudge and boost are two competing approaches to applying the psychology of reasoning and decision making to improve policy. Whereas nudges rely on manipulation of choice architecture to steer people towards better choices, the objective of boosts is to develop good decision-making competences. Proponents of both approaches claim capacity to enhance social welfare through better individual decisions.
We suggest that such efforts should involve a more careful analysis of how individual and social welfare are related in the policy context. First, individual rationality is not always sufficient or necessary for improving collective outcomes. Second, collective outcomes of complex social interactions among individuals are largely ignored by the focus of both nudge and boost on individual decisions. We suggest that the design of mechanisms and social norms can sometimes lead to better collective outcomes than nudge and boost, and present conditions under which the three approaches (nudge, boost, and design) can be expected to enhance social welfare….(More)”.
The risk of extinction varies from species to species depending on how individuals in its populations reproduce and how long each animal survives. Understanding the dynamics of survival and reproduction can support management actions to improve a specie’s chances of surviving.
Mathematical and statistical models have become powerful tools to help explain these dynamics. However, the quality of the information we use to construct such models is crucial to improve our chances of accurately predicting the fate of populations in nature.
Colchero’s research focuses on mathematically recreating the population dynamics by better understanding the species’s demography. He works on constructing and exploring stochastic population models that predict how a certain population (for example an endangered species) will change over time.
These models include mathematical factors to describe how the species’ environment, survival rates and reproduction determine to the population’s size and growth. For practical reasons some assumptions are necessary.
Two commonly accepted assumptions are that survival and reproduction are constant with age, and that high survival in the species goes hand in hand with reproduction across all age groups within a species. Colchero challenged these assumptions by accounting for age-specific survival and reproduction, and for trade-offs between survival and reproduction. This is, that sometimes conditions that favor survival will be unfavorable for reproduction, and vice versa.

For his work Colchero used statistics, mathematical derivations, and computer simulations with data from wild populations of 24 species of vertebrates. The outcome was a significantly improved model that had more accurate predictions for a species’ population growth.
Despite the technical nature of Fernando’s work, this type of model can have very practical implications as they provide qualified explanations for the underlying reasons for the extinction. This can be used to take management actions and may help prevent
Paper by Anke Schwittay, Paul Braund: “Through an empirical analysis of Amplify, a crowdsourcing platform funded by the UK’s Department for International Development (DFID), we examine the potential of ICTs to afford more participatory development. Especially interactive Web2.0 technologies are often assumed to enable the participation of marginalized groups in their development, through allowing them to modify content and generate their own communication.
We use the concepts of platform politics and voice to show that while Amplify managers and designers invested time and resources to include the voices of Amplify beneficiaries on the platform and elicit their feedback on projects supported via the platform, no meaningful participation took place. Our analysis of the gaps between participatory rhetoric, policy and practice concludes with suggestions for how ICTs could be harnessed to contribute to meaningful participatory development that matters materially and politically.
Simon Rodberg at Harvard Business School: “For too long, the American education system failed too many kids, including far too many poor kids and kids of color, without enough public notice or accountability. To combat this, leaders of all political persuasions championed the use of testing to measure progress and drive better results. Measurement has become so common that in school districts from coast to coast you can now find calendars marked “Data Days,” when teachers are expected to spend time not on teaching, but on analyzing data like end-of-year and mid-year exams, interim assessments, science and social studies and teacher-created and computer-adaptive tests, surveys, attendance and behavior notes. It’s been this way for more than 30 years, and it’s time to try a different approach.
The big numbers are necessary, but the more they proliferate, the less value they add. Data-based answers lead to further data-based questions, testing, and analysis; and the psychology of leaders and policymakers means that the hunt for data gets in the way of actual learning. The drive for data responded to a real problem in education, but bad thinking about testing and data use has made the data cure worse than the disease
The leadership decision at stake is how much data to collect. I’ve heard variations on “In God we trust; all others bring data” at any number of conferences and beginning-of-school-year speeches. But the mantra “we believe in data” is actually only shorthand for “we believe our actions should be informed by the best available data.” In education, that mostly means testing. In other fields, the kind of process is different, but the issue is the same. The key question is not, “will the data be useful?” (of course it can be) or, “will the data be interesting?” (Yes, again.) The proper question for leaders to ask is: will the data help us make better-enough decisions to be worth the cost of getting and using it? So far, the answer is “no.”
Nationwide data suggests that the growth of data-driven schooling hasn’t worked even by its own lights. Harvard professor Daniel Koretz says “The best estimate is that test-based accountability may have produced modest gains in elementary-school mathematics but no appreciable gains in either reading or high-school mathematics — even though reading and mathematics have been its primary focus.”
We wanted data to help us get past the problem of too many students learning too little, but it turns out that data is an insufficient, even misleading answer. It’s possible that all we’ve learned from our hyper-focus on data is that better instruction won’t come from more detailed information, but from changing what people do. That’s what data-driven reform is meant for, of course: convincing teachers of the need to change and
NIH Press Release: “The All of Us Research Program has launched the Fitbit Bring-Your-Own-Device (BYOD) project. Now, in addition to providing health information through surveys, electronic health records, and biosamples, participants can choose to share data from their Fitbit accounts to help researchers make discoveries. The project is a key step for the program in integrating digital health technologies for data collection.
Digital health technologies, like mobile apps and wearable devices, can gather data outside of a hospital or clinic. This data includes information about physical activity, sleep, weight, heart rate, nutrition, and water intake, which can give researchers a more complete picture of participants’ health. The All of Us Research Program is now gathering this data in addition to surveys, electronic health record information, physical measurements, and blood and urine samples, working to make the All of Us resource one of the largest and most diverse data sets of its kind for health research.
“Collecting real-world, real-time data through digital technologies will become a fundamental part of the program,” said Eric Dishman, director of the All of Us Research Program. “This information, in combination with many other data types, will give us an unprecedented ability to better understand the impact of lifestyle and environment on health outcomes and, ultimately, develop better strategies for keeping people healthy in a very precise, individualized way.”…
All of Us is developing additional plans to incorporate digital health technologies. A second project with Fitbit is expected to launch later in the year. It will include providing devices to a limited number of All of Us participants who will be randomly invited to take part, to enable them to share wearable data with the program. And All of Us will add connections to other devices and apps in the future to further expand data collection efforts and engage participants in new ways….(More)”.