Stefaan Verhulst
Article by Kate Hodkinson: “Novel data sources can provide important proxies in data-limited contexts. When combined with traditional humanitarian data, such as needs assessments or displacement tracking, these sources can increase the resilience of the humanitarian data ecosystem. For example, in response to the March 2025 Myanmar earthquake, Microsoft AI for Good Lab provided data on building damage before access to affected areas was possible. In other cases, Meta’s high-resolution population density maps have been used to estimate the number of people living within a 30-metre grid and their demographics, helping organisations identify people in need.
Applications of this novel data sources have been explored through many pilots over the last decade. However, progress has not been linear. Seemingly promising technologies have fallen into obscurity, while others have carved out clear use cases. How should humanitarians use novel data sources to reinforce informational resilience, rather than create new dependencies?
Exploring this question required a structured rubric through which we could assess the integration of novel data sources to date, understand their technosocial context, and consider the factors that may define their future use in the humanitarian sector. We used two tools to do this: the S-Curve and the Technology Axis Model.
The S-Curve
The humanitarian sector’s adoption of novel data sources can be mapped against an S-Curve (adapted from Fisher, 1971), which measures maturity from nascent potential to normative practice. For example, the use of satellite data to create dynamic, high-resolution population estimates has moved from a ‘nascent’ opportunity towards a common practice, proving particularly valuable in contexts with limited or outdated census data. The S-Curve creates a way to plot examples of where novel data sources have been integrated into crisis response analysis or appear trapped in a perpetual pilot phase.

The Technology Axis Model (TAM) positions technology innovation cycles as happening in four inter-linked areas:
- The development of the underlying technology.
- The social norms and values associated with the innovation and its effects.
- The applications that are emerging as entrepreneurs seek to introduce the technology into markets.
- The infrastructure and systems that govern the technology area.
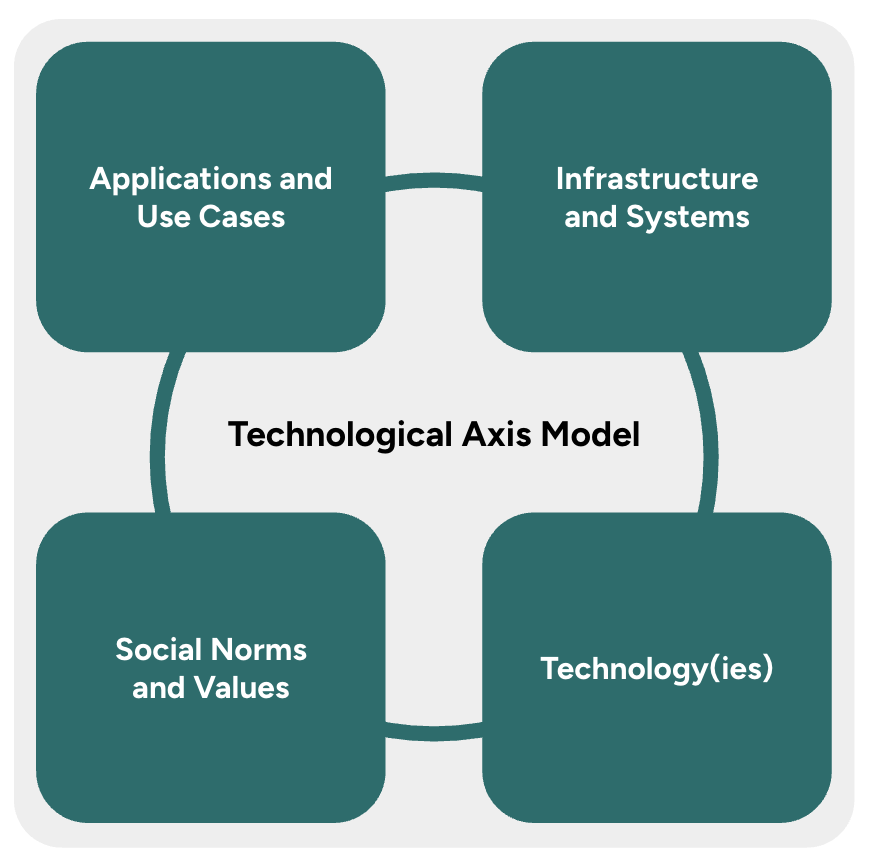
The Technology Axis Model was originally developed by Bill Sharpe as a way to help engineers think more widely about the contexts that surround technology innovation. Our definitions are drawn from a forthcoming paper on the Technology Axis Model, by Bill Sharpe and Andrew Curry…(More)”.
OECD Report: “…explores the concept of openness in artificial intelligence (AI), including relevant terminology and how different degrees of openness can exist. It explains why the term “open source” – a term rooted in software – does not fully capture the complexities specific to AI. This paper analyses current trends in open-weight foundation models using experimental data, illustrating both their potential benefits and associated risks. It incorporates the concept of marginality to further inform this discussion. By presenting information clearly and concisely, the paper seeks to support policy discussions on how to balance the openness of generative AI foundation models with responsible governance…(More)”
Book by Cass R. Sunstein: “New technologies are offering companies, politicians, and others unprecedented opportunity to manipulate us. Sometimes we are given the illusion of power – of freedom – through choice, yet the game is rigged, pushing us in specific directions that lead to less wealth, worse health, and weaker democracy. In, Manipulation, nudge theory pioneer and New York Times bestselling author, Cass Sunstein, offers a new definition of manipulation for the digital age, explains why it is wrong; and shows what we can do about it. He reveals how manipulation compromises freedom and personal agency, while threatening to reduce our well-being; he explains the difference between manipulation and unobjectionable forms of influence, including ‘nudges’; and he lifts the lid on online manipulation and manipulation by artificial intelligence, algorithms, and generative AI, as well as threats posed by deepfakes, social media, and ‘dark patterns,’ which can trick people into giving up time and money. Drawing on decades of groundbreaking research in behavioral science, this landmark book outlines steps we can take to counteract manipulation in our daily lives and offers guidance to protect consumers, investors, and workers…(More)”
Report by Cami Rincon and Jorge Perez: “We find, however, that the adoption of immersive technologies today is most significantly characterised by niche use cases, rather than by widely adopted general-purpose use cases. These uses leverage specialised technical functions to augment particular tasks in distinct sectors.
Despite a decline in attention from regulators, venture capital investors, consumers and the media, alongside growing interest in new advances in generative AI, certain immersive technologies have continued to receive significant enterprise investment and have seen market size growth and improved capabilities reflected in specialised use cases.
Many of these use cases take place in high-impact industries, augment safety-critical tasks and overlap with vulnerable groups, such as children and people receiving mental health care. These factors create significant potential for risk. With these advancements come a host of new regulatory, policy and ethical questions that regulators and policymakers will need to consider.
Rather than treating immersive technologies as ‘general purpose’, to govern them effectively regulators and policymakers may need to look to specific use cases in specific sectors.
Our analysis finds several obstacles that hinder immersive technology products from reaching widespread adoption…(More)”.
Paper by Michał Klincewicz, Mark Alfano, and Amir Ebrahimi Fard: “At least since Francis Bacon, the slogan “knowledge is power” has been used to capture the relationship between decision-making at a group level and information. We know that being able to shape the informational environment for a group is a way to shape their decisions; it is essentially a way to make decisions for them. This paper focuses on strategies that are intentionally, by design, impactful on the decision-making capacities of groups, effectively shaping their ability to take advantage of information in their environment. Among these, the best known are political rhetoric, propaganda, and misinformation. The phenomenon this paper brings out from these is a relatively new strategy, which we call slopaganda. According to The Guardian, News Corp Australia is currently churning out 3000 “local” generative AI (GAI) stories each week. In the coming years, such “generative AI slop” will present multiple knowledge-related (epistemic) challenges. We draw on contemporary research in cognitive science and artificial intelligence to diagnose the problem of slopaganda, describe some recent troubling cases, then suggest several interventions that may help to counter slopaganda…(More)”.
Article by Rod Schoonover, Daniel P. Aldrich, and Daniel Hoyer: “The emergent reality of complex risk demands a fundamental change in how we conceptualize it. To date, policymakers, risk managers, and insurers—to say nothing of ordinary people—have consistently treated disasters as isolated events. Our mental model imagines a linear progression of unfortunate, unpredictable episodes, unfolding without relation to one another or to their own long-term and widely distributed effects. A hurricane makes landfall, we rebuild, we move on. A pandemic emerges, we develop vaccines, we return to normal.
This outdated model of risk leads to reactive, short-sighted policies rather than proactive prevention and preparedness strategies. Key public programs are designed around discrete, historically bounded events, not today’s cascading and compounding crises. For instance, under the US Stafford Act, the Federal Emergency Management Agency (FEMA) must issue separate declarations for each major disaster, delaying aid and fragmenting coordination when multiple hazards strike. The National Flood Insurance Program still relies on historical floodplain maps that by definition underestimate future risks from climate change. Federal crop insurance supports farmers against crop losses from drought, excess moisture, damaging freezes, hail, wind, and disease, but today diverse stressors such as extreme heat and pollinator loss are converging with other known risks.
Our struggle to grasp complex risk has roots in human psychology. The well-documented tendency of humans is to notice and focus on immediate, visible dangers rather than long-term or abstract ones. Even when we can recognize such longer-term and larger-scale threats, we typically put them aside to focus on more immediate and tangible short-term threats. As a result, lawmakers and emergency managers, like people in general, often succumb to what psychologists and cognitive scientists call the availability heuristic: Policies are designed to react to whatever is most salient, which tends to be the most recent, most dramatic incidents—those most readily available to the mind.
These habits—and the policies that reflect them—do not account for the slow onset of risks, or their intersection with other sources of hazard, during the time when disaster might be prevented. Additionally, both cognitive biases and financial incentives may lead people to discount future risks, even when their probability and likely impact are well understood, and to struggle with conceptualizing phenomena that operate on global scales. Our mental processes are good at understanding immediate, tangible risk, not complex risk scenarios evolving over time and space…(More)”.
Article by Yuen Yuen Ang: “Every September, world leaders gather in New York City for the United Nations General Assembly. They come weighed down by climate disasters, widening inequality, democratic erosion, trade wars, and threats to multilateralism. They leave with heavier burdens than when they arrived.
We now have a fashionable word for this convergence of problems: polycrisis. Since the Columbia historian Adam Tooze popularized it at the World Economic Forum in 2023, it has become the apocalyptic buzzword of the decade. Tooze himself was disarmingly frank in admitting that he was only giving fear a name.
What the polycrisis concept says is: Relax, this is actually the condition of our current moment. I think that’s useful, giving the sense a name. It’s therapeutic. Here is your fear, here is something that fundamentally distresses you. That is what it might be called.
Therapy, maybe. Diagnosis, no. Solutions, zero. Yet “polycrisis” has caught on worldwide.
Why? Because it is comfortable. Polycrisis is a descriptor that the establishment can agree on without challenging itself. It abstracts the causes of crises, making them appear as natural convergences rather than the systemic outcomes of extractive and exclusionary orders. And it makes the concept appear global when in fact the voices, experiences, and priorities it reflects are overwhelmingly Eurocentric.
The virality of polycrisis reveals something deeper: the enduring power of elite discourse. Even though the term is empty, its followers amplify it—and the echo reinforces paralysis. If leaders remain content with only naming fear, they will consign themselves to irrelevance.
I see things differently. I call this moment a polytunity—a term I coined in 2024 to reframe disruption not as paralysis but as a once-in-a-generation opportunity for deep transformation. Transformation not only of our institutions, but of our ideas, our paradigm, and the way we think…(More)”.
Book by Eduardo Albrecht: “Governments now routinely use AI-based software to gather information about citizens and determine the level of privacy a person can enjoy, how far they can travel, what public benefits they may receive, and what they can and cannot say publicly. What input do citizens have in how these machines think?
In Political Automation, Eduardo Albrecht explores this question in various domains, including policing, national security, and international peacekeeping. Drawing upon interviews with rights activists, Albrecht examines popular attempts to interact with this novel form of algorithmic governance so far. He then proposes the idea of a Third House, a virtual chamber that legislates exclusively on AI in government decision-making and is based on principles of direct democracy, unlike existing upper and lower houses that are representative. Digital citizens, AI powered replicas of ourselves, would act as our personal emissaries to this Third House. An in-depth look at how political automation impacts the lives of citizens, this book addresses the challenges at the heart of automation in public policy decision-making and offers a way forward…(More)”.
UNICEF Report: “Young people across the Pacific Islands bring creativity, skills, and insights that can drive social, economic, and political development. Yet research conducted by UNICEF in eight Pacific countries – Fiji, the Federated States of Micronesia, Kiribati, Palau, Samoa, Solomon Islands, Tonga and Vanuatu – shows that many youth have limited opportunities to meaningfully participate in decision-making processes at community and national levels.
The study mapped youth networks and initiatives, while assessing enabling environments for participation. It engaged more than 1,300 stakeholders through interviews, focus group discussions, and surveys, revealing both opportunities and barriers. While youth are often active in church and community groups, their involvement rarely translates into real influence. Marginalized groups, including young women and youth with disabilities, face even greater challenges.
Some promising practices were identified, such as youth groups initiating local projects and governments involving young people in policy consultations. National Youth Councils also play a critical role, although their effectiveness varies depending on resources and government support. NGOs and youth-led initiatives emerged as strong drivers of participation, highlighting the energy and innovation that young people bring when given the space.
The research concludes that meaningful youth participation requires more than ad hoc engagement. It calls for stronger legal and policy frameworks, sustained investment, and platforms that empower young people with the knowledge, skills, and confidence to influence decisions. Key recommendations include resourcing Youth Councils, supporting youth-led initiatives, ensuring representation of marginalized groups, and fostering leadership opportunities…(More)”.
Article by Elsevier: “… An understanding of how UK research and innovation supports the Government’s five missions would encompass many dimensions, such as the people, infrastructure and resource of the research system, as well its research output.
A new methodology has been developed to map the UK’s research publications to the Government’s five missions. This offers an approach to understanding one dimension of this question and offers insights into others.
Elsevier has created a new AI-powered methodology using Large Language Models to classify research papers into mission areas. Currently in development, we welcome your feedback to help improve it.
For the first time, this approach enables research outputs to be mapped at scale to narrative descriptions of policy priorities, and it has the potential to be applied to other government or policy priorities. This analysis was produced by classifying 20 million articles published between 2019-2023…(More)”.
