Paper by Toby Shevlane et al: “Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through “dangerous capability evaluations”) and the propensity of models to apply their capabilities for harm (through “alignment evaluations”). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
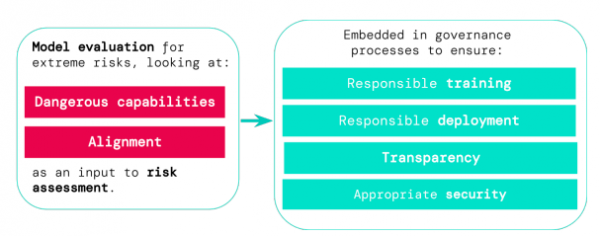
Figure 1 | The theory of change for model evaluations for extreme risk. Evaluations for dangerous capabilities and alignment inform risk assessments, and are in turn embedded into important governance processes…(More)”.