Stefaan Verhulst
About: “An open-source toolkit for comparing and conflating Points of Interest (POIs) across major geospatial datasets.
OpenPOIs downloads current US-wide POI snapshots from multiple publicly available sources — currently OpenStreetMap and Overture Maps — and conflates them into a single unified dataset. The web map lets you explore each source side by side. Each POI in the conflated dataset is given a confidence score, which is the probability that the POI currently exists based on available data from both sources…(More)”.
Article by Tiago C. Peixoto: “…For over a decade, those focused on the demand side of open data paid, and rightly so, lots of attention on who would use the data, and how. AI solves the demand-side problem. But the moment you build the agent and point it at real government data, you discover a supply-side problem that was always there but never fully exposed. The techno-mediator bottleneck was masking it. When only a handful of skilled developers and data journalists could query government APIs, the partial nature of the data caused limited damage. The few who did the query had enough domain expertise to cross-reference. AI removes that containment. If millions of citizens can now query budget data through AI agents, and the data systematically undercounts by a factor of five, the result is not accountability at scale. It is misinformation at scale, laundered through the authority of clean data and confident AI responses.
To be clear: the open data movement never assumed the data was already “out there.” The whole point was to advocate for its release. The problem came after. When governments did start publishing, the shortage of people who could query and assess the data meant that its quality went, in many cases, largely unexamined. The mediation failure that reduced the usefulness of open data for accountability purposes also made it less useful for quality control. If almost nobody can check whether a budget API returns 20% or 100% of the real figures, governments face no cost for publishing incomplete extracts. The very conditions that weakened the demand side gave the supply side room to underdeliver, and to receive credit for it. Rather than a communication trick, openwashing was an architectural possibility created by the absence of capable users. And it was sustained by an institutional environment in which there was no requirement that a public-facing API reconcile with the government’s full internal financial records, no audit of coverage, and no penalty for publishing a clean but partial extract…(More)”.
Article by Matthew Gault: “Researchers working with data from the Internet Archive have discovered that a third of websites created since 2022 are AI-generated. The team of researchers—which includes people from Stanford, the Imperial College London, and the Internet Archive—published their findings online in a paper titled “The Impact of AI-Generated Text on the Internet.” The research also found that all this AI-generated text is making the web more cheery and less verbose. Inspired by the Dead Internet Theory—the idea that much of the internet is now just bots talking back and forth—the team set out to find out how ChatGPT and its competitors had reshaped the internet since 2022. “The proliferation of AI-generated and AI-assisted text on the internet is feared to contribute to a degradation in semantic and stylistic diversity, factual accuracy, and other negative developments,” the researchers write in the paper. “We find that by mid-2025, roughly 35% of newly published websites were classified as AI-generated or AI-assisted, up from zero before ChatGPT’s launch in late 2022…(More)”.
Article by Northwestern Innovation Institute: “Federal agencies such as the NIH and the National Science Foundation help determine which scientific ideas receive public support, which researchers are able to pursue ambitious work and which fields gain momentum. Because those decisions shape the future direction of discovery, even subtle shifts in how proposals are written, evaluated and selected can have lasting effects across the research ecosystem.
Yet while large language models such as ChatGPT have rapidly entered classrooms, offices and laboratories, far less attention has been paid to how they may be influencing the grant process itself. Proposal writing is often one of the most time-consuming parts of academic life, and AI tools can reduce that burden by helping draft language, summarize prior work and improve organization.
To examine how those tools may already be affecting funding outcomes, researchers at Northwestern Innovation Institute analyzed confidential proposal submissions from two major U.S. research universities together with the full population of publicly released NIH and NSF awards from 2021 through 2025. The combined dataset —made possible in part through Bridge, a collaborative initiative at the Innovation Institute that integrates research, funding and innovation data across partner institutions — offered a rare window into both funded and unfunded proposals at the earliest stage of the research pipeline.
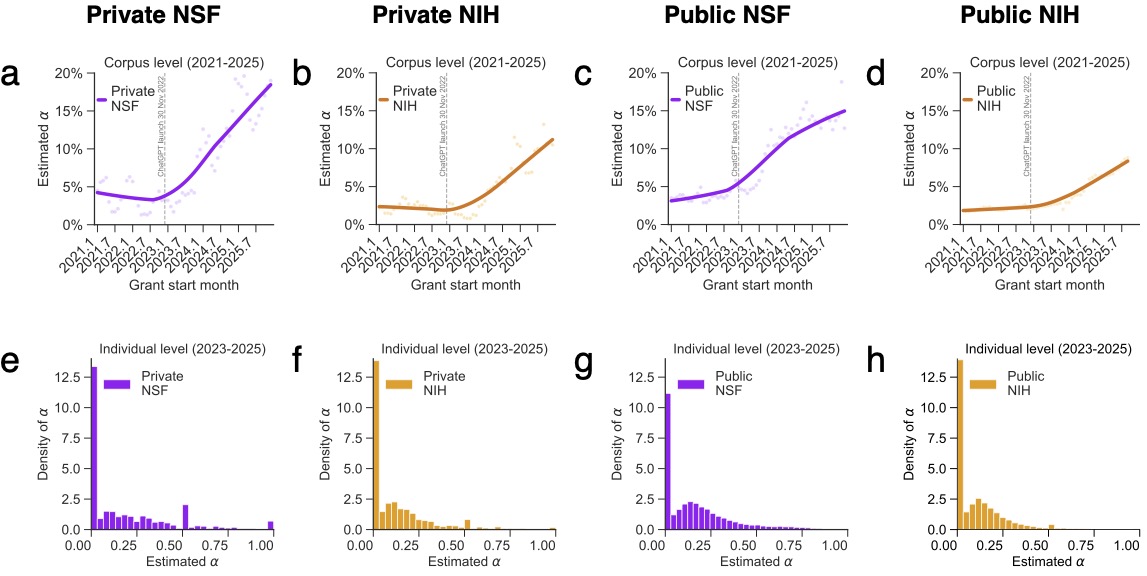
Signs of AI-assisted writing rose sharply beginning in 2023, shortly after generative AI tools became widely available. At NIH, proposals with higher levels of AI involvement were more likely to receive funding and went onto produce more publications. But that productivity gain came with an important qualifier: the additional output was concentrated in ordinary papers rather than the most highly cited work. AI-assisted grants produced more research, but not necessarily more breakthroughs.
Across both agencies, proposals with stronger AI signals also tended to be less distinctive from recently funded work. Crucially, the study found this reflects genuine shifts in what researchers are proposing, not merely how they are writing — when the researchers held scientific content constant and appliedAI rewriting to existing abstracts, the semantic position of those proposals barely changed. The convergence is happening at the level of ideas.
These findings directly address both open questions. The productivity gains — more publications, but not more breakthroughs, and only at NIH, suggest that AI is primarily lowering the cost of communication rather than accelerating scientific execution. And by observing confidential, unfunded proposals alongside funded awards, the study shows that AI’s influence is already operating upstream, reshaping how ideas are articulated and positioned before they ever reach publication…(More)”.
Paper by Kimitaka Asatani et al: “Intergovernmental organizations (IGOs) attempt to shape global policy through scientific guidelines and assessments. While they rely on external scientists to bridge research and IGO advisory processes, the structural pathways connecting science to IGO documents remain unexamined. By linking 230,737 scientific papers referenced in IGO documents (2015–2023) to their authors and coauthorship networks across 23 research fields, we identified a small cohort of “Highly IGO-Cited Scientists” (HIC-Sci)—typically comprising 0.7% to 4.4% of authors whose work accounts for 30% of IGO-cited papers. This structural concentration is associated with relational and cognitive patterns: dense transnational collaboration networks, overlapping memberships on advisory bodies such as the Intergovernmental Panel on Climate Change, rapid uptake in IGO documents, and standardized policy-oriented vocabularies. Geographically, HIC-Sci networks follow a core–periphery structure centered on Western Europe. Established fields, such as climate modeling, show stronger concentration, whereas emerging domains such as data science & AI show more distributed citation patterns. Major IGOs frequently cocite the same HIC-Sci papers, compounding this concentration through synchronized diffusion across IGOs. This concentration persists despite IGOs’ efforts to broaden participation and diversify their evidence base. While IGOs have developed criteria for selecting knowledge in advance, our framework provides a basis for subsequent assessment of how IGOs’ efforts to influence policy rely on a concentrated set of HIC-Sci…(More)”.
Article by James W Kelly: “Medical information of 500,000 participants of one of the UK’s landmark scientific programmes, UK Biobank, were offered for sale online in China, the government has confirmed.
Technology minister Ian Murray said information of all members of the database was found listed for sale on the website Alibaba.
Murray told MPs the charity which runs UK Biobank had told the government about the breach on Monday. He said the information did not include names, addresses, contact details or telephone numbers.
However he said it could include gender, age, month and year of birth, socioeconomic status, lifestyle habits, and measures from biological samples.
The Biobank is a collection of health data offered by volunteers which has been used to help improvements in detection and treatment of dementia, some cancers and Parkinson’s.
It has collected intimate details – including whole body scans, DNA sequences and their medical records – from hundreds of thousands of volunteers for over two decades. The project has led to more than 18,000 scientific publications.
Participants were aged from 40 to 69 when they were recruited between 2006 and 2010.
UK Biobank said it was investigating the incident and thanked the UK and Chinese governments, as well as Alibaba, for support and cooperation…(More)”.
Paper by Juan Ortiz-Freuler and Manuel Castells: “Control over digital interfaces has become a significant aspect of geopolitical struggles. This article advances an analytical framework illuminating how global communication power manifests across three key interfaces: search engines, social media, and AI agents. We articulate the evolution of these interfaces from corporate innovation to an aspect of contested transnational control, and conceptualize how corporate multinationals like Google, Facebook, TikTok, and DeepSeek leverage interface design to consolidate authority while state interventions challenge their market control. Governments seek to instrumentalize or challenge corporate interfaces to advance national goals, while firms strategically align with or resist state agendas to secure market access. The framework articulates how these forces reconfigure relations between information, people, and machines, with implications for the internet’s next phase…(More)”.
Article by Manon Revel & Théophile Pénigaud: “…unpacks the design choices behind longstanding and newly proposed computational frameworks aimed at finding common grounds across collective preferences and examines their potential future impacts, both technically and normatively. It begins by situating AI-assisted preference elicitation within the historical role of opinion polls, emphasizing that preferences are shaped by the decision-making context and are seldom objectively captured. With that caveat in mind, we explore the extent to which AI-based democratic innovations might serve as discovery tools which support reasonable representations of a collective will, sense-making, and agreement-seeking. At the same time, we caution against dangerously misguided uses, such as enabling binding decisions, fostering gradual disempowerment or post-rationalizing political outcomes…(More)”.
Paper by Jakob Ohme and LK Seiling: “The EU’s Digital Services Act (DSA) establishes, for the first time, a legal right for independent researchers to access platform data in the public interest. Once designated as Very Large Online Platforms or Search Engines (VLOPSEs), services reaching 45 million EU users must provide data access to support research on “systemic risks.” Article 40 creates two pathways: Article 40(12) enables access to publicly available data beyond voluntary platform tools, while Article 40(4) allows vetted researchers to request non-public data – such as exposure logs, moderation records, and recommendation metrics – through national Digital Services Coordinators rather than platforms. Both routes are purpose-limited to studying systemic risks and, for Article 40(4), mitigation measures. Yet the DSA’s broad, non-exhaustive definition of systemic risk – covering illegal content, fundamental rights, civic discourse, public health, and user well-being – opens a wide research space spanning misinformation flows, political networks, algorithmic amplification, and platform governance, among others. Early implementation reveals challenges, including uneven compliance, uncertain technical standards, funding constraints, and limits to data sharing for replication. Nonetheless, the DSA marks a turning point: platform research is no longer dependent on corporate discretion but grounded in public-interest regulation. Researchers now play a central role in shaping evidence-based oversight of digital platforms in Europe…(More)”.
Article by Alex Daniels: “Could the soul-sucking process of applying for philanthropic grants be on the way out? That is one of the goals of a new $8 million effort supported by the MacArthur Foundation.
The project, dubbed the Philanthropy Data Commons, is an attempt to bring a huge reservoir of foundation and charity information into a single database. Grant seekers and grant makers can drill into the data to find partners that share the same goals, among the vast universe of tax-exempt organizations.
“It should take nonprofits less time to apply for grants and allow them more time to spend on their missions,” said Elizabeth Kane, co-director of the Commons. “By the same token, many funders struggle to find and support organizations that are aligned with their goals. It could make the grant application process more efficient for both sides.”
Currently, the publicly available data from Internal Revenue Service filings that nonprofits can scour for grant information is limited. It only provides basic personnel and financial information and lacks detail about what work funders want to support and how well nonprofits have performed.
If enough organizations provide more granular information to the Data Commons — things like due diligence reports on potential grantees, project timelines, and impact data — the database and the applications created to use it could play matchmaker. Grantees and grant makers could be connected through a largely automated process. Grantees would be able to search grant makers and vice versa. Applications for many grants could be completed with a minimum of keystrokes. For instance, if a grantee located several foundations that matched some basic criteria, it could auto-populate fields in an application using its stored data and send it off to all of the grant makers at the same time…(More)”.