Stefaan Verhulst
A guide for policy makers by the OECD: “This working paper examines how horizon scanning can help governments anticipate and respond to emerging and converging technologies. Drawing on 129 international exercises (2020–2025), it highlights the diversity of practices, from government units to international initiatives, and explores methodological advances, including AI-enabled analytics. The paper identifies key technologies such as advanced materials, quantum technologies and bioengineering, and their policy implications for security, resilience and sustainability. It also highlights challenges in interpreting early signals and the need for robust standards and international collaboration to ensure horizon scanning effectively informs STI policy and decision-making…(More)”.
Article by Nikolaj Moesgaard & Güliz Berfin Koldaş: “Addressing complex social challenges at scale requires strong, well-connected networks that can coordinate action, share learning, and adapt as conditions change. Whether in philanthropy, social investment, member alliances, or regional platforms, networks play a vital role in mobilizing resources, surfacing innovation, and supporting solutions across diverse contexts.
Yet a fundamental challenge persists: Many networks lack clear, current visibility into who their members are, what they do, and how their efforts align. Reliance on outdated directories, infrequent surveys, or anecdotal knowledge limits collaboration, progress tracking, and access to relevant opportunities. These gaps are often most acute in fast-changing or under-resourced environments, where information is fragmented or rarely updated.
In response, a growing range of networks—including grantee communities, professional alliances, funder collaboratives, and industry-wide partnerships focused on shared social or environmental goals—are beginning to adopt more dynamic, data-informed approaches. Tools such as AI-enabled analysis, automated research, and real-time feedback mechanisms are helping these groups replace static records with living, evolving views of network activity tailored to their unique data environments, geographies, and organizational types…(More)”.
Book by Burcu Baykurt: “…provides a rich ethnographic investigation into how smartness is received and negotiated in a midsize US city. Burcu Baykurt follows the work of civic entrepreneurs, local residents, and city officials in Kansas City, Missouri, where Google tested a citywide gigabit service and the local government launched a series of smart city pilot projects in transportation, public housing, and municipal services. Baykurt redefines smartness as a collective effort to spotlight a city’s enduring local problems and align solutions with the often buggy, partially developed systems offered by tech companies. She shows that success in matching civic concerns with flawed tech systems is hard-won and ambiguous, and that the techniques of data capitalism extract value from urban inequalities rather than solve them…(More)”.
Blog by Tosin Gbadegesin, Namita Datta and Manjula K. Nettikumara: “Gender data has come a long way. We can now compare women’s labor force participation across countries, track legal reforms that affect women’s work, and see how many women sit on boards or work in certain firms. Yet the uncomfortable truth is this: we are measuring women in the system far better than we are measuring whether the system is working for women.
A recently published International Finance Corporation (IFC) report, Closing the Gap: A Private Sector Data Outlook on Women’s Economic Opportunities, highlights both the progress and the problem. The report maps where gender data exists and where it falls short. The bigger message, however, is not just that we need more data. It’s that we need better measurement, one that shifts from compliance to performance, from snapshots to trajectories, and from averages to lived realities.
The gender data paradox: more indicators, less clarity
The assessment identified 20 data sources that meet minimum thresholds for transparency, comparability, and relevance to private-sector decision making. These sources provide 429 indicators, covering an average of 129 countries over roughly 18 years. That sounds like abundance.
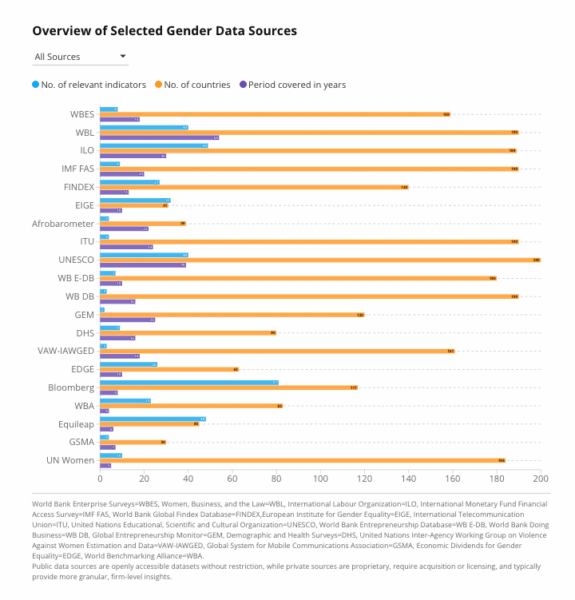
But here’s the paradox: as the number of indicators grows, actionable clarity does not always improve. Why? Because availability is not the same as adequacy. Many indicators tell us what exists (a policy, a disclosure, a headcount), but not what changes (women’s outcomes, mobility, safety, productivity, or constraints over time and the underlying social norms that shape these outcomes). And the areas that matter most for modern businesses, including supply chains, digital access, care systems, and gender-based violence affecting women’s ability to work, remain among the least measured…(More)”.
Article by Shannon Dosemagen, Gwen Ottinger: “…maintaining healthy communities requires information. To respond effectively to accidents and releases, residents and emergency responders need real-time measurements of hazardous chemicals in the air. Residents who observe soot or dust blanketing their communities need information about its chemical composition to share with their health providers. Closing the refinery in Benicia requires still more information, so the city can understand the levels of toxins left in the soil and the risks of further exposures from clean-up processes. Faced with the choice between the razing of an oil refinery and its conversion to a renewables facility, communities should be able to compare the status quo with expected emissions and safety risks for multiple future scenarios.
Creating the kind of knowledge base necessary for such consequential decisions would require long-term coordination across the many communities affected by energy infrastructure. Places like Benicia, Martinez, and Rodeo would need a place to store data about pollution before, during, and after major changes at nearby energy facilities. They would need to have a way of sharing their data and analyses with other similarly situated communities if they chose to do so, and they would need to be able to access data and analyses from other communities just as easily. Academic and nonprofit researchers with a bird’s eye view of the issues could also enhance knowledge infrastructures if they had access to data shared by communities and a way not only to disseminate their findings, but to share their methodologies for communities to adapt and deploy.
Existing data infrastructures can’t support this kind of collective learning about environmental issues. Both the technical and governance aspects of the infrastructure would need significant upgrades, and the customary models for funding science in the United States don’t offer the kinds of investment that would be necessary. Funding is typically structured around short grant cycles and discrete deliverables, making it difficult to support the long-term, shared stewardship that this infrastructure requires. Addressing these hurdles could enable creation of a robust environmental knowledge commons maintained by a plethora of users and contributors. Such a commons could ensure the continued capacity to generate new insights about the impacts of pollution and environmental change, forming a durable basis for evidence-informed public policy, whether or not the federal government continues to support environmental science. An environmental knowledge commons could, moreover, offer a model for ongoing advancement in other fields of science where traditional funding models have become precarious, even as their knowledge remains essential to public well-being…(More)”.
Report by Bronwyn Carlson and Tamika Worrell: “Artificial intelligence is increasingly embedded in everyday life in Australia, shaping communication, services, and relationships. This report presents findings from the Relational Futures project, an Indigenous led study examining how Aboriginal and Torres Strait Islander peoples are encountering and responding to AI, including generative systems, automated decision-making tools, and AI companions. The research draws on a mixed methods approach combining an online survey with 36 respondents and yarning circles with 22 participants, providing both broad and in-depth insight into Indigenous experiences of AI across community and professional contexts. This report presents the initial findings as the project continues…(More)”.
Book edited by Daryl Lim and Peter K Yu: “As artificial intelligence and big data analytics reshape economies and societies, the promise of innovation is increasingly shadowed by concerns over inclusion, equity, and global justice. This accessible, interdisciplinary volume brings together established and emerging voices from across the world to critically examine issues lying at the intersection of innovation, intellectual property, and inequality in the age of artificial intelligence and big data. Featuring empirical studies, legal analyses, policy critiques, interdisciplinary perspectives, and global insights, Inclusive Innovation in the Age of AI and Big Data underscores the tremendous impact gender, race, and other socioeconomic factors have on innovation and intellectual property ecosystems. This volume also explores structural barriers in these ecosystems, diversity initiatives in the patent area, metrics for measuring inclusivity and diversity in innovation, changes brought about by artificial intelligence and big data, and the evolution of the global innovation and intellectual property systems. In an era marked by rapid technological change, extraordinary opportunities, and deepening inequality, this volume offers carefully designed reform strategies and policy recommendations to make innovation and intellectual property ecosystems more equitable, effective, and socially responsive…(More)”.
Book by Carissa Véliz: “For thousands of years, oracles, seers, and astrologers advised leaders and commoners alike about the future. But predictions are often power plays in disguise, obfuscating accountability and stripping individuals of their agency. Today we face the same threat of powerful prophets but under a new facade: tech.
Not only do modern predictions made by tech companies advise on war, industry, and marriages, but artificial intelligence also now determines whether we can get a loan, a job, an apartment, or an organ transplant. And when we cede ground to these predictions, we lose control of our own lives.
Drawing on history’s cautionary tales and modern-day tech companies’ malfeasance—from surveillance and biased algorithms to a startling lack of accountability—Carissa Véliz demonstrates that big tech’s prophecies are just as shallow, dangerous, and unjust as their ancient counterparts’. What she uncovers in the process is chilling. Artificial intelligence is increasing risk in business and society while creating a false sense of security. In this incisive, witty, and bracingly original book, Véliz contends that the main promise of prediction is not knowledge of the future but domination over others. Powerful people use predictions to determine our future. Prophecy is an invitation to defy those orders and live life on our own terms…(More)”.
Book edited by Patrick Dunleavy and Timothy Monteath: “Open science is a set of principles and practices that aims to make research from all fields accessible to everyone for the benefit of researchers and society as a whole. Doing Open Social Science: A Guide for Researchers is the first comprehensive book setting out the principles and practices of open research, tailored specifically for those in the social science disciplines, at every career stage, offering practical advice on how to make research more transparent, trustworthy and reusable.
Divided into four parts, the book explores the core principles and philosophy of open social science. Part II addresses how to improve the reproducibility of research through open approaches, including chapters on the principles and tools of documenting research as you go and on open data practices. Part III focuses on open practices within the qualitative social sciences. Chapters examine interview-based research, case studies and fieldwork, systematic documentation analysis, archival data and the role of openness in citizen (social) science. Part IV addresses shifting research cultures, with chapters on strategies for presenting research clearly and accessibly to maximise reach and impact and on open access publishing. The book ends with a discussion of the future of open social science. Ultimately, it argues, openness as a wider cultural change can renew the social sciences and the core foundations for academic progress in more dynamic and sustainable ways…(More)”.
Paper by Nicole Czaplicki, et al: “As part of the comprehensive Construction Re-engineering Initiative at the U.S. Census Bureau, alternative data sources are being considered to supplement or replace current data collection methods. For the Survey of Construction (SOC), which measures new residential construction, this includes observing housing starts from satellite imagery in place of the current interviews for housing starts conducted by field representatives. Satellite images are obtained monthly for a subset of places in the SOC sample. Convolutional neural network models are then applied to images to predict likely new residential construction projects, with the current focus being single-family housing starts. Several post prediction processing steps are applied including exclusions based on intersections with known buildings or roads, treatments for missing data due to cloud cover, and adjustments for the length of time between consecutive images, to ultimately produce place level estimates of housing starts. These place level estimates are then combined with the existing building permit level survey data to produce estimates of West South Central division level housing starts, an experimental data product from the Census Bureau…(More)”.