Article by Duncan C. McElfresh: “Say you run a hospital and you want to estimate which patients have the highest risk of deterioration so that your staff can prioritize their care1. You create a spreadsheet in which there is a row for each patient, and columns for relevant attributes, such as age or blood-oxygen level. The final column records whether the person deteriorated during their stay. You can then fit a mathematical model to these data to estimate an incoming patient’s deterioration risk. This is a classic example of tabular machine learning, a technique that uses tables of data to make inferences. This usually involves developing — and training — a bespoke model for each task. Writing in Nature, Hollmann et al.report a model that can perform tabular machine learning on any data set without being trained specifically to do so.
Tabular machine learning shares a rich history with statistics and data science. Its methods are foundational to modern artificial intelligence (AI) systems, including large language models (LLMs), and its influence cannot be overstated. Indeed, many online experiences are shaped by tabular machine-learning models, which recommend products, generate advertisements and moderate social-media content3. Essential industries such as healthcare and finance are also steadily, if cautiously, moving towards increasing their use of AI.
Despite the field’s maturity, Hollmann and colleagues’ advance could be revolutionary. The authors’ contribution is known as a foundation model, which is a general-purpose model that can be used in a range of settings. You might already have encountered foundation models, perhaps unknowingly, through AI tools, such as ChatGPT and Stable Diffusion. These models enable a single tool to offer varied capabilities, including text translation and image generation. So what does a foundation model for tabular machine learning look like?
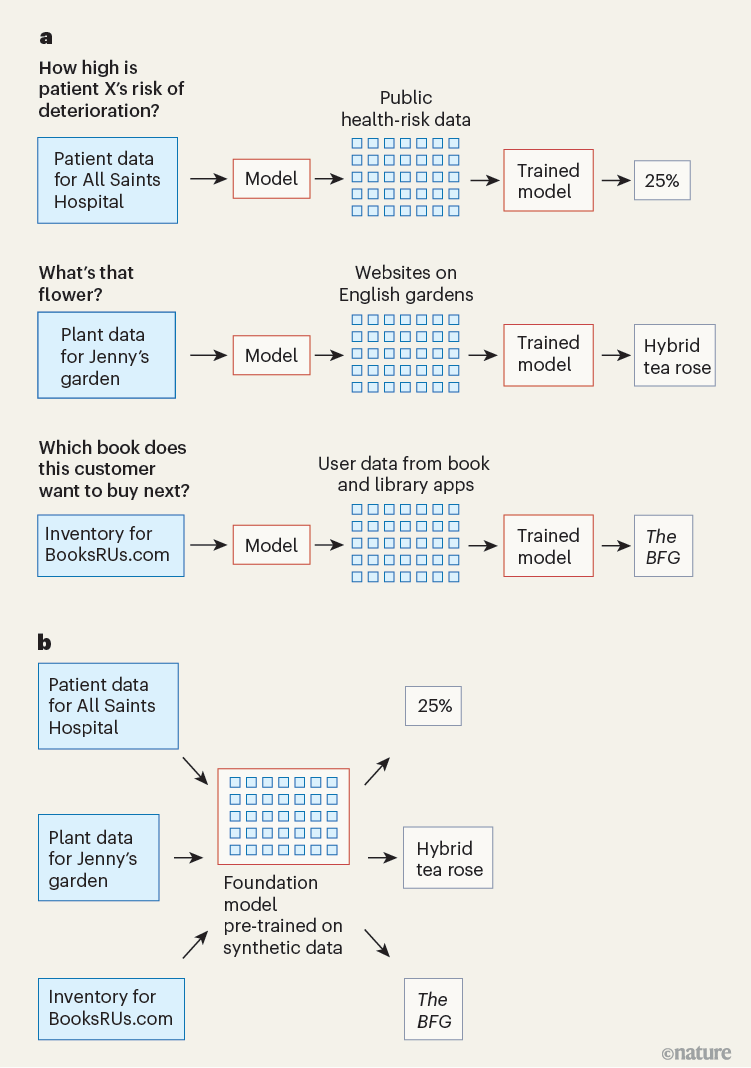
Let’s return to the hospital example. With spreadsheet in hand, you choose a machine-learning model (such as a neural network) and train the model with your data, using an algorithm that adjusts the model’s parameters to optimize its predictive performance (Fig. 1a). Typically, you would train several such models before selecting one to use — a labour-intensive process that requires considerable time and expertise. And of course, this process must be repeated for each unique task.