, , , , and The aim of this paper is to critically explore whether crowdsourced Big Data enables an inclusive humanitarian response at times of crisis. We argue that all data, including Big Data, are socially constructed artefacts that reflect the contexts and processes of their creation. To support our argument, we qualitatively analysed the process of ‘Big Data making’ that occurred by way of crowdsourcing through open data platforms, in the context of two specific humanitarian crises, namely the 2010 earthquake in Haiti and the 2015 earthquake in Nepal. We show that the process of creating Big Data from local and global sources of knowledge entails the transformation of information as it moves from one distinct group of contributors to the next. The implication of this transformation is that locally based, affected people and often the original ‘crowd’ are excluded from the information flow, and from the interpretation process of crowdsourced crisis knowledge, as used by formal responding organizations, and are marginalized in their ability to benefit from Big Data in support of their own means. Our paper contributes a critical perspective to the debate on participatory Big Data, by explaining the process of in and exclusion during data making, towards more responsive humanitarian relief….(More)”.
Counterterrorism and Counterintelligence: Crowdsourcing Approach
Literature review by Sanket Subhash Khanwalkar: “Despite heavy investment by the United States and several other national governments, terrorism related problems are rising at an alarming rate. Lone-wolf terrorism, in particular, in the last decade, has caused 70% of all terrorism related deaths in the US and the West. This literature survey describes lone-wolf terrorism in detail to analyse its structure, characteristics, strengths and weaknesses. It also investigates crowdsourcing intelligence, as an unorthodox approach to counter lone-wolf terrorism, by reviewing its current state-of-the-art and identifying the areas for improvement….(More)”
Effect of Government Data Openness on a Knowledge-based Economy
Jae-Nam Lee, Juyeon Ham and Byounggu Choi at Procedia Computer Science: “Many governments have recently begun to adopt the concept of open innovation. However, studies on the openness of government data and its effect on the global competitiveness have not received much attention. Therefore, this study aims to investigate the effects of government data openness on a knowledge-based economy at the government level. The proposed model was analyzed using secondary data collected from three different reports. The findings indicate that government data openness positively affects the formation of knowledge bases in a country and that the level of knowledge base of a country positively affects the global competitiveness of a country….(More)”
An investigation of unpaid crowdsourcing
Chapter by Ria Mae Borromeo and Motomichi Toyama in Human-centric Computing and Information Sciences: “The continual advancement of internet technologies has led to the evolution of how individuals and organizations operate. For example, through the internet, we can now tap a remote workforce to help us accomplish certain tasks, a phenomenon called crowdsourcing. Crowdsourcing is an approach that relies on people to perform activities that are costly or time-consuming using traditional methods. Depending on the incentive given to the crowd workers, crowdsourcing can be classified as paid or unpaid. In paid crowdsourcing, the workers are incentivized financially, enabling the formation of a robust workforce, which allows fast completion of tasks. Consequently, in unpaid crowdsourcing, the lack of financial incentive potentially leads to an unpredictable workforce and indeterminable task completion time. However, since payment to workers is not necessary, it can be an economical alternative for individuals and organizations who are more concerned about the budget than the task turnaround time. In this study, we explore unpaid crowdsourcing by reviewing crowdsourcing applications where the crowd comes from a pool of volunteers. We also evaluate its performance in sentiment analysis and data extraction projects. Our findings suggest that for such tasks, unpaid crowdsourcing completes slower but yields results of similar or higher quality compared to its paid counterpart…(More)”
Exploring Online Engagement in Public Policy Consultation: The Crowd or the Few?
Helen K. Liu in Australian Journal of Public Administration: “Governments are increasingly adopting online platforms to engage the public and allow a broad and diverse group of citizens to participate in the planning of government policies. To understand the role of crowds in the online public policy process, we analyse participant contributions over time in two crowd-based policy processes, the Future Melbourne wiki and the Open Government Dialogue. Although past evaluations have shown the significance of public consultations by expanding the engaged population within a short period of time, our empirical case studies suggest that a small number of participants contribute a disproportionate share of ideas and opinions. We discuss the implications of our initial examination for the future design of engagement platforms….(More)”
5 Crowdsourced News Platforms Shaping The Future of Journalism and Reporting
Maria Krisette Capati at Crowdsourcing Week: “We are exposed to a myriad of news and updates worldwide. As the crowd becomes moreinvolved in providing information, adopting that ‘upload mindset’ coined by Will Merritt ofZooppa, access to all kinds of data is a few taps and clicks away….
Google News Lab – Better reporting and insightful storytelling
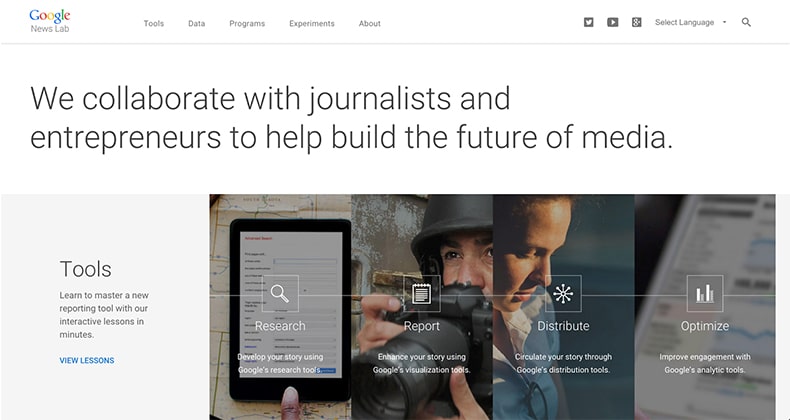
Last week, Google announced its own crowdsourced news platform dubbed News Lab as part of their efforts “to empower innovation at the intersection of technology and media.”
Scouting for real-time stories, updates, and breaking news is much easier and systematize for journalists worldwide. They can use Google’s tools for better reporting, data for insightful storytelling and programs to focus on the future of media, tackling this initiative in three ways.
“There’s a revolution in data journalism happening in newsrooms today, as more data sets and more tools for analysis are allowing journalists to create insights that were never before possible,” Google said.
Grasswire – first-hand information in real-time

The design looks bleak and simple, but the site itself is rich with content—first-hand information crowdsourced from Twitter users in real-time and verified. Austen Allred, co-founder of Grasswire was inspired to develop the platform after his “minor slipup” as the American Journalism Review (AJR) puts it, when he missed his train out of Shanghai that actually saved his life.
“The bullet train Allred was supposed to be on collided with another train in the Wenzhou area ofChina’s Zhejiang province,” AJR wrote. “Of the 1,630 passengers, 40 died, and another 210 were injured.” The accident happened in 2011. Unfortunately, the Chinese government made some cover upon the incident, which frustrated Allred in finding first-hand information.
After almost four years, Grasswire was launched, a website that collects real-time information from users for breaking news infused with crowdsourcing model afterward. “It’s since grown into a more complex interface, allowing users to curate selected news tweets by voting and verifying information with a fact-checking system,” AJR wrote, which made the verification of data open and systematized.
Rappler – Project Agos: a technology for disaster risk reduction
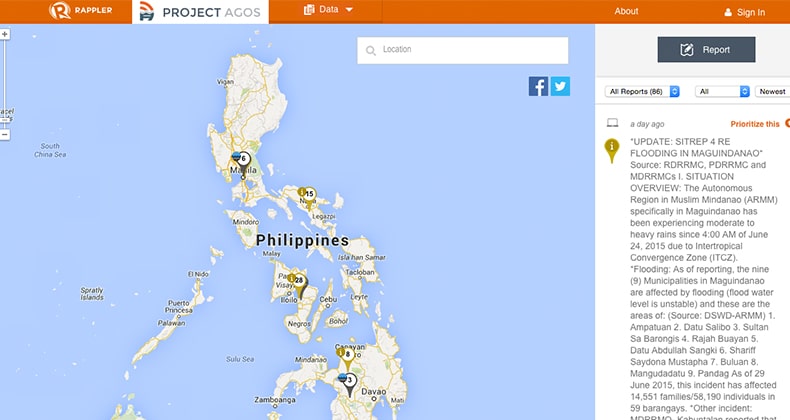
The Philippines is a favorite hub for typhoons. The aftermath of typhoon Haiyan was exceedingly disastrous. But the crowds were steadfast in uploading and sharing information and crowdsourcing became mainstream during the relief operations. Maria Ressa said that they had to educate netizens to use the appropriate hashtags for years (#nameoftyphoonPH, e.g. #YolandaPH) for typhoons to collect data on social media channels easily.
Education and preparation can mitigate the risks and save lives if we utilize the right technology and act accordingly. In her blog, After Haiyan: Crisis management and beyond, Maria wrote, “We need to educate not just the first responders and local government officials, but more importantly, the people in the path of the storms.” …
China’s CCDI app – Crowdsourcing political reports to crack down corruption practices
In China, if you want to mitigate or possible, eradicate corrupt practices, then there’s an app for that.China launched its own anti-corruption app called, Central Commission for Discipline InspectionWebsite App, allowing the public to upload text messages, photos and videos of Chinese officials’ any corrupt practices.
The platform was released by the government agency, Central Committee for Discipline Inspection.Nervous in case you’ll be tracked as a whistleblower? Interestingly, anyone can report anonymously.China Daily said, “the anti-corruption authorities received more than 1,000 public reports, and nearly70 percent were communicated via snapshots, text messages or videos uploaded,” since its released.Kenya has its own version, too, called Ushahidi using crowdmapping, and India’s I Paid a Bribe.
Newzulu – share news, publish and get paid
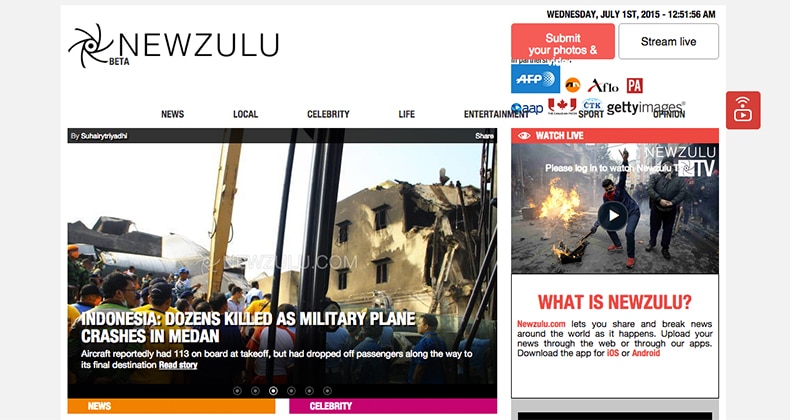
While journalists can get fresh insights from Google News Labs, the crowd can get real-time verified news from Grasswire, and CCDI is open for public, Newzulu crowdsourced news platforms doesn’t just invite the crowd to share news, they can also publish and get paid.
It’s “a community of over 150,000 professional and citizen journalists who share and break news to the world as it happens,” originally based in Sydney. Anyone can submit stories, photos, videos, and even stream live….(More)”
Crowdfunding for Sustainable Entrepreneurship and Innovation
Book edited by Walter Vassallo: “Crowdfunding for Sustainable Entrepreneurship and Innovation is a pivotal reference source for the latest scholarly research and business practices on the opportunities and benefits gained from the use of crowdfunding in modern society, discussing its socio-economic impact, in addition to its business implications. Featuring current trends and future directions for crowdfunding initiatives, this book is ideally designed for students, researchers, practitioners, entrepreneurs, and policy makers.
New financing models such as crowdfunding are democratizing access to credit, offering individuals and communities the opportunity to support, co-create, contribute and invest in public and private initiatives. This book relates to innovation in its essence to anticipate future needs and in creating new business models without losing revenue. There are tremendous unexplored opportunities in crowdsourcing and crowdfunding; two sides of the same coin that can lead to a revolution of current social and economic models. The reading of this book will provide insight on the changes taking place in crowdfunding, and offer strategic opportunities and advantages….(More)”
How Medical Crowdsourcing Empowers Patients & Doctors
Rob Stretch at Rendia: “Whether you’re a solo practitioner in a rural area, or a patient who’s bounced from doctor to doctor with adifficult–to-diagnose condition, there are many reasons why you might seek out expert medical advice from a larger group. Fortunately, in 2016, seeking feedback from other physicians or getting a second opinion is as easy as going online.
“Medical crowdsourcing” sites and apps are gathering steam, from provider-only forums likeSERMOsolves and Figure 1, to patient-focused sites like CrowdMed. They share the same mission of empowering doctors and patients, reducing misdiagnosis, and improving medicine. Is crowdsourcing the future of medicine? Read on to find out more.
Fixing misdiagnosis
An estimated 10 percent to 20 percent of medical cases are misdiagnosed, even more than drug errors and surgery on the wrong patient or body part, according to the National Center for Policy Analysis. And diagnostic errors are the leading cause of malpractice litigation. Doctors often report that with many of their patient cases, they would benefit from the support and advice of their peers.
The photo-sharing app for health professionals, Figure 1, is filling that need. Since we reported on it last year, the app has reached 1 million users and added a direct-messaging feature. The app is geared towards verified medical professionals, and goes to great lengths to protect patient privacy in keeping with HIPAAlaws. According to co-founder and CEO Gregory Levey, an average of 10,000 unique users check in toFigure 1 every hour, and medical professionals and students in 190 countries currently use the app.
Using Figure 1 to crowdsource advice from the medical community has saved at least one life. EmilyNayar, a physician assistant in rural Oklahoma and a self-proclaimed “Figure 1 addict,” told Wired magazine that because of photos she’d seen on the app, she was able to correctly diagnose a patient with shingles meningitis. Another doctor had misdiagnosed him previously, and the wrong medication could have killed him.
Collective knowledge at zero cost
In addition to serving as “virtual colleagues” for isolated medical providers, crowdsourcing forums can pool knowledge from an unprecedented number of doctors in different specialties and even countries,and can do so very quickly.
When we first reported on SERMO, the company billed itself as a “virtual doctors’ lounge.” Now, the global social network with 600,000 verified, credentialed physician members has pivoted to medical crowdsourcing with SERMOsolves, one of its most popular features, according to CEO Peter Kirk.
“Crowdsourcing patient cases through SERMOsolves is an ideal way for physicians to gain valuable information from the collective knowledge of hundreds of physicians instantly,” he said in a press release.According to SERMO, 3,500 challenging patient cases were posted in 2014, viewed 700,000 times, and received 50,000 comments. Most posted cases received responses within 1.5 hours and were resolved within a day. “We have physicians from more than 96 specialties and subspecialties posting on the platform, working together to share their valuable insights at zero cost to the healthcare system.”
While one early user of SERMO wrote on KevinMD.com that he felt the site’s potential was overshadowed by the anonymous rants and complaining, other users have noted that the medical crowdsourcing site has,like Figure 1, directly benefitted patients.
In an article on PhysiciansPractice.com, Richard Armstrong, M.D., cites the example of a family physician in Canada who posted a case of a young girl with an E. coli infection. “Physicians from around the world immediately began to comment and the recommendations resulted in a positive outcome for the patient.This instance offered cross-border learning experiences for the participating doctors, not only regarding the specific medical issue but also about how things are managed in different health systems,” wrote Dr.Armstrong.
Patients get proactive
While patients have long turned to social media to (questionably) crowdsource their medical queries, there are now more reputable sources than Facebook.
Tech entrepreneur Jared Heyman launched the health startup CrowdMed in 2013 after his sister endured a “terrible, undiagnosed medical condition that could have killed her,” he told the Wall Street Journal. She saw about 20 doctors over three years, racking up six-figure medical bills. The NIH Undiagnosed DiseaseProgram finally gave her a diagnosis: fragile X-associated primary ovarian insufficiency, a rare disease that affects just 1 in 15,000 women. A hormone patch resolved her debilitating symptoms….(More)”
How Technology Can Restore Our Trust in Democracy
Cenk Sidar in Foreign Policy: “The travails of the Arab Spring, the rise of the Islamic State, and the upsurge of right-wing populism throughout the countries of West all demonstrate a rising frustration with the liberal democratic order in the years since the 2008 financial crisis. There is a growing intellectual consensus that the world is sailing into uncharted territory: a realm marked by authoritarianism, shallow populism, and extremism.
One way to overcome this global resentment is to use the best tools we have to build a more inclusive and direct democracy. Could new technologies such as Augmented Reality (AR), Virtual Reality (VR), data analytics, crowdsourcing, and Blockchain help to restore meaningful dialogue and win back people’s hearts and minds?
Underpinning our unsettling current environment is an irony: Thanks to modern communication technology, the world is more connected than ever — but average people feel more disconnected. In the United States, polls show that trust in government is at a 50-year low. Frustrated Trump supporters and the Britons who voted for Brexit both have a sense of having “lost out” as the global elite consolidates its power and becomes less responsive to the rest of society. This is not an irrational belief: Branko Milanovic, a leading inequality scholar, has found that people in the lower and middle parts of rich countries’ income distributions have been the losers of the last 15 years of globalization.
The same 15 years have also brought astounding advances in technology, from the rise of the Internet to the growing ubiquity of smartphones. And Western society has, to some extent, struggled to find its bearings amid this transition. Militant groups seduce young people through social media. The Internet enables consumers to choose only the news that matches their preconceived beliefs, offering a bottomless well of partisan fury and conspiracy theories. Cable news airing 24/7 keeps viewers in a state of agitation. In short, communication technologies that are meant to bring us together end up dividing us instead (and not least because our politicians have chosen to game these tools for their own advantage).
It is time to make technology part of the solution. More urgently than ever, leaders, innovators, and activists need to open up the political marketplace to allow technology to realize its potential for enabling direct citizen participation. This is an ideal way to restore trust in the democratic process.
As the London School of Economics’ Mary Kaldor put it recently: “The task of global governance has to be reconceptualized to make it possible for citizens to influence the decisions that affect their lives — to reclaim substantive democracy.” One notable exception to the technological disconnect has been fundraising, as candidates have tapped into the Internet to enable millions of average voters to donate small sums. With the right vision, however, technological innovation in politics could go well beyond asking people for money….(More)”
Open Data for Developing Economies
Scan of the literature by Andrew Young, Stefaan Verhulst, and Juliet McMurren: This edition of the GovLab Selected Readings was developed as part of the Open Data for Developing Economies research project (in collaboration with WebFoundation, USAID and fhi360). Special thanks to Maurice McNaughton, Francois van Schalkwyk, Fernando Perini, Michael Canares and David Opoku for their input on an early draft. Please contact Stefaan Verhulst ([email protected]) for any additional input or suggestions.
Open data is increasingly seen as a tool for economic and social development. Across sectors and regions, policymakers, NGOs, researchers and practitioners are exploring the potential of open data to improve government effectiveness, create new economic opportunity, empower citizens and solve public problems in developing economies. Open data for development does not exist in a vacuum – rather it is a phenomenon that is relevant to and studied from different vantage points including Data4Development (D4D), Open Government, the United Nations’ Sustainable Development Goals (SDGs), and Open Development. The below-selected readings provide a view of the current research and practice on the use of open data for development and its relationship to related interventions.
Selected Reading List (in alphabetical order)
- Open Data and Open Government for Development
- Solomon Benjamin, R. Bhuvaneswari, P. Rajan, Manjunatha – Bhoomi: ‘E-Governance’, or, An Anti-Politics Machine Necessary to Globalize Bangalore? – a paper offering a critical take on digitization and transparency efforts, particularly in Bangalore.
- Rosie McGee and Duncan Edwards – Introduction: Opening Governance – Change, Continuity and Conceptual Ambiguity – an introduction to a special issue of IDS bulletin on open government for development.
- Open Data and Data 4 Development
- 3rd International Open Data Conference (IODC) – Enabling the Data Revolution: An International Open Data Roadmap – a summary report of the third International Open Data Conference offering a roadmap for leveraging open data for sustainable development.
- Martin Hilbert – Big Data for Development: A Review of Promises and Challenges – an article offering a conceptual framework on the opportunities and threats of leveraging data for international development.
- International Development Research Centre, World Wide Web Foundation, and Berkman Center at Harvard University – Fostering a Critical Development Perspective on Open Government Data – a paper assessing how the real-world impact of open data, particularly in the Global South, are or are not meeting expectations.
- Open Data for Development – Open Data for Development: Building an Inclusive Data Revolution – a report providing an overview of the Open Data for Development (OD4D) program and its early findings.
- Elizabeth Stuart, Emma Samman, William Avis, Tom Berliner – The Data Revolution: Finding the Missing Millions – a report outlining the challenge of using data for development when many people are not represented in official databases.
- United Nations Independent Expert Advisory Group on a Data Revolution for Sustainable Development – A World That Counts, Mobilizing the Data Revolution – a report examining the opportunities and risks for using data for sustainable development.
- The World Bank – Digital Dividends: World Development Report 2016 – a report on the use of digital technologies, including big and open data, to improve development efforts.
- Open Data and Open Development…
- Open Data and Development Goals
- Evangelia Berdou – Mediating Voices and Communicating Realities: Using Information Crowdsourcing Tools, Open Data Initiatives and Digital Media to Support and Protect the Vulnerable and Marginalised – a report exploring how crowdsourcing, mapping and open data can generate and publicly share information that could benefit vulnerable and marginalized communities.
- Michael Canares, Satyarupa Shekhar – Open Data and Sub-national Governments: Lessons from Developing Countries – a synthesis paper providing lessons learned regarding sub-national open data from the Open Data in Developing Countries research project.
- Tim Davies – Open Data in Developing Countries – Emerging Insights from Phase I – a report offering 15 central insights from 13 countries studied in the Exploring the Emerging Impacts of Open Data in Developing Countries research network.
- Tim Davies, Duncan Edwards – Emerging Implications of Open and Linked Data for Knowledge Sharing Development – a study and collection of case studies examining how open and linked data can benefit development.
- Tim Davies, Fernando Perini, and Jose Alonso – Researching the Emerging Impacts of Open Data – a paper providing a conceptual framework and comparative theory of change for open data, with a particular focus on developing countries.
- Elise Montano and Diogo Silva – Exploring the Emerging Impacts of Open Data in Developing Countries (ODDC): ODDC1 Follow-up Outcome Evaluation Report – a report summarizing the findings of a project on open data’s impact on governance in developing countries.
- Fiona Smith, William Gerry, Emma Truswell – Supporting Sustainable Development with Open Data – a report describing the the benefits and challenges of using open data to achieve the SDGs.
- Open Data and Developing Countries (National Case Studies)….(More)”