Stefaan Verhulst
Article by Thomas Brent: “Latvia has introduced an element of citizen engagement to the evaluation of nationally funded research grants. The aim is to both create more connections between science and society, and to improve the quality of its evaluations.
The move comes as research funders across Europe are experimenting with ways to improve evaluation processes in the face of a sharpened focus on science’s impact on society.
Evaluators of grant applications submitted to Latvia’s Fundamental and Applied Research Programme (FLPP), the country’s main research funder, will this year have the option of consulting citizen feedback on challenges the public thinks science should focus on to inform their decisions.
“In recent years, both public discussions and policy-level debates in Latvia have highlighted the importance of demonstrating how publicly funded research contributes to society, the economy and the resolution of real-world challenges,” said a source at the Latvian Council of Science (LCS), which manages the FLPP.
“At the same time, research institutions themselves expressed interest in improving the project evaluation framework while continuing to ensure that funding is awarded to the highest-quality projects,” the source added.
The citizen input comes from a survey that was conducted between 25 February and 16 March 2025, to which 1,737 people responded. It gathered information on what the public views as problem areas for Latvia, and the role of science and technology in providing solutions to these problems.
A summary of these responses has been included as an annex to the FLPP 2026 call for proposals that evaluators can refer to, purely in an advisory manner, when judging proposals.
Results from the survey show that the main problem areas identified by the public were in healthcare and public health, followed by the development of new treatment methods and medicines, and then digital technology, data security and cyber security. At the bottom of the list was research aimed at acquiring new knowledge about the universe, matter and the laws of nature…(More)”.
Article by Jay Caspian Kang: “There will always be idealistic, ink-stained people who want to devote their lives to scholarly pursuits—their role to inspire young people to love ideas as they do. But this transfer, more than anything else in the academy, has been increasingly blocked by A.I. in the classroom. This past April, Jane Sloan Peters, a professor of religious studies, wrote a stirring Substack post in which she described a course she had designed, some years ago, about what people throughout history have been willing to endure for their faith. The class, called “Letters from Prison,” typically culminated in students trying to synthesize an overriding theme about what they had read. “When I began teaching this course four years ago, students struggled to come up with their own themes,” Peters wrote. But, through brainstorming and revision, the students would ultimately land on some understanding that both felt personal to them and proved they had grappled with the assigned texts.
Last year, the struggle ended—or, at least, got subverted. “Not one of my sixty students in ‘Letters from Prison’ struggled with this task,” she wrote. “I received tidy summaries of the text—the kind of compelling reviews you’d find on a book jacket—as well as perfectly vapid course themes that somehow took account of everything while not saying much.” What Peters suspected was that many of the students had asked A.I. to help. Like so many professors who have been confronted with the dispiriting new reality of student work, Peters adjusted, adding some handwritten brainstorming processes to her course, in the hope of making it A.I.-proof. But when she presented these new expectations to her students, something unexpected happened. “A wave of sadness washed over me, and I actually got choked up in front of the class.” Peters writes. “ ‘Before AI,’ I told them, ‘Students used to work hard to come up with their own ideas. I’d help, and they’d struggle, but they’d come to something that was their own. That doesn’t happen anymore and I grieve that.’ ”…(More)”
Article by Andrew Schroeder, Lauren Bateman, John Crowley, Satchit Balsari, Nishant Kishore, Jennifer Chan: “Meanwhile, global digital humanitarians and remote data providers have begun to heed the call to “fight Ebola with information”. Almost immediately following the epidemic declaration, Humanitarian OpenStreetMap Team (HOT) coordinated with Médecins Sans Frontières to launch a set of tasks for the global digital mapping community to use high resolution satellite imagery to update building footprints, roads, critical infrastructure, and other features for the creation of maps to aid in population estimations, community surveys, contact tracing, and other epidemic control efforts. Their efforts have been buttressed by releases of satellite imagery from Vantor. Satellogic and Planet have also made satellite imagery available.
Other key organizations have stepped forward as well. Flowminder has been regularly publishing analysis of human mobility flows to and from the epidemic affected areas based on digital device data from the mobile network operator Vodacom. These flow maps allow for rapid prioritization of epidemic control efforts based on anticipation of probable case transmission areas. WorldPop and GRID3 have published high resolution baseline population data as well as accurate health facility locations to aid with planning for health services and calculations of baselines for population exposures, among other essential analyses. The Armed Conflict Location and Event Data (ACLED) project is publishing regularly updated geospatially specific conflict data to assist in understanding changing security risks and other threats to affected communities and to the response effort. UN OCHA’s Humanitarian Data Exchange (HDX) platform is now hosting more than 40 datasets specifically relevant to the current response in DRC, although a reasonably high number of these are topically filtered extracts from OpenStreetMap.
If we look above the proverbial “water line” of the information iceberg at what is publicly visible, easily traceable, and known to be in use by response actors, we can see significant gains in key areas. These include small area demographics, building footprint and infrastructure mapping, remote sensing, event alerting, and case reporting.
Right at the waterline, where novel datasets and models are emerging now into routine visibility and usage, we find human mobility flows based on mobile device data. Flowminder’s data from Vodacom has been integrated into several risk models. At this level we also see a range of disease forecast models and dashboards, at different levels of spatial and temporal resolution, some of which may be based on very similar data and distributed across opaque and discontinuous channels.
What is most concerning though is what still lies below the waterline, where needs may be unmet and substantial gaps in data, information, and analysis likely exist. For instance, as of now there does not appear to be a common list of ebola treatment units available publicly. Data on safe burials is largely absent. Misinformation, as is now normally the case online, runs rampant without an obvious rumor cataloguing effort, or community information management. Logistics and supply chain needs are referenced constantly by response agencies, particularly for PPE and sanitation, but supply chain flows are largely undocumented publicly, and in any event not obviously connected to the epidemiological forecasts and risk assessments despite clear calls from WHO for strategic prepositioning of essential supplies. Health facility locations are widely circulated, but facility-level capacity in terms of staffing, equipment, and supplies, is ambiguous at best. Epidemiological forecasts and risk analyses are not obviously connected to any particular workflows on logistics and supply chain…(More)”.
OECD Report: “People expect their government to act quickly, adapt to change and respond effectively, putting pressure on public institutions to keep up. Digital technologies and data are integral to meeting these demands: they have become core infrastructure for governments to perform and address today’s policy and service delivery challenges.
This reportpresents results from the OECD Digital Government Index (DGI) and the Open, Useful and Re-usable Data Index (OURdata), illustrating how governments across 36 OECD countries and 8 accession countries have been improving coherent, effective and human-centred digital transformation in government in recent years...(More)”.
Article by Geoff Mulgan: “We live in a world full of lies, distortions and misinformation. Should we have rights to be told the truth, or at least not to be lied to? If a government issues a statistic, a report, or a warning to its citizens, should any rights guarantee that it’s based on the best available information? Should there be penalties if a company or a political party, knowingly lies? If a doctor gives you a diagnosis, should it be your right that the diagnosis is based on the best possible medical knowledge? If a company has your pension invested in it, should any rights guarantee that their accounts are as accurate as possible?
It might seem reasonable that any institution which claims to serve us should give us the respect of telling the truth. Yet no constitution guarantees that right. The US constitution protects rights of free speech, but no rights to truth. British law supports many rights, but not this one. Nor does the European Convention on Human Rights, which supports freedom of thought and expression, but no rights to information or truth.
In this piece I set out why such rights are needed, and what they might mean. I show why existing laws in finance and consumer advertising can be built on, as well as recent ones designed to address the problems of deception on social media. I show why some of the assumptions of liberalism have become a barrier to action, and why freedom depends on truth. And I show why rights to truth could help harness the populist anger against the deceit and self-serving of powerful institutions in a more constructive direction. Finally, I address the main counter-arguments, which essentially say that no-one, and especially governments, can be trusted to determine truths of any kind…(More)”.
Report by the US Government Accountability Office: “Agencies can use more than 100 federal data sources—or a combination of them—to verify if recipients meet the eligibility criteria for federal programs throughout the award life cycle (which includes pre-award screening, post-award monitoring, and payment validation). As of September 2025, these included 28 data sources in the Do Not Pay working system (DNP) or designated for inclusion in DNP. However, weaknesses in data interoperability may hinder agencies’ ability to efficiently determine award and payment eligibility.
Data interoperability is the ability to share and disseminate standardized data in a way that is efficient, consistent, and accessible across different systems and users, for which high-quality data are essential. Without it, the risk of improper awards or payments increases, and the potential use of artificial intelligence and advanced analytics to assist agencies in making eligibility determinations is limited.
GAO found that, for more than 30 years, several laws and guidance have established general requirements related to data interoperability but have not established specific requirements for enforcing interoperability, such as for recipient eligibility data, throughout the federal government. Many of the data sources GAO identified, including those in DNP, were created to comply with legal requirements or to manage specific federal programs—not to support eligibility determinations for other agencies.
GAO also found a variety of obstacles and challenges that can affect the interoperability of the nine selected data sources that agencies may use for eligibility determinations (see figure).
Summary Comparison of Key Elements GAO Assessed to Eligibility Data Interoperability Needs and Observations
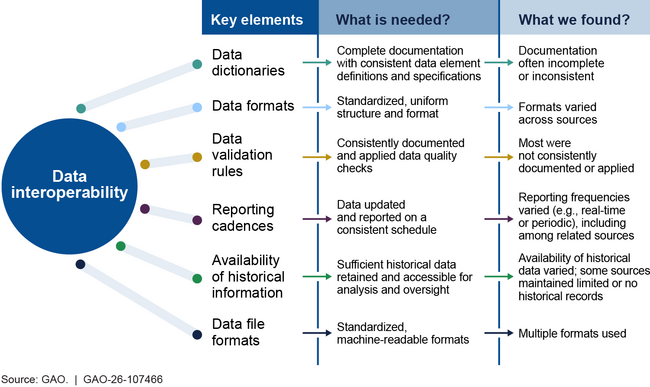
GAO also found that insufficient or improperly documented validation rules contributed to data quality issues. All nine selected data sources had data quality issues (e.g., missing, invalid, and duplicate data), and seven data sources had inconsistences between them, such as overlap in mutually exclusive data. These data quality issues undermine data reliability and interoperability for agencies seeking to make eligibility determinations…(More)”.
Editorial by Qi R. Wang: “Understanding how people move through cities is fundamental to epidemic preparedness, transportation planning, and climate policy. Yet for most of the world’s cities, particularly across the Global South, reliable mobility data simply does not exist. The traditional approach of conducting household travel surveys is expensive and slow; passively collected data from mobile phones, while transformative in data-rich countries, remains scarce where digital infrastructure is limited. This asymmetry creates a troubling paradox: the cities most in need of mobility-informed planning are precisely those with the least data to support it. For nearly eight decades, the gravity model has served as the default tool for filling this gap. The model estimates travel flows between locations as proportional to their populations and inversely proportional to the distance separating them. Its elegance lies in its simplicity: only population and distance are required. But that simplicity comes at a cost. The gravity model captures broad flow distributions while struggling to accurately estimate travel between specific pairs of neighborhoods. In recent years, deep learning approaches such as Deep Gravity have improved predictive accuracy by incorporating richer features of the built environment, but they introduce a new problem: overfitting to observed patterns and an inability to generalize to cities where no mobility observations exist. The field has been caught between interpretability and accuracy, between transferability and expressiveness (Fig. 1). In this issue of Nature Computational Science, Jinming Yang and colleagues introduce neuroGravity, a physics-informed deep learning framework that bridges this divide…(More)”.
Article by E. Glen Weyl and Raul Castro Fernandez: “The fight over the data that trains artificial intelligence has become one of the defining economic conflicts of the decade. Publishers, authors, and visual artists argue that their work was taken without permission or payment. AI companies counter that training on available data constitutes fair use and that even if a market in data were desirable, compensating millions of creators is technically impossible: the cost of figuring out what any given piece of data is worth, researchers have argued, would swallow most of the value that data creates in the first place.
Both sides stand to benefit from a fair solution to this impasse and the creation of a sustainable market for content. Any resolution must take both positions seriously while seeing past their literal inconsistency.
On the compensation issue, while content creators are justified in defending their livelihoods, creating a market that ensures fair compensation going forward will arguably serve them better than being paid out for past infractions as existing lawsuits have focused on. And for AI companies, a high-quality continued supply of data that the sector needs for future models, together with legal certainty, is worth more than whatever they save by not paying creators now. As to the technical feasibility, while the data-valuation techniques proposed in research so far are impractical, industry leaders have known since at least 2021—per documents from Anthropic’s Chris Olah and Dario Amodei that surfaced in legal discovery for one of the lawsuits against the company—that low-cost methods exist that could create a thriving market.
This article, which is based on our research, describes how a sustainable market for compensating content creators could work, and why it addresses an important part of the social and economic concerns about an AI future. The fact is that AI companies already produce the two data sets required for pricing content, as a matter of course, every time a model is trained.
The first is the data mixture. This is the proportions in which a model builder blends different kinds of data, which reveal the relative value of each source. For example, quality journalism may be weighed more highly than comments on social media, indicating that it is more valuable—and putting a specific number on how much more valuable. The second is scaling laws. These are the empirical regularities that AI researchers estimate to predict how model performance will respond to additional data and compute. Such estimates, together with economic theory, reveal what share of a model’s total value can be attributed to its training data. Together they show how to slice the pie and how big it is…(More)”.
Article by Logan Kugler: “…Traditional surveillance historically has been limited by the silo problem. Data was fragmented across different systems: license plate readers, facial recognition databases, and social media dragnets were separate tools requiring manual labor to connect. Multimodal frontier models change this dynamic by collapsing these independent signals into a single, unified layer of interpretation.
“Frontier models let governments turn fragmented feeds into a single intelligence engine that can search, summarize, and rank whole communities in real time,” said Sarah Hamid, director of Strategic Campaigns at the Electronic Frontier Foundation.
Hamid noted, however, that the technical bottleneck is no longer the collection of data, but the speed of analysis. In the past, searching across different datasets required a warrant or a specific lead. But now, a single model can answer natural-language queries like “find everyone who attended this protest and show me where else they appear in city-wide CCTV footage.” This cross-dataset fusion makes pervasive monitoring both cheap and nearly instantaneous.
Heidy Khlaaf, Chief AI Scientist at the AI Now Institute, said that the very data used to train these models—often scraped from the public Web or procured via data brokers—enables “dual-use” capabilities that facilitate state monitoring.
“Disparate datasets can be consolidated into a centralized model that can then be queried to produce determinations and inferences about populations with ease and scale,” Khlaaf explained. She warned these correlations are often prejudiced and can falsely implicate individuals based on flawed statistical patterns.
In other words, if AI labs allow governments latitude to use their models in this way, frontier AI could enable whole new levels of surveillance…(More)”.
Book by Jessica Pykett: “Data from facial emotion recognition, brain-computer interfaces, virtual reality, global emotion surveys and sentiment analysis offer an extraordinary new terrain for scientific exploration. Emotion sensing promises to decode and even to augment and control the very essence of human experience. But what if the science and technology of emotion measurement get emotions wrong? In Governing Global Emotions, Jessica Pykett argues that we must shift our thinking on digital emotional governance and calls for a radical reassessment of the fundamental claims of emotion science.
Pykett offers a groundbreaking account of how emotions are defined, used and governed through emerging digital technologies, arguing that emotions, senses and feelings have become a crucial new arena for political, economic and cultural struggles. She describes how technologies create emotional data, how smart cities use sensors to monitor residents’ feelings and how global economies measure happiness. Drawing on twenty years of interdisciplinary social science, Pykett documents how emotion science continues to delve deeper, as researchers look for evolutionary continuity, biological certainty and neuroscientific consensus. What she finds instead is a divided field vulnerable to significant criticism. Pykett concludes that standardised, universal and instrumentalised scientific accounts of emotions are machinic, and when divorced from context, they can never be global…(More)”.