Stefaan Verhulst
Paper by Jonathan Proctor et al: “Satellite imagery and machine learning (SIML) are increasingly being combined to remotely measure social and environmental outcomes, yet use of this technology has been limited by insufficient understanding of its strengths and weaknesses. Here, we undertake the most extensive effort yet to characterize the potential and limits of using a SIML technology to measure ground conditions. We conduct 115 standardized large-scale experiments using a composite high-resolution optical image of Earth and a generalizable SIML technology to evaluate what can be accurately measured and where this technology struggles. We find that SIML alone predicts roughly half the variation in ground measurements on average, and that variables describing human society (e.g. female literacy, R²=0.55) are generally as easily measured as natural variables (e.g. bird diversity, R²=0.55). Patterns of performance across measured variable type, space, income and population density indicate that SIML can likely support many new applications and decision-making use cases, although within quantifiable limits…(More)”.
Paper by Richard Albert and Kevin Frazier: “Artificial Intelligence (AI) now has the capacity to write a constitution for any country in the world. But should it? The immediate reaction is likely emphatically no—and understandably so, given that there is no greater exercise of popular sovereignty than the act of constituting oneself under higher law legitimated by the consent of the governed. But constitution-making is not a single act at a single moment. It is a series of discrete steps demanding varying degrees of popular participation to produce a text that enjoys legitimacy both in perception and reality. Some of these steps could prudently integrate human-AI collaboration or autonomous AI assistance—or so we argue in this first Article to explain and evaluate how constitutional designers not only could, but also should, harness the extraordinary potential of AI. We combine our expertise as innovators in the use and design of AI with our direct involvement as advisors in constitution-making processes around the world to map the terrain of opportunities and hazards in the next iteration of the continuing fusion of technology with governance. We ask and answer the most important question now confronting constitutional designers: how to use AI in making and reforming constitutions?…(More)”
About: “MzansiXchange is a national data exchange initiative to create an integrated data ecosystem that supports effective planning, policymaking, reporting, and service delivery. At its core, it curates, integrates, and makes accessible a wide range of data for the public good.
The initiative addresses key challenges in South Africa’s data landscape, where information is often siloed, fragmented, not interoperable and difficult to access. MzansiXchange addresses these gaps by enabling secure, structured, and coordinated data sharing across government.
The MzansiXchange Pilot will test four key data-sharing themes through carefully selected use cases that demonstrate both immediate value to government operations and broader citizen impact. These use cases span different technical approaches and policy domains, providing comprehensive testing of the platform’s capabilities.
Real-time Data Exchange for Regulation, Compliance & Verification
Real-time data sharing enables immediate verification and compliance checking across government services. Pilot use cases include partnerships with the South African Social Security Agency, National Student Financial Aid Scheme, and Department of Home Affairs to streamline citizen services and reduce administrative burdens through instant data verification.
Bulk Data Exchange for Evidence-based Policy, Planning & Research
Large-scale de-identified data sharing supports informed policymaking and research initiatives. The National Treasury Secure Data Facility will serve as a key use case, enabling researchers and policymakers to access comprehensive datasets whilst maintaining strict security and privacy controls.
Data Exchange for Operational Analytics
Operational data sharing improves government efficiency and service delivery. Use cases include National Treasury Office of the Accountant General and the Office of the Chief Procurement Officer, focusing on cross-departmental analytics that enhance procurement processes and financial management.
Data Exchange for Open Access Data Products
Open data initiatives support effective resource allocation and service planning, promote transparency, and enable broader societal benefits. Pilot use cases include the Spatial Economic Activity Data – South Africa (SEAD-SA) platform and Statistics South Africa, making valuable datasets accessible to researchers, businesses, and civil society…(More)“.
Article by Brian Owens: “Scientific research offers many benefits to society, but how do you trace the impact of specific projects? It’s easy to track which papers result from a grant, but much harder to follow how research has broader societal impacts on policies, medicines or products.
“Those are much more exciting [impacts], and provide greater public good,” says Dashun Wang, director of the Center for Science of Science and Innovation at Northwestern University in Evanston, Illinois.
Wang and his colleagues built a tool called Funding the Frontier, which integrates data on research publications, patents, policy papers and clinical trials, and presents the information in a visually intuitive way. They also combined the tool with a machine-learning-driven predictive algorithm to forecast which studies and fields are likely to lead to the most societal benefits in the future — for example, which grants are most likely to result in a patent. They described the prototype in a paper published on the arXiv preprint server1.
Funding the Frontier includes a mind-boggling amount of data, drawn from four large data sets: the Dimensions, Altmetric and Overton databases, as well as the authors’ own SciSciNet data set. The total collection links 7 million research grants to 140 million scientific publications, 160 million patents, 10.9 million policy documents, 800,000 clinical trials and 5.8 million newsfeeds, all published between 2000 and 2021, with 1.8 billion citation linkages among them. The data can be displayed in several ways, showing the impacts that flowed from a particular study and tracing outcomes back to their sources and all the links between them.
Staša Milojević, who studies the science of science at Indiana University in Bloomington and was not involved in developing the tool, says that it could help to fill an important gap when it comes to translating studies of how science works into useful data. “Many studies in the area of ‘science of science’ have potential science-policy and funding implications,” she says. “However, their practical impact is often limited because they lack the tools that stakeholders can easily use to obtain useful insights.”
The size of the database, and its ability to link disparate strands together, is the biggest advantage, says Milojević. “The sheer amount of data, and the degree of data aggregation associated with FtF [Funding the Frontier], is impressive,” she says. “Even without its predictive aspect, having a tool that allows one to look up PIs [principal investigators] or grants from wide areas of science and evaluate them in terms of their various research metrics normalized for variations over fields and time is extremely useful.”..(More)”.
Report by Roshni Singh, Stefaan Verhulst and Cosima Lenz: “Women’s health has long been underexplored, fragmented, and too often reduced to a narrow set of issues like reproductive or maternal care. Yet women’s health spans a much broader spectrum—from chronic disease and mental health to the social and economic barriers that shape outcomes. Despite its vastness and centrality to human wellbeing, there has never been a comprehensive map that captures the full range of issues, actors, and gaps across the field.
Such a map matters. Without it, we risk overlooking key questions that have not yet been answered (orphan issues) or proritized or missing opportunities to align research and innovation. Topic mapping provides a systematic way to capture the complexity of women’s health, reveal its interconnectedness, and point to where innovation is most urgently needed. It also helps surface the different actors working across the ecosystem, enabling more strategic collaborations.
Today, we release the first version of the Women’s Health Topic Map.
The Topic Map is part of 100 Questions initiative under the Gates-funded R&I project, where CEPS and The GovLab have teamed up to ask: what are the most important questions that could truly advance women’s health innovation?
Before answering that, we first needed to map the field of women’s health itself. To build this foundation, we convened 77 “bilinguals” — experts working at the intersection of women’s health and research or data—who helped us create the first-ever Topic Map of women’s health.
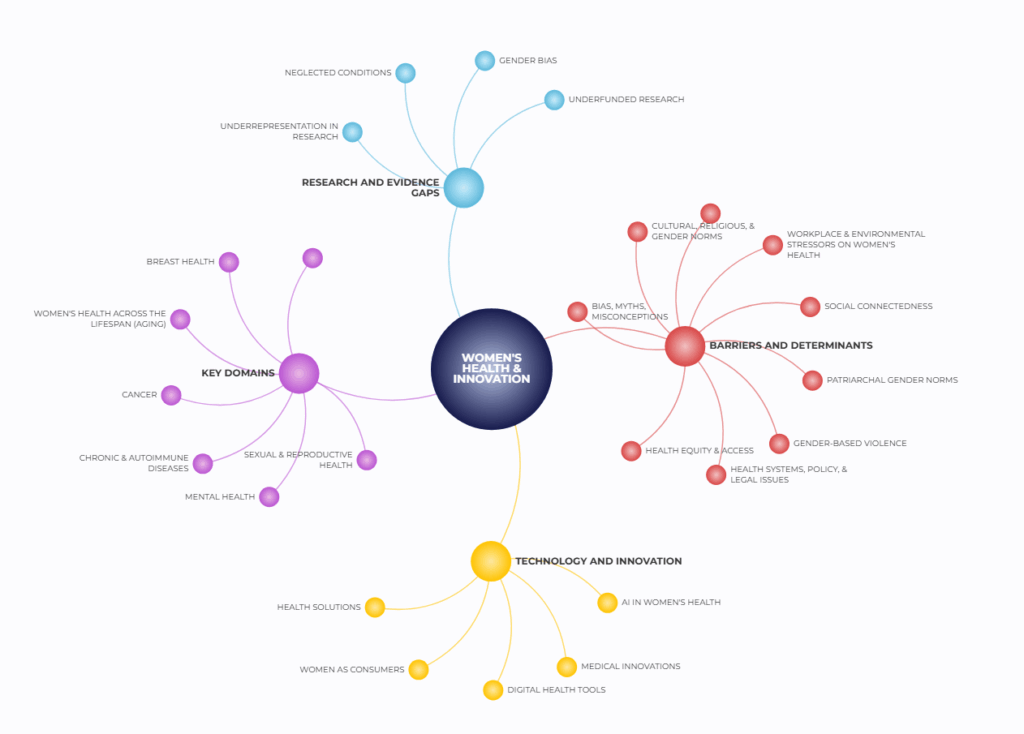
You can explore the Topic Map on our HELIX website, along with a narrative document that provides a deeper dive into the categories, branches, and subtopics…(More)”.
Article by Tim Higgins: “Winners may write history. But Elon Musk has often complained that losers author the Wikipedia entry.
Now conservatives are trying to change that, putting their focus on the unflashy website that gets more eyeballs than the largest U.S. media outlets, making it the latest institution to feel such pressure.
For those not chronically online, however, this past week’s tempest over Wikipedia can be jolting—especially given the site’s objective to remain trustworthy. For many, it is the modern-day encyclopedia—a site written and edited by volunteers that aims to offer, as Wikipedia co-founder Jimmy Wales once said, free access to “the sum of all human knowledge.”
To do that, Wikipedia adheres to three core policies that guide how entries are written. Each article must have a neutral point of view, be verifiable with information coming from published sources and no original research.
In effect, those final two points mean information comes summarized from known media sources. Those policies—and how they’re enforced—are what upset opponents such as billionaire Musk, White House AI czar David Sacks and others who don’t like its perceived slant.
Some call it “Wokepedia.” They talk as if its more than 64 million worldwide entries are fueled by mainstream media lies, pumping out propaganda that feeds online search results. For them, the threat is especially worrisome as Wikipedia is serving as a base layer of knowledge for AI chatbots.
“Wikipedia shapes America,” Tucker Carlson, the right-wing personality, said this past week on his podcast. “And because of its importance, it’s an emergency, in my opinion, that Wikipedia is completely dishonest and completely controlled on questions that matter.”
His guest was Wales’s former associate Larry Sanger, who helped create Wikipedia but left years ago. Since then, Sanger has often complained about the direction of Wikipedia, which, in theory, anyone can contribute to. The Wikimedia Foundation hosts the website, depending on donations to pay for its $207.5 million annual budget. That foundation doesn’t control the editorial processes. Volunteers, through consensus, do…(More)”.
Article and Interview by Nathan Gardels: “When he was president of France in the 1960s, Charles de Gaulle intuitively understood that his nation could not be a sovereign player on the world stage during the Cold War between the United States and the Soviet Union unless it possessed its own nuclear weapons.
What was true for France then is true today for the European Union, as China and America dominate AI. The continent cannot achieve strategic autonomy as a sovereign entity unless it joins the club with its own significant capacity.
American Big Tech already dominates Europe, which has struggled to start up its own industry, with the exceptions of the French company, Mistral AI, and the critical Dutch manufacturer of high-end chips, ASML. In the U.S., OpenAI, Microsoft, Google, DeepMind, Amazon, Meta and Nvidia are spending hundreds of billions on AI research and infrastructure. Driven by state investment, China is spending comparative billions and has shown its ability to compete globally through open-source AI models such as DeepSeek.
AI differs from nuclear weapons because it is a foundational technology that will transform all aspects of life. As such, it is not merely a technological achievement, but a cultural project. It is here that Europe’s precautionary temperament clashes with the accelerationist fever of Silicon Valley.
Does this place Europe at a competitive disadvantage that will fatally impede its advance in AI? Or will Europe’s deliberative vigilance save humanity from handing over the keys of the kingdom to intelligent machines?
The core conflict between America and its European geopolitical allies is their differing approaches to AI; the former seeks to “build first, regulate later,” while the latter seeks to “regulate first, build later.”
To explore this divergence within the West, Noema invited two top thinkers on technology to debate the topic. Benjamin Bratton directs the Antikythera project on planetary-scale computation. Francesca Bria is Barcelona’s former chief technology and innovation officer. Their exchange is more polemical than Noema’s tone usually accommodates, an expression of the passions aroused when the stakes are so high….(More)”.
Report by the National Academies of Science, Engineering, and Medicine’s Roundtable on Science and Technology: “As the world faces unprecedented sustainability challenges, including biodiversity loss, resource depletion, and ecosystem degradation, there is a critical need for innovative, scalable, and data-informed solutions. Artificial intelligence (AI) has emerged as a transformative technology with the potential to accelerate progress toward sustainability goals by enhancing efficiency, optimizing resource use, improving environmental monitoring, and enabling data-informed decision-making.
To examine AI opportunities, challenges, and pathways through a lens of sustainability…the workshop examined how AI can be leveraged to maximize benefits … at the intersection of nature, people, and this critical technology…(More)”.
Index by Wikirate: “… exists to cultivate open company data, but open alone is not enough. The data needs to be understandable, actionable and placed in the hands of decision-makers, who can then push for the changes people and the planet need.
Benchmarks are an essential tool for making company data understandable and actionable. They not only tap into corporate competitiveness by shining a light on how companies perform comparatively but also provide an opportunity to set the bar and communicate good practices.
Wikirate has therefore translated its mission into metrics and developed the Reporting Integrity Index that outlines what corporate disclosures should entail to ensure ESG data is open and reliable…(More)”
Book by Bruce Schneier and Nathan E. Sanders: “AI is changing democracy. We still get to decide how.
AI’s impact on democracy will go far beyond headline-grabbing political deepfakes and automated misinformation. Everywhere it will be used, it will create risks and opportunities to shake up long-standing power structures.
In this highly readable and advisedly optimistic book, Rewiring Democracy, security technologist Bruce Schneier and data scientist Nathan Sanders cut through the AI hype and examine the myriad ways that AI is transforming every aspect of democracy—for both good and ill.
The authors describe how the sophistication of AI will fulfill demands from lawmakers for more complex legislation, reducing deference to the executive branch and altering the balance of power between lawmakers and administrators. They show how the scale and scope of AI is enhancing civil servants’ ability to shape private-sector behavior, automating either the enforcement or neglect of industry regulations. They also explain how both lawyers and judges will leverage the speed of AI, upending how we think about law enforcement, litigation, and dispute resolution.
Whether these outcomes enhance or degrade democracy depends on how we shape the development and use of AI technologies. Powerful players in private industry and public life are already using AI to increase their influence, and AIs built by corporations don’t deliver the fairness and trust required by democratic governance. But, steered in the right direction, AI’s broad capabilities can augment democratic processes and help citizens build consensus, express their voice, and shake up long-standing power structures.
Democracy is facing new challenges worldwide, and AI has become a part of that. It can inform, empower, and engage citizens. It can also disinform, disempower, and disengage them. The choice is up to us. Schneier and Sanders blaze the path forward, showing us how we can use AI to make democracy stronger and more participatory…(More)”.