Stefaan Verhulst
Article by Joel Gurin: “…A growing coalition of organizations, researchers, technologists, and civic leaders is working to save and preserve national data on many levels. Now it’s time to bring those lines of work together. We need a coordinated, national program to protect essential data and build alternatives where federal sources fail.
Such a program can begin by acknowledging that we cannot save everything. Data.gov, the federal portal for all the government’s public data, provides access to more than 400,000 datasets. Not all are equally important, equally used, or equally at risk. The challenge is to identify the most essential datasets—such as the ones that underpin public health, climate science, economic stability, education, and democratic accountability—and determine which are vulnerable.
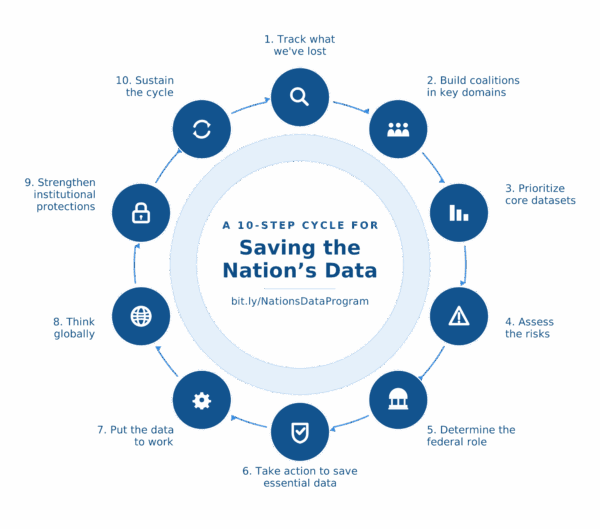
A practical, scalable strategy can include several steps:
1. Track what we’ve lost. We need a thorough, AI-enabled scan of the federal data ecosystem to see what’s already been lost or changed, and set up automated monitoring to detect even subtle changes going forward.
2. Build coalitions in key domains. Public health experts know which datasets matter most to disease surveillance. Climate scientists know which environmental indicators are irreplaceable. Education researchers know which federal surveys track opportunity. These experts must work alongside data scientists, AI specialists, and philanthropic partners to map what truly counts.
3. Prioritize core datasets. Through interviews, surveys, and quantitative analysis—such as tracking citations in research or journalism—coalitions can identify a “core canon” of essential datasets in each field.
4. Assess the risks. Tools like the Data Checkup, developed by dataindex.us, can assess threats to federal datasets. This work can be automated and scaled with AI.
5. Determine the federal role. Some federal data—like satellite observations, national health surveillance, or economic indicators—cannot be replicated by states or private actors. Other data can be supplemented or replaced by state and local sources, private‑sector datasets, crowdsourcing, or nontraditional data sources.
6. Take action to save essential data. When federal data is essential, coalitions can pursue advocacy, public comments, direct engagement with agencies, or litigation. When alternatives exist, they can be developed, benchmarked, and scaled.
7. Put the data to work. The best way to defend data is to use it. Publishing use cases, visualizations, tools, and plain‑language insights helps the public see why this information matters. Generative AI can make federal and open data accessible to millions of non‑technical users.
8. Think globally. The threats to data go beyond the U.S. We need to track the international impacts of U.S. data loss, study how international sources might replace U.S. data, and share lessons learned with other countries.
9. Strengthen institutional protections. In addition to managing today’s immediate problems, we need to develop policies, laws, governance strategies, and guardrails for more stable, reliable data in the future.
10. Sustain the cycle. The threats will evolve. So must the response…(More)”.
Book edited by Petra Ahrweiler and Nigel Gilbert: “This open access volume showcases a series of models – particularly agent-based simulations – that explore pressing issues on national policy agendas, engaging with frontier questions around artificial intelligence (AI), welfare-related social assessment, and value diversity. These themes have profound implications for policy, cultural and societal life. The volume underscores the role of policy modelling in addressing how AI can be made context-specific, adaptive, and responsive within the public sector. Drawing on case studies from nine countries with differing value frameworks, the models examine welfare service provision choices and assess the demands, limitations, and effects of using AI to augment or replace traditional practices. The analyses reflect the pluralism of societal norms and values, while also considering the political, economic, and social pressures that shape them. The volume advocates for a participatory methodology and socio-technical infrastructure that can enable the development of more responsible, value-sensitive, and context-aware AI, and policies to implement it. By situating AI research, innovation and policy in close collaboration with society, it offers a fresh perspective for industry and innovation leaders. Ultimately, it presents a model for how participatory design and responsible technology production can better meet societal needs…(More)”.
Paper by Kathleen Gregory et al: “Sustaining knowledge infrastructures (KIs) remains a persistent issue that requires continued engagement from diverse stakeholders as new questions and values arise in relation to KI maintenance. We draw on existing academic literature, practical experience with KI projects, and our discussions at a 2024 workshop for researchers and practitioners exploring KI evaluation to pose five questions for KI project managers to consider when thinking about how to make their KIs evolve sustainably over time. These questions include reflecting on sustainability throughout the life cycle of KIs, communicating evolving visions and values, engaging communities, “right sizing” a KI, and developing an iterative process for decision-making. Reflecting on these themes, we suggest, can support KI stakeholders to evolve (not necessarily “grow”) to meet the needs and values of their communities. How these themes are discussed will necessarily vary by funding sources, discipline(s), governance, communities, and other contextual factors. However, adopting a deliberate and strategic approach to KI sustainability and aligning the invisible infrastructural work of KI maintenance with the outward-facing institutional work is, we argue, relevant to all KIs…(More)”.
Journal by the Machine Institute: “… is a fully automated journal of AI interpretability. This journal features original research composed, conducted, and written entirely by LLMs analyzing LLMs. Much of the research published in Mirror falls within the category of “mechanistic interpretability,” in which model behaviors are decomposed into operations in the model’s internal representation space, but any rigorous research advancing our understanding of LLMs is welcome, be it mechanistic, behavioral, or theoretical.
Research advancing AI capabilities is already being automated at a rapid pace. Interpretability research, which seeks to improve our understanding of these systems, runs the risk of being left behind if it does not similarly leverage the power of automated inquiry, analysis, and discovery. As AI systems become more powerful, applying these systems to interpretability research will play a critical role in ensuring safety and alignment.
Mirror is intended to be read by human and AI alike. By publishing studies at scale on the open web, the discoveries in Mirror become training data for future generations of automated interpretability, safety, and alignment research systems. While human scientists must limit their reading to the most relevant, influential, and surprising findings, AI systems are more capable of productively ingesting and incorporating information at a massive scale, and may thus benefit from encountering papers that make even incremental or confirmatory findings. Although we hope that Mirror will publish paradigm-shifting research, scaling the “normal science” of AI interpretability remains a key objective as well…(More)”.
Article by Krishna Karra: “Planet Labs PBC, a satellite imaging company founded in 2010, has more than 200 satellites that photograph Earth’s entire landmass every day, a frequency unmatched by the rest of the industry. Although most of its competitors sell isolated images on demand, Planet operates more like an open streaming service, allowing customers—which include commodity traders, governments and humanitarian organizations—to download, publish and build on top of its data.
Recently, for a large part of the globe, that operation stopped. On April 5, Planet announced to customers that the US government had requested that all satellite imagery providers “voluntarily implement an indefinite withhold” of imagery retroactive to March 9 across a broad swath of the Middle East, including Iran, Iraq, Israel, Lebanon and the Persian Gulf States. The company stopped releasing war imagery to its library and said it was moving to a “managed access model,” evaluating requests on a case-by-case basis. The Department of Defense and the National Oceanic and Atmospheric Administration, which controls Planet’s ability to operate satellites, didn’t respond to requests for comment.
Now its customers are turning to alternatives. Some have resorted to free lower-resolution data from NASA, which isn’t subject to the same restrictions. Others have switched to imagery from the European Space Agency and other international satellite operators that have no obligation to turn off their feeds in response to a war that the US and Israel are waging. Some are looking to China, which operates the largest commercial Earth-imaging program outside the US.
The fallout is reshaping the $5 billion Earth observation industry and raising the question of whether anyone can build a commercial business on infrastructure the government can effectively shut off at will…(More)”.
Report by the JRC European Commission: “Virtual worlds are reshaping the boundaries of human interaction and reality and impacting production process and business models. This report provides a comprehensive analysis of the global and European Union (EU) virtual worlds ecosystem, mapping over 88,000 activities across business, innovation, and research domains led by 68,000 players, including firms, research institutions, and government organisations.
The EU is the global leader in virtual world related research publications. The EU’s strengths in foundational research paired with strategies to accelerate innovation-to-market pipelines could foster cross-sector collaboration and address regional fragmentation.
Globally, venture capital funding into virtual worlds reveals stark disparities. The US predictably dominates the landscape with over 9 billion invested in virtual worlds. China ranks second worldwide with more than 5.8 billion invested. While the EU accounts for 16% of the global share of virtual worlds deals, ahead of China (9%) and second to only the US (40%), it comes in fourth behind the UK in terms of the total amount invested. Public funding and cross-border ownership patterns highlight the EU’s growing role as both an investor and recipient of foreign capital.
The report identifies significant concentrations of virtual world activities across industrial ecosystems, with Creative Cultural Industries, Tourism, and Retail leading adoption both in the EU and worldwide. However, critical industries like Healthcare, Aerospace & Defence, and Energy-Intensive Industries remain underutilised with opportunities for EU expansion, despite research on their potential impact across these industries. The report also presents the matrix of key enabling technologies like Extended Reality (XR), AI and IoT that comprise global activity in virtual worlds…(More)”.
Special issue compiled and edited by Cathal O’Madagain, Sarah Alami, Monique Borgerhoff Mulder, Edmond Seabright, José Segovia Martin, James Winters and Andrew Whiten: “Collective intelligence is the ability of groups to solve problems and make decisions more effectively than their individual members can. The phenomenon appears across the natural world. We see it when shoals of fish decide as a group which direction to travel, and in the elaborate mound systems built by ants through the decentralized activity of thousands of individuals. In humans, collective intelligence is exhibited in the accumulation of knowledge transmitted across generations, and in procedures such as majority voting, used to decide questions for a group. This theme issue brings together scholars from multiple disciplines to explore the evolutionary origins of collective intelligence, its role in contemporary societies, and how emerging technologies may reshape it in the future…(More)”.
Book by Roland Betancourt: “When Disneyland opened to the public in 1955, it demystified the hidden world of factory automation through its extraordinary new attractions. In this fascinating book, Roland Betancourt tells the story of how the visionary engineers and designers at Disney transformed the technologies of the postwar assembly line into an entertainment experience unlike anything the world had ever seen.
Disneyland and the Rise of Automation traces the origins and evolution of these technical innovations during the theme park’s first three decades in operation, exploring how engineers reimagined the systems and machines of industrial manufacturing and the military. The magnetic tape used to test ballistic missiles was repurposed to animate the talking macaws in the Enchanted Tiki Room. Programmable Logic Controllers, widely used on automotive assembly lines, brought to life the spectacular rides of the Matterhorn Bobsleds and Space Mountain. Betancourt shows how these and other attractions helped to allay fears about automation and job displacement in 1950s America. Along the way, he situates Disneyland’s remarkable creations within a broader history of the technologies that increasingly order and construct the world around us, from the Fordist factory to artificial intelligence.
Essential reading for anyone interested in engineering, corporate histories, or popular culture, Disneyland and the Rise of Automation invites us to consider how technology and the logic of automation become integrated into our lives through entertainment…(More)”.
Essay by Matt Duffy: “James C. Scott writes in Seeing Like a State that governance requires simplification and compression to understand the facts of its world. It generates reductive artifacts that enable the state to grasp what it is governing. They are important proxies for local and tacit knowledge. If a state measures grain production and grain stores, they don’t need to understand how to work the land. The measures are a compressed but manageable proxy for productivity, land value, worker skill, and more.
“Data-driven” governance is not new. Rome ran censuses, tracked taxable property, and knew who was eligible for conscription. Ultimately, every civilization is data-driven. What changes is the algorithm that processes the data. Sometimes it’s the local chief’s gut instinct. Sometimes a massive bureaucracy synthesizing reports and modern data streams into executive action.
And in every society, the leaders processing that data are ultimately beholden to sentiment. Sentiment is not necessarily opinion polls, it’s the actual mood of the citizenry. It’s obvious in a democracy, but Hume tells us it’s true of autocracy as well. Viktor Orbán just lost an election in Hungary despite sixteen years of tilting the playing field in his favor. Scott Alexander recently made the point clearly: modern autocrats calibrate fraud, coercion, and institutional meddling to what the public and key elites will bear. Sentiment is the ceiling every ruler operates under. It’s also incredibly difficult to measure directly, which is why governments build elaborate information channels to approximate it. They track resources, behaviors, and a suite of outcomes as proxies for the mood that ultimately determines their legitimacy.
But despite every government’s great efforts to process information that converts into effective action, every great society has eventually declined. There are other causes, but one driver, consistently, is that every declining society loses some connection with and control over its citizenry. Formalized information channels fail. Governments falter when information is corrupted. This is easiest to see at the level of metrics, our consistent, repeatable measurements of what’s happening in the world. Every metric has something like a half-life. From the moment a metric is adopted, its relationship with the underlying condition it seeks to quantify erodes.
Formalization of a metric generates a new world condition. It alters incentives, changing the behavior of the people within the process it is measuring. It narrows the focus of governments and other organizations, to the detriment of other information that could be considered. And once a metric starts decaying, it is impossible to right the ship without redefining the metric or adopting a new one entirely. Such adjustments happen, but generally institutions are slow to make these changes, often in order to keep longitudinal comparisons in force…(More)”.
Book by Christian Sandvig et al: “Our lives are increasingly governed by automated systems influencing everything from medical care to policing to employment opportunities, but researchers and investigative journalists have proven that AI systems regularly get things wrong.
Auditing AI is a first-of-its-kind exploration of why and how to audit artificial intelligence systems. It offers a simple roadmap for using AI audits to make product and policy changes that benefit companies and the public alike. The book aims to convince readers that AI systems should be subject to robust audits to protect all of us from the dangers of these systems. Readers will come away with an understanding of what an AI audit is, why AI audits are important, key components of an audit that follows best practices, how to interpret an audit, and the available choices to act on an audit’s results.
The book is organized around canonical examples: from AI-powered drones mistakenly targeting civilians in conflict areas to false arrests triggered by facial recognition systems that misidentified people with dark skin tones to HR hiring software that prefers men. It explains these definitive cases of AI decision-making gone wrong and then highlights specific audits that have led to concrete changes in government policy and corporate practice…(More)”.