Glyn Moody at ArsTechnica: “In 1836, Anthony Panizzi, who later became principal librarian of the British Museum, gave evidence before a parliamentary select committee. At that time, he was only first assistant librarian, but even then he had an ambitious vision for what would one day became the British Library. He told the committee:
I want a poor student to have the same means of indulging his learned curiosity, of following his rational pursuits, of consulting the same authorities, of fathoming the most intricate inquiry as the richest man in the kingdom, as far as books go, and I contend that the government is bound to give him the most liberal and unlimited assistance in this respect.
He went some way to achieving that goal of providing general access to human knowledge. In 1856, after 20 years of labour as Keeper of Printed Books, he had helped boost the British Museum’s collection to over half a million books, making it the largest library in the world at the time. But there was a serious problem: to enjoy the benefits of those volumes, visitors needed to go to the British Museum in London.
Imagine, for a moment, if it were possible to provide access not just to those books, but to all knowledge for everyone, everywhere—the ultimate realisation of Panizzi’s dream. In fact, we don’t have to imagine: it is possible today, thanks to the combined technologies of digital texts and the Internet. The former means that we can make as many copies of a work as we want, for vanishingly small cost; the latter provides a way to provide those copies to anyone with an Internet connection. The global rise of low-cost smartphones means that group will soon include even the poorest members of society in every country.
That is to say, we have the technical means to share all knowledge, and yet we are nowhere near providing everyone with the ability to indulge their learned curiosity as Panizzi wanted it.
What’s stopping us? That’s the central question that the “open access” movement has been asking, and trying to answer, for the last two decades. Although tremendous progress has been made, with more knowledge freely available now than ever before, there are signs that open access is at a critical point in its development, which could determine whether it will ever succeed in realising Panizzi’s plan.
Table of Contents
- The arcana of academic publishing
- What about us?
- In the beginning was arXiv
- Scholarly skywriting
- Opening up the Americas
- Public Library of Science
- Open access is born
- CERN’s SCOAP
- PLoS ONE
- Gold open access
- Hybrid problems
- Green open access
- The empire strikes back
- Diamond open access
- From Aaron Swartz…
- …to Sci-Hub“
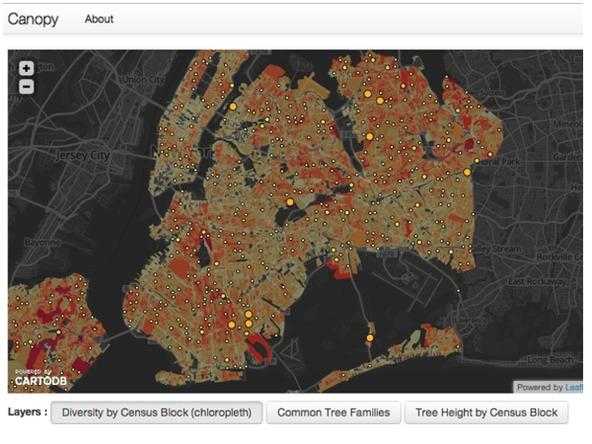 Visualization of NYC Parks’ Department data showing tree density in New York City.
Visualization of NYC Parks’ Department data showing tree density in New York City.