Paper by Amandeep S. Gill & Stefan Germann: “AI governance is like one of those mythical creatures that everyone speaks of but which no one has seen. Sometimes, it is reduced to a list of shared principles such as transparency, non-discrimination, and sustainability; at other times, it is conflated with specific mechanisms for certification of algorithmic solutions or ways to protect the privacy of personal data. We suggest a conceptual and normative approach to AI governance in the context of a global digital public goods ecosystem to enable progress on the UN Sustainable Development Goals (SDGs). Conceptually, we propose rooting this approach in the human capability concept—what people are able to do and to be, and in a layered governance framework connecting the local to the global. Normatively, we suggest the following six irreducibles: a. human rights first; b. multi-stakeholder smart regulation; c. privacy and protection of personal data; d. a holistic approach to data use captured by the 3Ms—misuse of data, missed use of data and missing data; e. global collaboration (‘digital cooperation’); f. basing governance more in practice, in particular, thinking separately and together about data and algorithms. Throughout the article, we use examples from the health domain particularly in the current context of the Covid-19 pandemic. We conclude by arguing that taking a distributed but coordinated global digital commons approach to the governance of AI is the best guarantee of citizen-centered and societally beneficial use of digital technologies for the SDGs…(More)”.
Understanding Algorithmic Discrimination in Health Economics Through the Lens of Measurement Errors
Paper by Anirban Basu, Noah Hammarlund, Sara Khor & Aasthaa Bansal: “There is growing concern that the increasing use of machine learning and artificial intelligence-based systems may exacerbate health disparities through discrimination. We provide a hierarchical definition of discrimination consisting of algorithmic discrimination arising from predictive scores used for allocating resources and human discrimination arising from allocating resources by human decision-makers conditional on these predictive scores. We then offer an overarching statistical framework of algorithmic discrimination through the lens of measurement errors, which is familiar to the health economics audience. Specifically, we show that algorithmic discrimination exists when measurement errors exist in either the outcome or the predictors, and there is endogenous selection for participation in the observed data. The absence of any of these phenomena would eliminate algorithmic discrimination. We show that although equalized odds constraints can be employed as bias-mitigating strategies, such constraints may increase algorithmic discrimination when there is measurement error in the dependent variable….(More)”.
Can data die?
Article by Jennifer Ding: “…To me, the crux of the Lenna story is how little power we have over our data and how it is used and abused. This threat seems disproportionately higher for women who are often overrepresented in internet content, but underrepresented in internet company leadership and decision making. Given this reality, engineering and product decisions will continue to consciously (and unconsciously) exclude our needs and concerns.
While social norms are changing towards non-consensual data collection and data exploitation, digital norms seem to be moving in the opposite direction. Advancements in machine learning algorithms and data storage capabilities are only making data misuse easier. Whether the outcome is revenge porn or targeted ads, surveillance or discriminatory AI, if we want a world where our data can retire when it’s outlived its time, or when it’s directly harming our lives, we must create the tools and policies that empower data subjects to have a say in what happens to their data… including allowing their data to die…(More)”
The Age of A.I. And Our Human Future
Book by Henry A Kissinger, Eric Schmidt, and Daniel Huttenlocher: “Artificial Intelligence (AI) is transforming human society fundamentally and profoundly. Not since the Enlightenment and the Age of Reason have we changed how we approach knowledge, politics, economics, even warfare. Three of our most accomplished and deep thinkers come together to explore what it means for us all.
An A.I. that learned to play chess discovered moves that no human champion would have conceived of. Driverless cars edge forward at red lights, just like impatient humans, and so far, nobody can explain why it happens. Artificial intelligence is being put to use in sports, medicine, education, and even (frighteningly) how we wage war.
In this book, three of our most accomplished and deep thinkers come together to explore how A.I. could affect our relationship with knowledge, impact our worldviews, and change society and politics as profoundly as the ideas of the Enlightenment…(More)”.
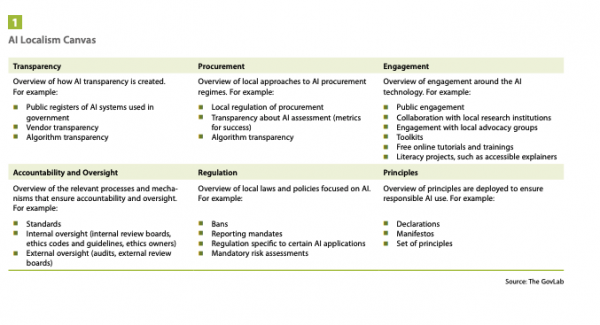
The AI Localism Canvas: A Framework to Assess the Emergence of Governance of AI within Cities
Paper by Verhulst, Stefaan, Andrew Young, and Mona Sloane: “AI Localism focuses on governance innovation surrounding the use of AI on a local level….As it stands, however, the decision-making processes involved in the local governance of AI systems are not very systematized or well understood. Scholars and local decision-makers lack an adequate evidence base and analytical framework to help guide their thinking. In order to address this shortcoming, we have developed the below “AI Localism Canvas” which can help identify, categorize and assess the different areas of AI Localism specific to a city or region, in the process aid decision-makers in weighing risk and opportunity. The overall goal of the canvas is to rapidly assess and iterate local governance innovation about AI to ensure citizens’ interests and rights are respected….(More)”.
Beyond pilots: sustainable implementation of AI in public services
Report by AI Watch: “Artificial Intelligence (AI) is a peculiar case of General Purpose Technology that differs from other examples in history because it embeds specific uncertainties or ambiguous character that may lead to a number of risks when used to support transformative solutions in the public sector. AI has extremely powerful and, in many cases, disruptive effects on the internal management, decision-making and service provision processes of public administration….
This document first introduces the concept of AI appropriation in government, seen as a sequence of two logically distinct phases, respectively named adoption and implementation of related technologies in public services and processes. Then, it analyses the situation of AI governance in the US and China and contrasts it to an emerging, truly European model, rooted in a systemic vision and with an emphasis on the revitalised role of the member states in the EU integration process, Next, it points out some critical challenges to AI implementation in the EU public sector, including: the generation of a critical mass of public investments, the availability of widely shared and suitable datasets, the improvement of AI literacy and skills in the involved staff, and the threats associated with the legitimacy of decisions taken by AI algorithms alone. Finally, it draws a set of common actions for EU decision-makers willing to undertake the systemic approach to AI governance through a more advanced equilibrium between AI promotion and regulation.
The three main recommendations of this work include a more robust integration of AI with data policies, facing the issue of so-called “explainability of AI” (XAI), and broadening the current perspectives of both Pre-Commercial Procurement (PCP) and Public Procurement of Innovation (PPI) at the service of smart AI purchasing by the EU public administration. These recommendations will represent the baseline for a generic implementation roadmap for enhancing the use and impact of AI in the European public sector….(More)”.
The Uselessness of Useful Knowledge
Maggie Chiang for Quanta Magazine: “Is artificial intelligence the new alchemy? That is, are the powerful algorithms that control so much of our lives — from internet searches to social media feeds — the modern equivalent of turning lead into gold? Moreover: Would that be such a bad thing?
According to the prominent AI researcher Ali Rahimi and others, today’s fashionable neural networks and deep learning techniques are based on a collection of tricks, topped with a good dash of optimism, rather than systematic analysis. Modern engineers, the thinking goes, assemble their codes with the same wishful thinking and misunderstanding that the ancient alchemists had when mixing their magic potions.
It’s true that we have little fundamental understanding of the inner workings of self-learning algorithms, or of the limits of their applications. These new forms of AI are very different from traditional computer codes that can be understood line by line. Instead, they operate within a black box, seemingly unknowable to humans and even to the machines themselves.
This discussion within the AI community has consequences for all the sciences. With deep learning impacting so many branches of current research — from drug discovery to the design of smart materials to the analysis of particle collisions — science itself may be at risk of being swallowed by a conceptual black box. It would be hard to have a computer program teach chemistry or physics classes. By deferring so much to machines, are we discarding the scientific method that has proved so successful, and reverting to the dark practices of alchemy?
Not so fast, says Yann LeCun, co-recipient of the 2018 Turing Award for his pioneering work on neural networks. He argues that the current state of AI research is nothing new in the history of science. It is just a necessary adolescent phase that many fields have experienced, characterized by trial and error, confusion, overconfidence and a lack of overall understanding. We have nothing to fear and much to gain from embracing this approach. It’s simply that we’re more familiar with its opposite.
After all, it’s easy to imagine knowledge flowing downstream, from the source of an abstract idea, through the twists and turns of experimentation, to a broad delta of practical applications. This is the famous “usefulness of useless knowledge,” advanced by Abraham Flexner in his seminal 1939 essay (itself a play on the very American concept of “useful knowledge” that emerged during the Enlightenment).
A canonical illustration of this flow is Albert Einstein’s general theory of relativity. It all began with the fundamental idea that the laws of physics should hold for all observers, independent of their movements. He then translated this concept into the mathematical language of curved space-time and applied it to the force of gravity and the evolution of the cosmos. Without Einstein’s theory, the GPS in our smartphones would drift off course by about 7 miles a day…(More)”.
Strengthening international cooperation on AI
Report by Cameron F. Kerry, Joshua P. Meltzer, Andrea Renda, Alex Engler, and Rosanna Fanni: “Since 2017, when Canada became the first country to adopt a national AI strategy, at least 60 countries have adopted some form of policy for artificial intelligence (AI). The prospect of an estimated boost of 16 percent, or US$13 trillion, to global output by 2030 has led to an unprecedented race to promote AI uptake across industry, consumer markets, and government services. Global corporate investment in AI has reportedly reached US$60 billion in 2020 and is projected to more than double by 2025.
At the same time, the work on developing global standards for AI has led to significant developments in various international bodies. These encompass both technical aspects of AI (in standards development organizations (SDOs) such as the International Organization for Standardization (ISO), the International Electrotechnical Commission (IEC), and the Institute of Electrical and Electronics Engineers (IEEE) among others) and the ethical and policy dimensions of responsible AI. In addition, in 2018 the G-7 agreed to establish the Global Partnership on AI, a multistakeholder initiative working on projects to explore regulatory issues and opportunities for AI development. The Organization for Economic Cooperation and Development (OECD) launched the AI Policy Observatory to support and inform AI policy development. Several other international organizations have become active in developing proposed frameworks for responsible AI development.
In addition, there has been a proliferation of declarations and frameworks from public and private organizations aimed at guiding the development of responsible AI. While many of these focus on general principles, the past two years have seen efforts to put principles into operation through fully-fledged policy frameworks. Canada’s directive on the use of AI in government, Singapore’s Model AI Governance Framework, Japan’s Social Principles of Human-Centric AI, and the U.K. guidance on understanding AI ethics and safety have been frontrunners in this sense; they were followed by the U.S. guidance to federal agencies on regulation of AI and an executive order on how these agencies should use AI. Most recently, the EU proposal for adoption of regulation on AI has marked the first attempt to introduce a comprehensive legislative scheme governing AI.
In exploring how to align these various policymaking efforts, we focus on the most compelling reasons for stepping up international cooperation (the “why”); the issues and policy domains that appear most ready for enhanced collaboration (the “what”); and the instruments and forums that could be leveraged to achieve meaningful results in advancing international AI standards, regulatory cooperation, and joint R&D projects to tackle global challenges (the “how”). At the end of this report, we list the topics that we propose to explore in our forthcoming group discussions….(More)”
Reboot AI with human values
Book Review by Reema Patel of “In AI We Trust: Power, Illusion and Control of Predictive Algorithms Helga Nowotny Polity (2021)”: “In the 1980s, a plaque at NASA’s Johnson Space Center in Houston, Texas, declared: “In God we trust. All others must bring data.” Helga Nowotny’s latest book, In AI We Trust, is more than a play on the first phrase in this quote attributed to statistician W. Edwards Deming. It is most occupied with the second idea.
What happens, Nowotny asks, when we deploy artificial intelligence (AI) without interrogating its effectiveness, simply trusting that it ‘works’? What happens when we fail to take a data-driven approach to things that are themselves data driven? And what about when AI is shaped and influenced by human bias? Data can be inaccurate, of poor quality or missing. And technologies are, Nowotny reminds us, “intrinsically intertwined with conscious or unconscious bias since they reflect existing inequalities and discriminatory practices in society”.
Nowotny, a founding member and former president of the European Research Council, has a track record of trenchant thought on how society should handle innovation. Here, she offers a compelling analysis of the risks and challenges of the AI systems that pervade our lives. She makes a strong case for digital humanism: “Human values and perspectives ought to be the starting point” for the design of systems that “claim to serve humanity”….(More)”.
The AI gambit: leveraging artificial intelligence to combat climate change—opportunities, challenges, and recommendations
Paper by Josh Cowls, Andreas Tsamados, Mariarosaria Taddeo & Luciano Floridi: “In this article, we analyse the role that artificial intelligence (AI) could play, and is playing, to combat global climate change. We identify two crucial opportunities that AI offers in this domain: it can help improve and expand current understanding of climate change, and it can contribute to combatting the climate crisis effectively. However, the development of AI also raises two sets of problems when considering climate change: the possible exacerbation of social and ethical challenges already associated with AI, and the contribution to climate change of the greenhouse gases emitted by training data and computation-intensive AI systems. We assess the carbon footprint of AI research, and the factors that influence AI’s greenhouse gas (GHG) emissions in this domain. We find that the carbon footprint of AI research may be significant and highlight the need for more evidence concerning the trade-off between the GHG emissions generated by AI research and the energy and resource efficiency gains that AI can offer. In light of our analysis, we argue that leveraging the opportunities offered by AI for global climate change whilst limiting its risks is a gambit which requires responsive, evidence-based, and effective governance to become a winning strategy. We conclude by identifying the European Union as being especially well-placed to play a leading role in this policy response and provide 13 recommendations that are designed to identify and harness the opportunities of AI for combatting climate change, while reducing its impact on the environment….(More)”.