
By: Roshni Singh, Hannah Chafetz, and Stefaan G. Verhulst
The questions that society asks can transform public policy making, mobilize resources, and shape public discourse, yet decision makers around the world frequently focus on developing solutions rather than identifying the questions that need to be addressed to develop those solutions.
This blog provides a range of resources on the potential of questions for society. It includes readings on new approaches to formulating questions, how questions benefit public policy making and democracy, the importance of increasing the capacity for questioning at the individual level, and the role of questions in the age of AI and prompt engineering.
These readings underscore the need for a new science of questions – a new discipline solely focused on integrating participatory approaches for identifying, prioritizing, and addressing questions for society. This emerging discipline not only fosters creativity and critical thinking within societies but also empowers individuals and communities to engage actively in the questioning process, thereby promoting a more inclusive and equitable approach to addressing today’s societal challenges.
A few key takeaways from these readings:
- Incorporating participatory approaches in questioning processes: Several of the readings discuss the value of including participatory approaches in questioning as a means to incorporate diverse perspectives, identify where there knowledge gaps, and ensure the questions prioritized reflect current needs. In particular, the readings emphasize the role of open innovation and co-creation principles, workshops, surveys, as ways to make the questioning process more collaborative.
- Advancing individuals’ questioning capability: Teaching individuals to ask their own questions fosters agency and is essential for effective democratic participation. The readings recommend cultivating this skill from early education through adulthood to empower individuals to engage actively in decision-making processes.
- Improving questioning processes for responsible AI use: In the era of AI and prompt engineering, how questions are framed is key for deriving meaningful responses to AI queries. More focus on participatory question formulation in the context of AI can help foster more inclusive and responsible data governance.
***
In “Crowdsourcing Research Questions in Science,” the authors examine how involving the general public in formulating research questions can enhance scientific inquiry. They analyze two crowdsourcing projects in the medical sciences and find that crowd-generated questions often restate problems but provide valuable cross-disciplinary insights. Although these questions typically rank lower in novelty and scientific impact compared to professional questions, they match the practical impact of professional research. The authors argue that crowdsourcing can improve research by offering diverse perspectives. They emphasize the importance of using effective selection methods to identify and prioritize the most valuable contributions from the crowd, ensuring that the highest quality questions are highlighted and addressed.
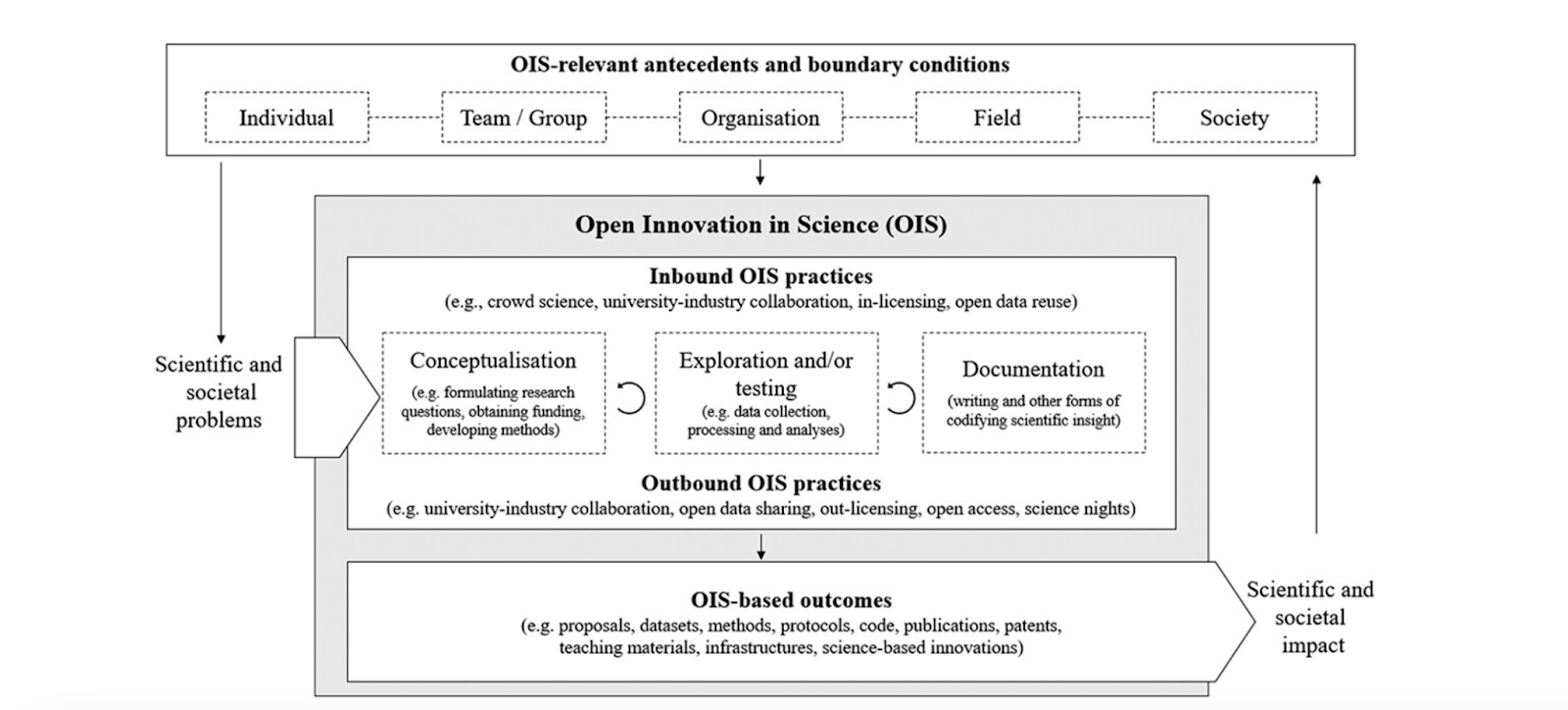
This journal article emphasizes the growing importance of openness and collaboration in scientific research. The authors identify the lack of a unified understanding of these practices due to differences in disciplinary approaches and propose an Open Innovation in Science (OIS) Research Framework (co-developed with 47 scholars) to bridge these knowledge gaps and synthesize information across fields. The authors argue that integrating Open Science and Open Innovation concepts can enhance researchers’ and practitioners’ understanding of how these practices influence the generation and dissemination of scientific insights and innovation. The article highlights the need for interdisciplinary collaboration to address the complexities of societal, technical, and environmental challenges and provides a foundation for future research, policy discussions, and practical guidance in promoting open and collaborative scientific practices.
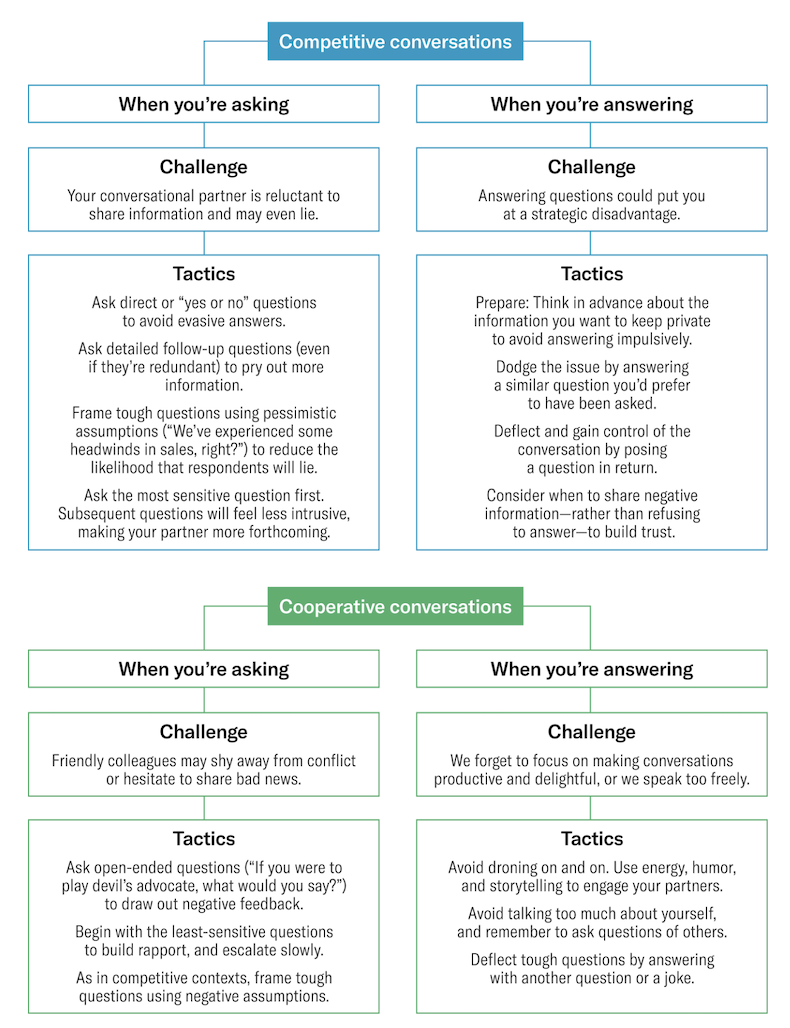
In “The Surprising Power of Questions,” published in Harvard Business Review, Alison Wood Brooks and Leslie K. John highlight how asking questions drives learning, innovation, and relationship building within organizations. They argue that many executives focus on answers but underestimate how well-crafted questions can enhance communication, build trust, and uncover risks. Drawing from behavioral science, the authors show how the type, tone, and sequence of questions influence the effectiveness of conversations. By refining their questioning skills, individuals can boost emotional intelligence, foster deeper connections, and unlock valuable insights that benefit both themselves and their organizations.
Kellner, Paul. “Choosing Policy-Relevant Research Questions.” Good Questions Review, May 21, 2024.
In “Choosing Policy-Relevant Research Questions,” Paul Kellner explains how social scientists can craft research questions that better inform policy decisions. He highlights the ongoing issue of social sciences not significantly impacting policy, as noted by experts like William Julius Wilson and Christopher Whitty. The article suggests methods for engaging policymakers in the research question formulation process, such as user engagement, co creation, surveys, voting, and consensus-building workshops. Kellner provides examples where policymakers directly participated in the research, resulting in more practical and relevant outcomes. He concludes that improving coordination between researchers and policymakers can enhance the policy impact of social science research.
In this Op-Ed, Andrew P. Minigan emphasizes the critical role of curiosity and question formulation in education. He argues that alongside the “4 Cs” (creativity, critical thinking, communication, and collaboration), there should be a fifth C: curiosity. Asking questions enables students to identify knowledge gaps, think critically and creatively, and engage with peers. Research links curiosity to improved memory, academic achievement, and creativity. Despite these benefits, traditional teaching models often overlook curiosity. Minigan suggests teaching students to formulate questions to boost their curiosity and support educational goals. He concludes that nurturing curiosity is essential for developing innovative thinkers who can explore new, complex questions.
Rothstein, Dan. “Questions, Agency and Democracy.” Medium (blog), February 25, 2017.
In this blog, Dan Rothstein highlights the importance of fostering “agency,” which is the ability of individuals to think and act independently, as a cornerstone of democracy. Rothstein and his colleague Luz Santana have spent over two decades at The Right Question Institute teaching people how to ask their own questions to enhance their participation in decision-making. They discovered that the inability to ask questions hinders involvement in decisions that impact individuals. Rothstein argues that learning to formulate questions is essential for developing agency and effective democratic participation. This skill should be taught from early education through adulthood. Despite its importance, many students do not learn this in college, so educators must focus on teaching question formulation at all levels. Rothstein concludes that empowering individuals to ask questions is vital for a strong democracy and should be a continuous effort across society.
In the chapter “From a Policy Problem to a Research Question: Getting It Right Together” from the Science for Policy Handbook, Marta Sienkiewicz emphasizes the importance of co-creation between researchers and policymakers to determine relevant research questions. She highlights the need for this approach due to the separation between research and policy cultures, and the differing natures of scientific (tame) and policy (wicked) problems. Sienkiewicz outlines a skills framework and provides examples from the Joint Research Centre (JRC), such as Knowledge Centres, staff exchanges, and collaboration facilitators, to foster interaction and collaboration. Engaging policymakers in the research question development process leads to more practical and relevant outcomes, builds trust, and strengthens relationships. This collaborative approach ensures that research is aligned with policy needs, increases the chances of evidence being used effectively in decision-making, and ultimately enhances the impact of scientific research on policy.
In “Methods for Collaboratively Identifying Research Priorities and Emerging Issues in Science and Policy,” the authors, William J. Sutherland et al., emphasize the importance of bridging the gap between scientific research and policy needs through collaborative approaches. They outline a structured, inclusive methodology that involves researchers, policymakers, and practitioners to jointly identify priority research questions. The approach includes gathering input from diverse stakeholders, iterative voting processes, and structured workshops to refine and prioritize questions, ensuring that the resulting research addresses critical societal and environmental challenges. These methods foster greater collaboration and ensure that scientific research is aligned with the practical needs of policymakers, thereby enhancing the relevance and impact of the research on policy decisions. This approach has been successfully applied in multiple fields, including conservation and agriculture, demonstrating its versatility in addressing both emerging issues and long-term policy priorities.
In this article co-authored with Anil Ananthaswamy, , Stefaan Verhulst emphasizes the crucial role of framing questions correctly, particularly in the era of AI and data. They highlight how ChatGPT’s success underscores the power of well-formulated questions and their impact on deriving meaningful answers. Verhulst and Ananthaswamy argue that society’s focus on answers has overshadowed the importance of questioning, which shapes scientific inquiry, public policy, and data utilization. They call for a new science of questions that integrates diverse fields and promotes critical thinking, data literacy, and inclusive questioning to address biases and improve decision-making. This interdisciplinary effort aims to shift the emphasis from merely seeking answers to understanding the context and purpose behind the questions.

In this chapter published in “Global Digital Data Governance: Polycentric Perspectives”, Stefaan Verhulst explores the crucial role of formulating questions in ensuring responsible data usage. Verhulst argues that, in our data-driven society, responsibly handling data is key to maximizing public good and minimizing risks. He proposes a polycentric approach where the right questions are co-defined to enhance the social impact of data science. Drawing from both conceptual and practical knowledge, including his experience with The 100 Questions Initiative, Verhulst emphasizes that a participatory methodology in question formulation can democratize data use, ensuring data minimization, proportionality, participation, and accountability. By shifting from a supply-driven to a demand-driven approach, Verhulst envisions a new “science of questions” that complements data science, fostering a more inclusive and responsible data governance framework.
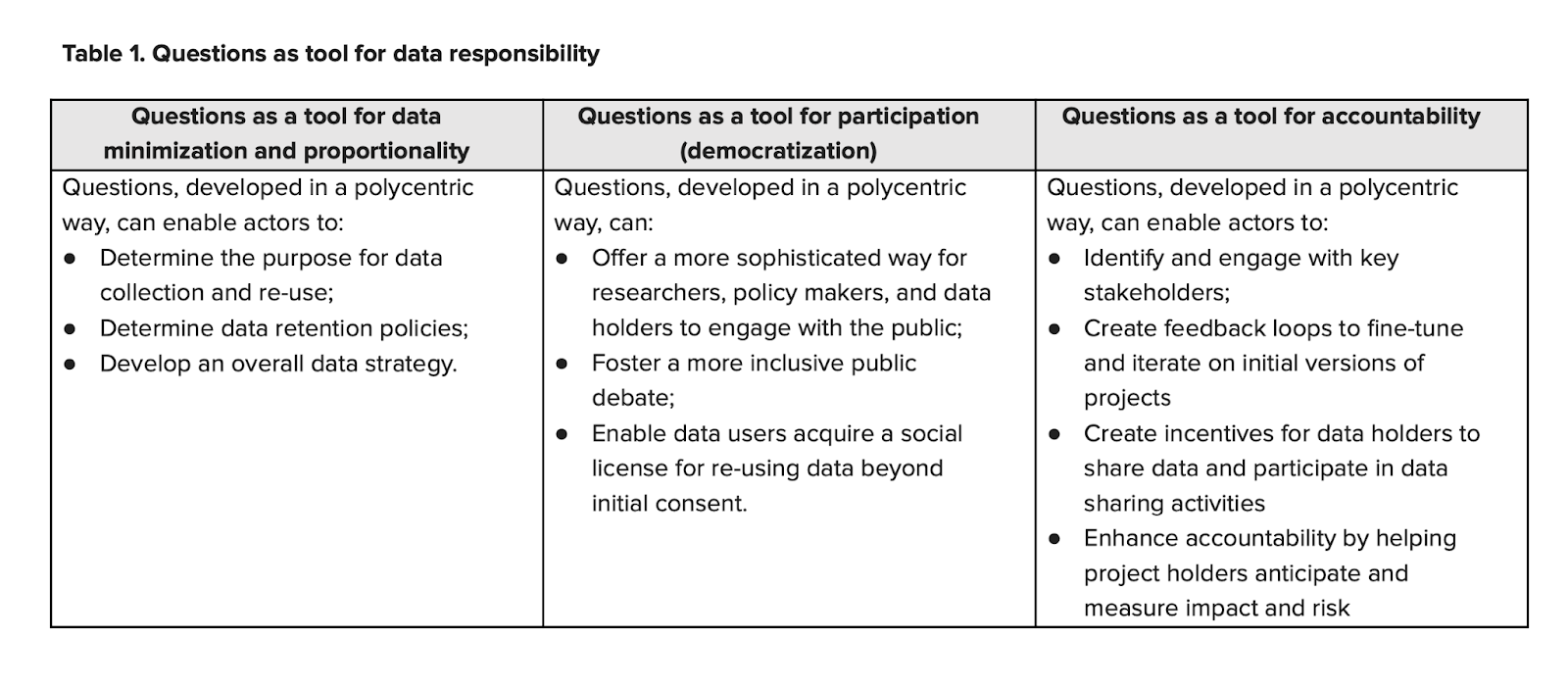
Table 1 from Verhulst, Stefaan G. “Questions as a Device for Data Responsibility: Toward a New Science of Questions to Steer and Complement the Use of Data Science for the Public Good in a Polycentric Way,” outlines how questions serve as tools for data responsibility across three principles: minimization and proportionality, participation, and accountability. Questions help determine data collection purposes, develop retention policies, foster inclusive debates, secure social licenses for data re-use, identify stakeholders, create feedback loops, and enhance accountability by anticipating risks.
***
As we navigate the complexities of our rapidly changing world, the importance of asking the right questions cannot be overstated. We invite researchers, educators, policymakers, and curious minds alike to delve deeper into new approaches for questioning. By fostering an environment that values and prioritizes well-crafted questions, we can drive innovation, enhance education, improve public policy, and harness the potential of AI and data science. In the coming months, The GovLab, with the support of the Henry Luce Foundation, will be exploring these topics further through a series of roundtable discussions. Are you working on participatory approaches to questioning and are interested in getting involved? Email Stefaan G. Verhulst, Co-Founder and Chief R&D at The GovLab, at sverhulst@thegovlab.org.