Stefaan Verhulst
Paper by Elettra Bietti: “The ability to direct and receive attention is constitutive of human life. Humans have an inborn need for attention, and an inborn ability to direct attention for survival. Yet attention is not just a creature of an individual’s mind. It is a relationship between people and their environment. As such, our attention is shaped by the material, social and economic conditions that surround us. Today, people’s attention is increasingly extracted and colonized through technology. Attention platforms and AI technologies are transforming the shape, objects, metrics and value of human time and attention.
This article focuses on the role of data-attention platforms in transforming time and attention. Data-attention platforms include social media platforms such as Facebook, YouTube, TikTok, and increasingly AI companions such as Replika or Character.AI. They capture data and attention and draw revenues from them, primarily but not exclusively through surveillance advertising. The business models of data-attention platforms are organized around the data-attention imperative, the drive to continuously capture troves of data and attention to generate value. They capture eyeballs to sell ads and collect data to target ads and maximize engagement. Time online enables more data collection, which, in turn allows for the design of products that more effectively addict users. This extractive data-attention spiral produces a harmful commodification and erosion of time and attention which shrinks the human experience and undermines collective life.
This article asks how governments should and shouldn’t regulate data-attention platform business models and the distortions they cause. It is tempting to reduce growing data-attention disorders to problems of individual choice online, delegating solutions to market-based tools, more competition or the exercise of individual data protection rights and parental controls. Instead, the answer requires moving past individual preferences and embracing an infrastructural approach focused on changing platform incentives and technological affordances and on safeguarding space for offline time. Privacy and data protection, child social media regulations and productivity tools provide for controls and safeguards that too often magnify instead of addressing attention disorders. The idea of individual autonomy that underlies them is unfit for the attention era. The article advocates a conception that takes the power of platforms to shape our attention seriously and advocates for the protection of children and adults’ time away from technology. Time away from technology is a collective good in need of protection. Based on a three-fold agenda that incorporates design changes, taxation, and legal reform to reduce time spent online as well as the speed and scale of the digital experience, the article aims to bring attention platform ecosystems in greater alignment with the interests of society without placing unrealistic expectations on individual users and parents…(More)”.
Article by Tom Fleischman: “It was born in northern New Mexico, the brainchild of then-Los Alamos National Laboratory physicist Paul Ginsparg, Ph.D. ’81, as a simple way for researchers to share their work with colleagues before it appeared in peer-reviewed journals.
When Ginsparg returned to Cornell as a professor in 2001, he brought the online research repository arXiv with him. And for 25 years it has remained at Cornell, where it has grown into a global clearinghouse for millions of research papers, accessible to anyone with an internet connection.
Now, arXiv embarks on its next chapter: a transition to an independent nonprofit. The move will enable faster technological development, greater organizational flexibility, expanded partnerships and long-term financial sustainability.
“This is something we’ve talked about for a long time,” said Greg Morrisett, the Jack and Rilla Neafsey Dean of Cornell Tech, where arXiv is headquartered. “To make sure for the long run that it was going to be supported, well beyond a particular dean valuing it, we felt like it was a responsible thing to do.”
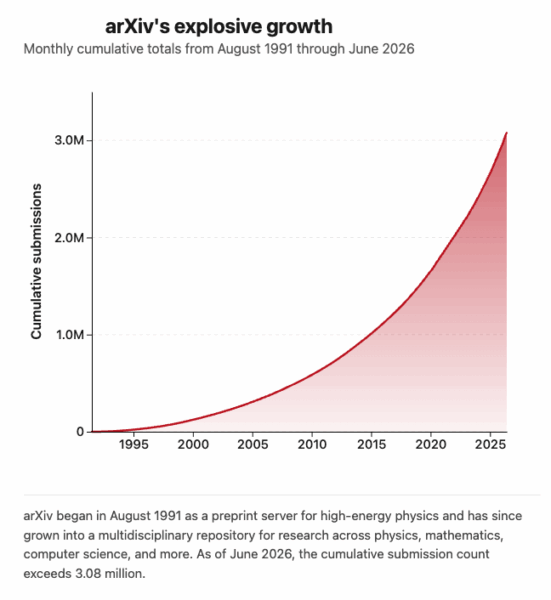
The move will become official July 1; arXiv headquarters will remain in Cornell Tech’s Tata Innovation Center. The search is on for an inaugural CEO as well as a board of directors…(More)”.
Article by Stefaan Verhulst: “Official statistics have long served as the bedrock of evidence-based policymaking in the United States, but the ground beneath them is shifting. Survey response rates are falling; collection costs are rising; privacy concerns are mounting; and public trust in government information has eroded just as the questions policymakers must answer—about digital inclusion, financial resilience, climate impacts, mobility, and economic opportunity—have grown more complex and time-sensitive. The statistical systems built for a slower, more uniform economy were never designed to keep pace with a society this dynamic.
Out of this tension has come a quiet but consequential shift: the rise of the re-use of non-traditional data, or NTD. Generated continuously through commercial transactions, digital platforms, connected devices, satellites, financial institutions, mobility services, and online interactions, this data was never collected with statistical production in mind. Yet when it is responsibly governed and woven together with surveys, censuses, and administrative records, it gives statistical agencies something they have always wanted but rarely had: a near-continuous, granular window into economic and social life. The promise is not that non-traditional data will replace official statistics but that it will make them faster, cheaper, and more relevant—while asking less of the public in the process.
As in other countries, the United States has become a testing ground for this hybrid approach. Federal statistical agencies — the Census Bureau, the Bureau of Labor Statistics, and the Bureau of Economic Analysis among them — have increasingly partnered with universities, nonprofits, philanthropies, and private companies to explore what non-traditional data can offer. Outside government, organizations such as Opportunity Insights, the JP MorganChase Institute, Microsoft Research, Mastercard’s Center for Inclusive Growth, and Meta’s Data for Good program have shown that privately held, passively generated data can produce policy-relevant indicators that official statistics alone cannot.
What emerges from these efforts is not competition between data sources but complementarity. Surveys still offer representativeness (“ground truth”) and rich context; administrative records still offer comprehensive population coverage; and non-traditional data contributes something that is often limited in both: timeliness, granularity, and the ability to see change as it happens rather than months later.
The examples that follow provide a snapshot of current experimentation in the United States. They are not intended to be exhaustive, but rather to illustrate the diversity of approaches through which non-traditional data is being integrated with surveys, censuses, and administrative records to strengthen official statistics and inform public decision-making…(More)”.
Book by Sherry Turkle: “If social media came for our attention, artificial intelligence is now coming for our capacity for attachment. Chatbots that speak to us in a human voice offer themselves as best friends, lovers, and psychotherapists. As of 2025, over 70% of teens and nearly one-third of US adults rely on AI for companionship and emotional support, with many preferring these chatbot relationships over human ones.
When we talk to chatbots in these roles, as intimate machines, we accept as sufficient what machines can offer: the mere performance of intimacy, empathy, and love. We begin to think that pretend empathy is empathy enough. We redefine human capacities for care, solitude, and intimacy in terms of what machines can do. Sherry Turkle, the psychologist who pioneered our understanding of human-computer relationships, calls the new culture of chatbots artificial intimacy, our new AI.
Through compelling storytelling, framed by Turkle’s decades of experience as a chronicler and analyst of digital culture, Artificial Intimacy evokes the seductive and beguiling nature of chatbots. They can organize our calendars, plan our travel, or analyze our stock picks, all with an efficiency that outstrips what a person might do.
And then, they promise to be more—to be our “perfect” companion. They will always be there for us, listen to us, and support us—and ask for nothing in return. But these intimate machines, warns Turkle, are producing a generation more alienated, depressed, and lonely than ever before. More than that, we become less equipped to reverse course—machine relationships do not offer practice for getting along with people.
Artificial Intimacy is unique in how it traces our new habit of talking to machines through the lifecycle—from children’s earliest attachments to how we face death. But technology, by offering to do everything, teaches us that we neither need nor have the capacity to take risks, have hard conversations, struggle through uncertainty or insecurity, or rely on our own faculties and judgment.
Turkle has spent decades studying how digital technologies isolate us from one another. Now, in her long-awaited follow-up to Reclaiming Conversation, she offers both a cautionary tale and a roadmap for reclaiming our humanity in the age of AI…(More)”.
Press Release: “The Kluz Prize for PeaceTech is an annual initiative that seeks to support and accelerate innovative technologies that are being used to save lives, foster peace, reduce conflict, and safeguard human rights and dignity around the world.
The Prize seeks to support tech companies, peace and humanitarian organizations and initiatives, particularly those initiated by the younger generation and the tech community, including entrepreneurs, engineers, programmers, scientists, startups, accelerators, and venture capitalists. It recognizes their distinguished achievements in building peaceful and resilient societies.
Selected by a distinguished Selection Committee, the winner(s) will receive a $20,000 grant to advance their work. Additionally, special distinctions will be awarded to organizations depending on quality of proposals who will all be invited to present their achievements at the awards ceremony, which will take place in New York City in September in conjunction with the United Nations General Assembly and the International Day of Peace…(More)”.
OECD Report: “Governments operate in a context of rising public expectations and complex policy challenges, while also facing a critical window of opportunity to adapt and reform institutions and policies to better respond to these needs. In democracies, a healthy level of trust in public institutions will be critical to the implementation of these reforms.
The third OECD Survey on Drivers of Trust in Public Institutions provides comparable actionable evidence on levels and key drivers of trust across 33 OECD countries and 5 OECD accession candidate countries in 2025…
Overall trust levels in national government have stabilised at around 40%, while trust remains higher in the civil service, police and courts…
43% of people across OECD countries have low or no trust in the national government, compared with 40% with high or moderately high trust. As per previous survey waves, there are significant variations across countries and population groups. While there was a small decrease in trust in 2023 compared to 2021, trust levels have since stabilised, and substantially improved in about half of the countries where it had previously declined. In most countries, trust in the police, courts, local government and civil service is higher than in national government…(More)”.
Report by Merici Vinton & Faith Savaiano & Laura Sigelmann: “The book Good Strategy/Bad Strategy by Richard P. Rumelt states “Good strategy works by focusing energy and resources on one, or a very few, pivotal objectives whose accomplishment will lead to a cascade of favorable outcomes.”
In every retrospective we hosted, participants bemoaned the lack of a strategy and a longer-term theory of change in their work, or “how”, tied to outcomes. No shared strategy of work and functional purpose across the federal teams – USDS, 18F/TTS, OFCIO, and beyond – led to confusion, competition for limited resources, and a focus on individual team or organizational goals rather than shared agency- or government-wide outcomes. No shared strategy for mission outcomes at the government-wide or agency level meant we heard time and time again during the retros that teams at all levels of government felt like they were missing a chance at making an even greater, deeper impact. In the absence of such shared mission outcomes, digital service teams felt like their participation was the metric for success and their activity was a substitute for long-term progress. This is emblematic of a systemic problem – digital service initiatives operate within silos, compete for limited resources and talent, and often operate at agencies that lack a clear sense of how digital service initiatives contribute to their goals, ultimately diminishing the impact.
The lack of strategy impacted not just the teammates trying to do the work, it also impacted the agencies and stakeholders digital service teams interact with. A strategy defines a set of priorities that is repeatable and accountable, making it easier to partner, delegate, and work fast; it also communicates what you don’t want to work on, transparently outlining priorities. For digital service teams, strategy was absent but should exist at multiple levels. At the highest level, it articulates the theory for how digital services contribute to societal outcomes – how digital and service design improves public health through better access to benefits such as SNAP, or simplified access to healthcare. Strategy also exists at the government-wide level, defining priorities and processes for achieving those outcomes. And at the organizational and functional level, strategy defines the logic model for how diverse teams – including crisis response, modernization, implementation, product building, and operations and maintenance – work together across government.
And now, at a moment of significant technological change and demands on government, the stakes of having no strategy at each of these levels are higher than ever. Without a clear position on AI, government won’t even get their tactics right — they’ll spend all their time debating tools instead of outcomes. A strategy doesn’t require consensus. It is a signal of what you value, and provides the concrete steps to get what you’re trying to achieve, and why — so that people can ignore it, engage with it, challenge it, or build on it.
Moving forward, the digital service community should be a part of articulating an ambitious, outcomes based strategy at each level for what we want to achieve across the country in the next 5-10-20 years; and to look at defining foundational elements that make a strategy effective: building user-centered government and how to reform our institutions to become modern, responsive organizations…(More)”.
Research project by Audrey Tang and Caroline Emmer De Albuquerque Green: “Governance should feel like a daily capability, not just a periodic vote.
Civic AI is artificial intelligence that answers to the people it affects. Instead of one powerful system built to govern everyone, the idea is to build many small ones that a community can own, inspect, correct, and switch off.
Each of these local stewards has a name — the Kami (knowledge artefact management intelligence): a spirit of place, not a universal governor…
Just heard about Civic AI? Three steps in.
- Get the idea. Read the Manifesto — the whole argument in Audrey Tang’s own words.
- Meet the six principles. Skim the 6-Pack below: six plain-language tests for AI a community can actually trust.
- See it work. “AI Alignment Cannot Be Top-Down” tells how Taiwan answered a wave of AI-enabled scam ads — the framework in the real world.
Prefer to listen? Take the 6-Pack of Care podcast or “Can AI Be Compassionate?” along for a walk. Prefer to watch? Audrey and Caroline introduce the framework in “Reimagining AI Alignment” — a 30-minute fireside chat.
Prefer visuals? Browse all comics — Nicky Case’s illustrated overview and twelve chapter pages…(More)”
Article by Beth Noveck: “For decades, many scholars and policymakers have treated public participation as a problem to be managed rather than a resource to be cultivated. This “realist” view, which gained prominence after World War II with the growth of money in politics, treated participation as destabilizing. Many academics even challenged the notion that ordinary Americans have the time, competence, or capacity to participate, writing off the public as incapable.
This skepticism has led institutions to design consultation processes more as exercises in public relations than as genuine attempts to share power. And when we evaluate democratic innovations, it leads us to focus on metrics like participation rates rather than actual policy impact.
Brazil’s experience suggests that participation becomes meaningful only when it is connected to decision-making. What makes this moment different is that artificial intelligence may finally give institutions the capacity to hear, organize, and act on public input at a scale that was previously impossible.
Unlike earlier Web-based platforms that only expanded the volume of talking, we can use AI to make sense of the collective intelligence of our communities and uncover better ways to connect participation to decisions and action.
The challenge is no longer getting people to speak. It is building institutions capable of listening.
(Adapted from Reboot: AI and The Race to Save Democracy, Yale University Press, 2026.)…(More)”.
Book edited by Jane E Fountain, Sorin Dan, and Niina Mäntylä: “This book examines the relationship between artificial intelligence and power in government. The growth of AI has drastically altered the political landscape, and the shifting power relationships between actors involved in deploying AI have the potential to radically impact the ways in which this technology is understood, adopted and implemented in government.
Drawing together scholars from public policy, public management, information technology and law, this volume throws light on the implications that AI poses for existing power relationships between actors involved in the deployment and use of AI in government, and for existing power relationships between the state and citizens. It addresses these issues through three disciplinary perspectives – legal and regulatory studies, public policy and governance, and public management and innovation – in order to fully assess the interplay between AI and power in different governmental settings across the world. Chapters examine a range of themes pertinent to AI and governance, including the exercise of power, liability issues, ethical policymaking, surveillance, and the use of AI tools in public organizations. A concluding chapter maps out future directions for the study of AI and power in government…(More)”.