O’Leary, Daniel E. at Intelligent Systems, IEEE : “The goals of big data and privacy are fundamentally opposed to each other. Big data and knowledge discovery are aimed reducing information asymmetries between organizations and the data sources, whereas privacy is aimed at maintaining information asymmetries of data sources. A number of different definitions of privacy are used to investigate some of the tensions between different characteristics of big data and potential privacy concerns. Specifically, the author examines the consequences of unevenness in big data, digital data going from local controlled settings to uncontrolled global settings, privacy effects of reputation monitoring systems, and inferring knowledge from social media. In addition, the author briefly analyzes two other emerging sources of big data: police cameras and stingray for location information….(More)”
Data enriched research, data enhanced impact: the importance of UK data infrastructure.
Matthew Woollard at LSE Impact Blog: “…Data made available for reuse, such as those in the UK Data Service collection have huge potential. They can unlock new discoveries in research, provide evidence for policy decisions and help promote core data skills in the next generation of researchers. By being part of a single infrastructure, data owners and data creators can work together with the UK Data Service – rather than duplicating efforts – to engage with the people who can drive the impact of their research further to provide real benefit to society. As a service we are also identifying new ways to understand and promote our impact, and our Impact Fellow and Director of Impact and Communications, Victoria Moody, is focusing on raising the visibility of the UK Data Service holdings and developing and promoting the use and impact of the data and resources in policy-relevant research, especially to new audiences such as policymakers, government sectors, charities, the private sector and the media…..
We are improving how we demonstrate the impact of both the Service and the data which we hold, by focusing on generating more and more authentic user corroboration. Our emphasis is on drawing together evidence about the reach and significance of the impact of our data and resources, and of the Service as a whole through our infrastructure and expertise. Headline impact indicators through which we will better understand our impact cover a range of areas (outlined above) where the Service brings efficiency to data access and re-use, benefit to its users and a financial and social return on investment.
We are working to understand more about how Service data contributes to impact by tracking the use of Service data in a range of initiatives focused on developing impact from research and by developing our insight into usage of our data by our users. Data in the collection have featured in a range of impact case studies in the Research Excellence Framework 2014. We are also developing a focus on understanding the specific beneficial effect, rather than simply that data were used in an output, that is – as it appears in policy, debate or the evidential process (although important). Early thoughts in developing this process are where (ideally) cited data can be tracked through the specific beneficial outcome and on to an evidenced effect, corroborated by the end user.
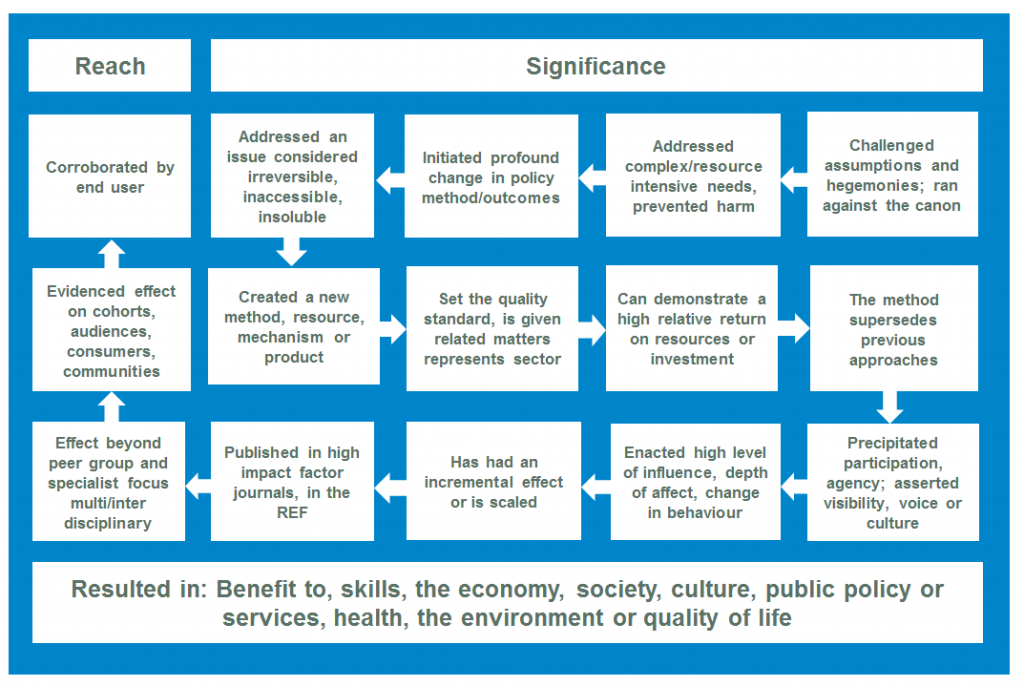
Our impact case studies demonstrate how the data have supported research which has led to policy change in a range of areas including; the development of mathematical models for Practice based Commissioning budgets for adult mental health in the UK and informing public policy on obesity; both using the Health Survey for England. Service data have also informed the development of impact around understanding public attitudes towards the police and other legal institutions using the Crime Survey for England and Wales and research to support the development of the national minimum wage using the Labour Force Survey. The cutting-edge new Demos Integration Hub maps the changing face of Britain’s diversity, revealing a mixed picture in the integration and upward mobility of ethnic minority communities and uses 2011 Census aggregate data (England and Wales) and Understanding Society….(More)”
Analyzing 1.1 Billion NYC Taxi and Uber Trips
Todd W. Schneider: “The New York City Taxi & Limousine Commission has released a staggeringly detailed historical dataset covering over 1.1 billion individual taxi trips in the city from January 2009 through June 2015. Taken as a whole, the detailed trip-level data is more than just a vast list of taxi pickup and drop off coordinates: it’s a story of New York. How bad is the rush hour traffic from Midtown to JFK? Where does the Bridge and Tunnel crowd hang out on Saturday nights? What time do investment bankers get to work? How has Uber changed the landscape for taxis? And could Bruce Willis and Samuel L. Jackson have made it from 72nd and Broadway to Wall Street in less than 30 minutes? The dataset addresses all of these questions and many more.
I mapped the coordinates of every trip to local census tracts and neighborhoods, then set about in an attempt to extract stories and meaning from the data. This post covers a lot, but for those who want to pursue more analysis on their own: everything in this post—the data, software, and code—is freely available. Full instructions to download and analyze the data for yourself are available on GitHub.
Table of Contents
Open government data: Out of the box
The Economist on “The open-data revolution has not lived up to expectations. But it is only getting started…
The app that helped save Mr Rich’s leg is one of many that incorporate government data—in this case, supplied by four health agencies. Six years ago America became the first country to make all data collected by its government “open by default”, except for personal information and that related to national security. Almost 200,000 datasets from 170 outfits have been posted on the data.gov website. Nearly 70 other countries have also made their data available: mostly rich, well-governed ones, but also a few that are not, such as India (see chart). The Open Knowledge Foundation, a London-based group, reckons that over 1m datasets have been published on open-data portals using its CKAN software, developed in 2010.
Jakarta’s Participatory Budget
Ramda Yanurzha in GovInsider: “…This is a map of Musrenbang 2014 in Jakarta. Red is a no-go, green means the proposal is approved.
To give you a brief background, musrenbang is Indonesia’s flavor of participatory, bottom-up budgeting. The idea is that people can propose any development for their neighbourhood through a multi-stage budgeting process, thus actively participating in shaping the final budget for the city level, which will then determine the allocation for each city at the provincial level, and so on.
The catch is, I’m confident enough to say that not many people (especially in big cities) are actually aware of this process. While civic activists tirelessly lament that the process itself is neither inclusive nor transparent, I’m leaning towards a simpler explanation that most people simply couldn’t connect the dots.
People know that the public works agency fixed that 3-foot pothole last week. But it’s less clear how they can determine who is responsible for fixing a new streetlight in that dark alley and where the money comes from. Someone might have complain to the neighbourhood leader (Pak RT) and somehow the message gets through, but it’s very hard to trace how it got through. Just keep complaining to the black box until you don’t have to. There are very few people (mainly researchers) who get to see the whole picture.
This has now changed because the brand-new Jakarta open data portal provides musrenbang data from 2009. Who proposed what to whom, for how much, where it should be implemented (geotagged!), down to kelurahan/village level, and whether the proposal is accepted into the final city budget. For someone who advocates for better availability of open data in Indonesia and is eager to practice my data wrangling skill, it’s a goldmine.
Diving In

The data is also, as expected, incredibly messy. While surprisingly most of the projects proposed are geotagged, there are a lot of formatting inconsistencies that makes the clean up stage painful. Some of them are minor (m? meter? meter2? m2? meter persegi?) while others are perplexing (latitude: -6,547,843,512,000 – yes, that’s a value of more than a billion). Annoyingly, hundreds of proposals point to the center of the National Monument so it’s not exactly a representative dataset.
For fellow data wranglers, pull requests to improve the data are gladly welcome over here. Ibam generously wrote an RT extractor to yield further location data, and I’m looking into OpenStreetMap RW boundary data to create a reverse geocoder for the points.
A couple hours of scrubbing in OpenRefine yields me a dataset that is clean enough for me to generate the CartoDB map I embedded at the beginning of this piece. More precisely, it is a map of geotagged projects where each point is colored depending on whether it’s rejected or accepted.
Numbers and Patterns
40,511 proposals, some of them merged into broader ones, which gives us a grand total of 26,364 projects valued at over IDR 3,852,162,060,205, just over $250 million at the current exchange rate. This amount represents over 5% of Jakarta’s annual budget for 2015, with projects ranging from a IDR 27,500 (~$2) trash bin (that doesn’t sound right, does it?) in Sumur Batu to IDR 54 billion, 1.5 kilometer drainage improvement in Koja….(More)”
RethinkCityHall.org
Press Release (Boston): “Mayor Martin J. Walsh today announced the launch of RethinkCityHall.org, a website designed to encourage civic participation in the City Hall campus plan study, a one-year comprehensive planning process that will serve as a roadmap for the operation and design improvements to City Hall and the plaza.
This announcement is one of three interrelated efforts that the City is pursuing to reinvigorate and bring new life to both City Hall and City Hall Plaza. As part of the Campus Plan Request for Qualifications (RFQ) that was released on June 8, 2015, the City has selected Utile, a local architecture and planning firm, to partner with the city to lead the campus plan study. Utile is teamed with Grimshaw Architects and Reed Hilderbrand for the design phases of the effort.
“I am excited to have Utile on board as we work to identify ways to activate our civic spaces,” said Mayor Walsh. “As we progress in the planning process, it is important to take inventory of all of our assets to be able to identify opportunities for improvement. This study will help us develop a thoughtful and forward-thinking plan to reimagine City Hall and the plaza as thriving, healthy and innovative civic spaces.”
“We are energized by Mayor Walsh’s challenge and are excited to work with the various constituencies to develop an innovative plan,” said Tim Love, a principal at Utile. “Thinking about the functional, programmatic and experiential aspects of both the building and plaza provides the opportunity to fundamentally rethink City Hall.”
Both the City and Utile are committed to an open and interactive process that engages members of the public, community groups, professional organizations, and as part of that effort the website will include information about stakeholder meetings and public forums. Additionally, the website will be updated on an ongoing basis with the research, analysis, concepts and design scenarios generated by the consultant team….(More)”
Will Open Data Policies Contribute to Solving Development Challenges?
Fabrizio Scrollini at IODC: “As the international open data charter gains momentum in the context of the wider development agenda related to the sustainable development goals set by the United Nations, a pertinent question to ask is: will open data policies contribute to solve development challenges? In this post I try to answer this question grounded in recent Latin American experience to contribute to a global debate.
Latin America has been exploring open data since 2013, when the first open data unconference (Abrelatam)and conference took place in Montevideo. In September 2015 in Santiago de Chile a vibrant community of activists, public servants, and entrepreneurs gathered in the third edition of Abrelatam and Condatos. It is now a more mature community. The days where it was sufficient to just open a few datasets and set up a portal are now gone. The focus of this meeting was on collaboration and use of data to address several social challenges.
Take for instance the health sector. Transparency in this sector is key to deliver better development goals. One of the panels at Condatos showed three different ways to use data to promote transparency and citizen empowerment in this sector. A tu servicio, a joint venture of DATA and the Uruguayan Ministry of Health helped to standardize and open public datasets that allowed around 30,000 users to improve the way they choose health providers. Government-civil society collaboration was crucial in this process in terms pooling resources and skills. The first prototype was only possible because some data was already open.
This contrasts with Cuidados Intensivos, a Peruvian endeavour aiming to provide key information about the health sector. Peruvian activists had to fill right to information requests, transform, and standardize data to eventually release it. Both experiences demanded a great deal of technical, policy, and communication craft. And both show the attitudes the public sector can take: either engaging or at the very best ignoring the potential of open data.
In the same sector look at a recent study dealing with Dengue and open data developed by our research initiative. If international organizations and countries were persuaded to adopt common standards for Dengue outbreaks, they could be potentially predicted if the right public data is available and standardized. Open data in this sector not only delivers accountability but also efficiency and foresight to allocate scarce resources.
Latin American countries – gathered in the open data group of the Red Gealc – acknowledge the increasing public value of open data. This group engaged constructively in Condatos with the principles enshrined in the charter and will foster the formalization of open data policies in the region. A data revolution won’t yield results if data is closed. When you open data you allow for several initiatives to emerge and show its value.
Once a certain level of maturity is reached in a particular sector, more than data is needed. Standards are crucial to ensure comparability and ease the collection, processing, and use of open government data. To foster and engage with open data users is also needed, as several strategies deployed by some Latin American cities show.
Coming back to our question: will open data policies contribute to solve development challenges? The Latin American experience shows evidence that it will….(More)”
Batea: a Wikipedia hack for medical students
Tom Sullivan at HealthCareIT: “Medical students use Wikipedia in great numbers, but what if it were a more trusted source of information?
That’s the idea behind Batea, a piece of software that essentially collects data from clinical reference URLs medical students visit, then aggregates that information to share with WikiProject Medicine, such that relevant medical editors can glean insights about how best to enhance Wikipedia’s medical content.
Batea takes its name from the Spanish name for gold pan, according to Fred Trotter, a data journalist at DocGraph.
“It’s a data mining project,” Trotter explained, “so we wanted a short term that positively referenced mining.”
DocGraph built Batea with support from the Robert Wood Johnson Foundation and, prior to releasing it on Tuesday, operated beta testing pilots of the browser extension at the University of California, San Francisco and the University of Texas, Houston.
UCSF, for instance, has what Trotter described as “a unique program where medical students edit Wikipedia for credit. They helped us tremendously in testing the alpha versions of the software.”
Wikipedia houses some 25,000 medical articles that receive more than 200 million views each month, according to the DocGraph announcement, while 8,000 pharmacology articles are read more than 40 million times a month.
DocGraph is encouraging medical students around the country to download the Batea extension – and anonymously donate their clinical-related browsing history. Should Batea gain critical mass, the potential exists for it to substantively enhance Wikipedia….(More)”
Fudging Nudging: Why ‘Libertarian Paternalism’ is the Contradiction It Claims It’s Not
Paper by Heidi M. Hurd: “In this piece I argue that so-called “libertarian paternalism” is as self-contradictory as it sounds. The theory of libertarian paternalism originally advanced by Richard Thaler and Cass Sunstein, and given further defense by Sunstein alone, is itself just a sexy ad campaign designed to nudge gullible readers into thinking that there is no conflict between libertarianism and welfare utilitarianism. But no one should lose sight of the fact that welfare utilitarianism just is welfare utilitarianism only if it sacrifices individual liberty whenever it is at odds with maximizing societal welfare. And thus no one who believes that people have rights to craft their own lives through the exercise of their own choices ought to be duped into thinking that just because paternalistic nudges are cleverly manipulative and often invisible, rather than overtly coercive, standard welfare utilitarianism can lay claim to being libertarian.
After outlining four distinct strains of libertarian theory and sketching their mutual incompatibility with so-called “libertarian paternalism,” I go on to demonstrate at some length how the two most prevalent strains — namely, opportunity set libertarianism and motivational libertarianism — make paternalistically-motivated nudges abuses of state power. As I argue, opportunity set libertarians should recognize nudges for what they are — namely, state incursions into the sphere of liberty in which individual choice is a matter of moral right, the boundaries of which are rightly defined, in part, by permissions to do actions that do not maximize welfare. And motivational libertarians should similarly recognize nudges for what they are — namely, illicitly motivated forms of legislative intervention that insult autonomy no less than do flat bans that leave citizens with no choice but to substitute the state’s agenda for their own. As I conclude, whatever its name, a political theory that recommends to state officials the use of “nudges” as means of ensuring that citizens’ advance the state’s understanding of their own best interests is no more compatible with libertarianism than is a theory that recommends more coercive means of paternalism….(More)”
Of Remixology: Ethics and Aesthetics after Remix
New book by David J. Gunkel : “Remix—or the practice of recombining preexisting content—has proliferated across media both digital and analog. Fans celebrate it as a revolutionary new creative practice; critics characterize it as a lazy and cheap (and often illegal) recycling of other people’s work. In Of Remixology, David Gunkel argues that to understand remix, we need to change the terms of the debate. The two sides of the remix controversy, Gunkel contends, share certain underlying values—originality, innovation, artistic integrity. And each side seeks to protect these values from the threat that is represented by the other. In reevaluating these shared philosophical assumptions, Gunkel not only provides a new way to understand remix, he also offers an innovative theory of moral and aesthetic value for the twenty-first century.
In a section called “Premix,” Gunkel examines the terminology of remix (including “collage,” “sample,” “bootleg,” and “mashup”) and its material preconditions, the technology of recording. In “Remix,” he takes on the distinction between original and copy; makes a case for repetition; and considers the question of authorship in a world of seemingly endless recompiled and repurposed content. Finally, in “Postmix,” Gunkel outlines a new theory of moral and aesthetic value that can accommodate remix and its cultural significance, remixing—or reconfiguring and recombining—traditional philosophical approaches in the process….(More)”