Paper by Corina Pascu and Jean-Claude Burgelman: “Given this irreversibility of data driven and reproducible science and the role machines will play in that, it is foreseeable that the production of scientific knowledge will be more like a constant flow of updated data driven outputs, rather than a unique publication/article of some sort. Indeed, the future of scholarly publishing will be more based on the publication of data/insights with the article as a narrative.
For open data to be valuable, reproducibility is a sine qua non (King2011; Piwowar, Vision and Whitlock2011) and—equally important as most of the societal grand challenges require several sciences to work together—essential for interdisciplinarity.
This trend correlates with the already ongoing observed epistemic shift in the rationale of science: from demonstrating the absolute truth via a unique narrative (article or publication), to the best possible understanding what at that moment is needed to move forward in the production of knowledge to address problem “X” (de Regt2017).
Science in the 21st century will be thus be more “liquid,” enabled by open science and data practices and supported or even co-produced by artificial intelligence (AI) tools and services, and thus a continuous flow of knowledge produced and used by (mainly) machines and people. In this paradigm, an article will be the “atomic” entity and often the least important output of the knowledge stream and scholarship production. Publishing will offer in the first place a platform where all parts of the knowledge stream will be made available as such via peer review.
The new frontier in open science as well as where most of future revenue will be made, will be via value added data services (such as mining, intelligence, and networking) for people and machines. The use of AI is on the rise in society, but also on all aspects of research and science: what can be put in an algorithm will be put; the machines and deep learning add factor “X.”
AI services for science 4 are already being made along the research process: data discovery and analysis and knowledge extraction out of research artefacts are accelerated with the use of AI. AI technologies also help to maximize the efficiency of the publishing process and make peer-review more objective5 (Table 1).
Table 1. Examples of AI services for science already being developed
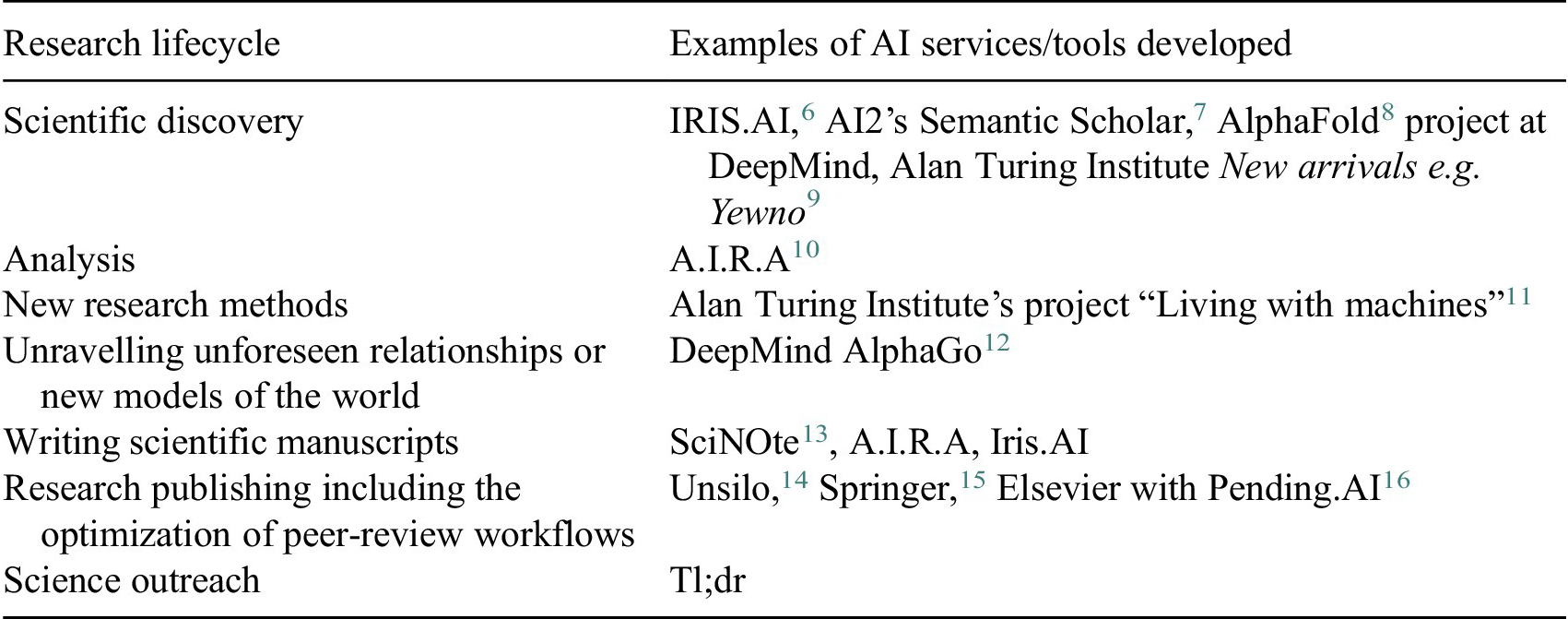
Abbreviation: AI, artificial intelligence.
Source: Authors’ research based on public sources, 2021.
Ultimately, actionable knowledge and translation of its benefits to society will be handled by humans in the “machine era” for decades to come. But as computers are indispensable research assistants, we need to make what we publish understandable to them.
The availability of data that are “FAIR by design” and shared Application Programming Interfaces (APIs) will allow new ways of collaboration between scientists and machines to make the best use of research digital objects of any kind. The more findable, accessible, interoperable, and reusable (FAIR) data resources will become available, the more it will be possible to use AI to extract and analyze new valuable information. The main challenge is to master the interoperability and quality of research data…(More)”.