Stefaan Verhulst
Paper by Eray Erturk et al: “Wearable devices record physiological and behavioral signals that can improve health predictions. While foundation models are increasingly used for such predictions, they have been primarily applied to low-level sensor data, despite behavioral data often being more informative due to their alignment with physiologically relevant timescales and quantities. We develop foundation models of such behavioral signals using over 2.5B hours of wearable data from 162K individuals, systematically optimizing architectures and tokenization strategies for this unique dataset. Evaluated on 57 health-related tasks, our model shows strong performance across diverse real-world applications including individual-level classification and time-varying health state prediction. The model excels in behavior-driven tasks like sleep prediction, and improves further when combined with representations of raw sensor data. These results underscore the importance of tailoring foundation model design to wearables and demonstrate the potential to enable new health applications…(More)”
Paper by Moritz Schütz, Lukas Kriesch, Sebastian Losacker: “The relevance of institutions for regional development has been well established in economic geography. In this context, local and regional governments play a central role, particularly through place-based and place-sensitive strategies. However, systematic and scalable insights into their priorities and strategies remain limited due to data availability. This paper develops a methodological approach for the comprehensive measurement and analysis of local governance activities using web mining, natural language processing (NLP), and machine learning techniques. We construct a novel dataset by web scraping and extracting cleaned text data from German county and municipality websites, which provides detailed information on local government functions, services, and regulations. Our county-level topic modelling approach identifies 205 topics, from which we select 30 prominent topics to demonstrate the variety of topics found on county websites. An in-depth analysis of the three exemplary topics, Urban Development and Planning, Climate Protection Initiatives, and Business Development and Support, reveals how strategic priorities vary across space and how counties differ in their framing of similar topics. This study offers an explanatory framework for analysing the discursive dimensions of local governance and mapping regional differences in policy focus. In doing so, it expands the methodological toolkit of regional research and opens new avenues in understanding local governance through web data. We make an aggregated version of the data set freely available online…(More)”.
Report by National Academies of Sciences, Engineering, and Medicine: “In recent years, Lidar technology has improved. Additionally, the experiences of state departments of transportation (DOTs) with Lidar have grown, and documentation of existing practices, business uses, and needs would now benefit state DOTs’ efforts.
NCHRP Synthesis 642: Practices for Collecting, Managing, and Using Light Detection and Ranging Data, from TRB’s National Cooperative Highway Research Program, documents state DOTs’ practices related to technical, administrative, policy, and other aspects of collecting, managing, and using Lidar data to support current and future practices…(More)”
Article by Madison Leeson: “Cultural heritage researchers often have to sift through a mountain of data related to the cultural items they study, including reports, museum records, news, and databases. The information in these sources contains a significant amount of unstructured and semi-structured data, including ownership histories (‘provenance’), object descriptions, and timelines, which presents an opportunity to leverage automated systems. Recognising the scale and importance of the issue, researchers at the Italian Institute of Technology’s Centre for Cultural Heritage Technology have fine-tuned three natural language processing (NLP) models to distill key information from these unstructured texts. This was performed within the scope of the EU-funded RITHMS project, which has built a digital platform for law enforcement to trace illicit cultural goods using social network analysis (SNA). The research team aimed to fill the critical gap: how do we transform complex textual records into clean, structured, analysable data?
The paper introduces a streamlined pipeline to create custom, domain-specific datasets from textual heritage records, then trained and fine-tuned NLP models (derived from spaCy) to perform named entity recognition (NER) on challenging inputs like provenance, museum registries, and records of stolen and missing art and artefacts. It evaluates zero-shot models such as GLiNER, and employs Meta’s Llama3 (8B) to bootstrap high-quality annotations, minimising the need for manual labelling of the data. The result? Fine-tuned transformer models (especially on provenance data) significantly outperformed out-of-the-box models, highlighting the power of small, curated training sets in a specialised domain…(More)
Paper by Angelos Assos, Carmel Baharav, Bailey Flanigan, Ariel Procaccia: “Citizens’ assemblies are an increasingly influential form of deliberative democracy, where randomly selected people discuss policy questions. The legitimacy of these assemblies hinges on their representation of the broader population, but participant dropout often leads to an unbalanced composition. In practice, dropouts are replaced by preselected alternates, but existing methods do not address how to choose these alternates. To address this gap, we introduce an optimization framework for alternate selection. Our algorithmic approach, which leverages learning-theoretic machinery, estimates dropout probabilities using historical data and selects alternates to minimize expected misrepresentation. Our theoretical bounds provide guarantees on sample complexity (with implications for computational efficiency) and on loss due to dropout probability mis-estimation. Empirical evaluation using real-world data demonstrates that, compared to the status quo, our method significantly improves representation while requiring fewer alternates…(More)”.
NASA Harvest: “Have you ever thought about how scientists keep track of what is happening all over the Earth? Thanks to satellites orbiting high above us, we have eyes in the sky that capture vast amounts of information every day. These satellites monitor everything from sprawling forests and melting glaciers to tiny fishing boats and fields of crops. But turning this endless stream of satellite data into meaningful insights is a big challenge. That is why a team of researchers from NASA Harvest, the Allen Institute for AI (Ai2) and partner organizations set out to create a smarter solution.
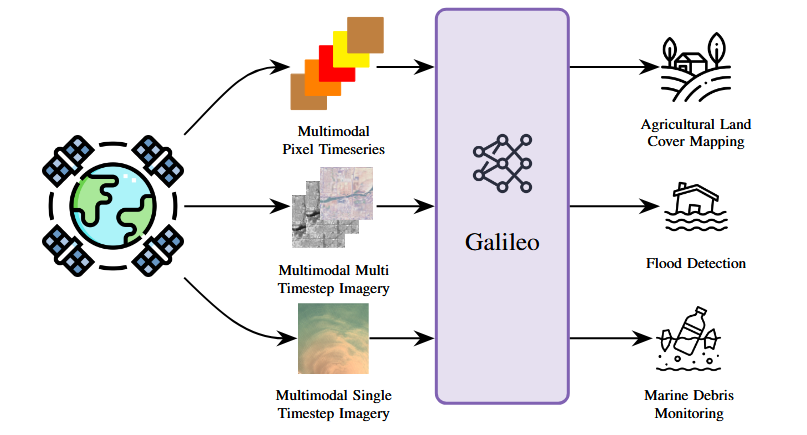
Their new study, titled “Galileo: Learning Global & Local Features of Many Remote Sensing Modalities,” was recently published and brought together experts from across the globe. The team aimed to build a tool that could make better sense of all the different types of satellite data we collect so we can make more informed decisions to protect our world.
Why is this research so important? Because satellites do far more than take pictures from space. They help farmers decide when to plant and harvest crops, track how fast glaciers are disappearing, monitor floods, and even detect marine debris floating in the ocean. However, satellite data comes in many forms, like optical images, radar scans, and climate measurements. Until now, most computer models could only handle one type of data at a time. This meant scientists needed separate systems for each problem.
Enter Galileo. This new artificial intelligence (AI) model was designed to process many kinds of satellite data all at once. Even more impressively, Galileo can detect both large-scale patterns, like glaciers retreating over decades, and tiny, short-lived details, like a fishing boat appearing for just a day. By learning to recognize these patterns across multiple scales and data types, Galileo gives researchers a more complete view of what is happening on Earth.
The team found that Galileo outperformed older models that were specialized for just one kind of data. With Galileo, scientists can now use a single model to tackle a wide range of challenges. These include mapping agricultural land, detecting floods, and monitoring marine pollution. It is a powerful step toward making satellite data more versatile and accessible…(More)”
Editorial to Special Issue by Saeid Pourroostaei Ardakani et al: “Data Analytics in Sustainable City PlanningPredictive analytics play an increasingly central role in sustainable city planning. By applying machine learning algorithms to large-scale and multi-source datasets, cities are able to forecast dynamic phenomena such as traffic congestion, crime incidents, and flood risk. These anticipatory insights are crucial for proactive urban management, allowing for early interventions and resource optimisation. Alongside this, the emergence of Digital Twins marks a shift from reactive to real-time urban governance. As a result, cities such as Singapore, Los Angeles, and Amsterdam improve these models to manage infrastructure across sectors including transportation, water supply, energy distribution, and public space usage. These digital ecosystems enable planners to test policy scenarios, monitor service performance, and respond adaptively to changing conditions.
The integration of socio-demographic data into geospatial models enables researchers to identify and analyse disparities in urban vulnerability. For instance, spatial mapping of heat exposure in Indian cities such as Delhi and Bengaluru has informed the more equitable allocation of cooling infrastructure. These equity-oriented approaches ensure that sustainability initiatives are not only technically robust but also socially inclusive. Indeed, they support policymakers in targeting resources toward the most vulnerable populations and thereby addressing persistent inequalities in urban service delivery.
The role of participatory digital platforms is a critical dimension of the sustainable planning discourse. Cities are increasingly turning to the use of GIS tools and e-planning applications to facilitate community involvement in the urban design process. These tools democratise access to data and decision-making and enable citizens to co-create solutions for their neighbourhoods. Such participation enhances the legitimacy and responsiveness of urban policy especially in contexts where historically marginalised groups have been excluded from formal planning mechanisms…(More)”.
Book by Ronald Bradfield: “Organizations today face an increasingly complex contextual environment. The intensity of what is recognized as a VUCA world has changed how they view the world, interact with each other, and respond to this environment.
Understanding the Future shows individuals and organizations how to develop scenario planning, using the Intuitive Logics (IL) model, to perceive what is happening in the business environment and how to improve strategic decision-making to plan for uncertainty.
Ronald Bradfield, a renowned scenario planning practitioner, traces the origins of scenario planning from its evolution to associated techniques and details the IL development process from Stage 1 to Stage 5. He includes an insightful chapter on how people think, describing the role of heuristics and biases, reviewing some of the commonly known ones, and concludes with the pros and cons of the IL model.
This book includes extensive reference material: appendices, a list of Foresight and Scenario organizations, Futures journals and magazines, published scenarios, select readings and guides, and the author’s unique case material directly from his world-leading consulting work of the past 30 years.
Understanding the Future is an exceptional, comprehensive guide for postgrads, practitioners, leaders, policymakers and anyone involved in organizational development or management risk who needs to understand the IL scenario framework and its value in addressing organizational challenges amidst complexity…(More)”.
Book by Luca Mora et al: “…explores how to govern the planning, implementation, and maintenance operations in smart city projects and transitions, and the urban digitalization processes that may potentially trigger. It provides readers with the evidence-based knowledge they need to approach the complexity of smart city governance, responding to the United Nations’ call for more advanced strategic and technical support on urban digital transformations to national, regional, and local governments. The book uses a comprehensive framework that details what configuration of multi-level components should be considered in the governance of smart city transitions…(More)”.
Book by Mark Findlay,: “This prescient book examines social ordering and governance in the digital universe. It demonstrates how attempts to enact regulations in virtual spaces cannot replicate laws and market arrangements in the real world, advocating for an alternative ‘new law’ to enable safe, sustainable and beneficial digital communities.
Mark Findlay discusses how this ‘new law’ could be achieved and the challenges it might face, addressing ideas of inclusive and collaborative governance, digital self-determination and communal bonding in virtual spaces. He outlines the differences between the metaverse and ‘realspace’ which call into question conventional legal reasoning and appreciations, rethinking current reductive paradigms of the virtual universe as an outpost for private property and exchange markets. Governing the Metaverse ultimately explores the notion of law as an enabler of change rather than an enforcer of the status quo and emphasises the potential of this more adaptable interpretation of the law to create an empowering digital world.
Students and scholars of constitutional and administrative law, law and politics and internet and technology law will greatly benefit from this thought-provoking book. It is also a vital resource for policymakers and practitioners in the fields of public policy, regulation and governance and technology and IT…(More)”.